






首先进入jQuery下载jquery文件。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<style type="text/css">
* {
margin: 0;
padding: 0
}
div{
width: 600px;
margin: 100px auto;
border: 1px solid #000;
padding: 20px;
}
span{
margin:0px 237px;
}
textarea{
margin-left: 54px;
width: 450px;
height: 160px;
resize: none;
}
ul {
width: 433px;
padding-left: 80px;
}
ul li {
line-height: 25px;
border-bottom: 1px dashed #cccccc;
display: none;
}
</style>
<body>
<div>
<span>微博评论区</span>
<textarea class="txt" rows="40" cols="20" ></textarea>
<button class="put">发布</button>
<ul>
</ul>
</div>
<script src="jquery-3.7.1.min.js"></script>
<script>
$(function () {
$(".put").on("click", function () {
if ($(".txt").val() == "") {
alert('您没有输入内容');
return false;
} else {
let li = $("<li></li>");
li.html($(".txt").val() + "<a href='javascript:;'>删除</a>");
$("ul").prepend(li);
li.slideDown();
$(".txt").val("");
}
})
$("ul").on("click", "a", function () {
$(this).parent('li').slideUp(function () {
$(this).remove();
});
})
})
</script>
</body>
</html>
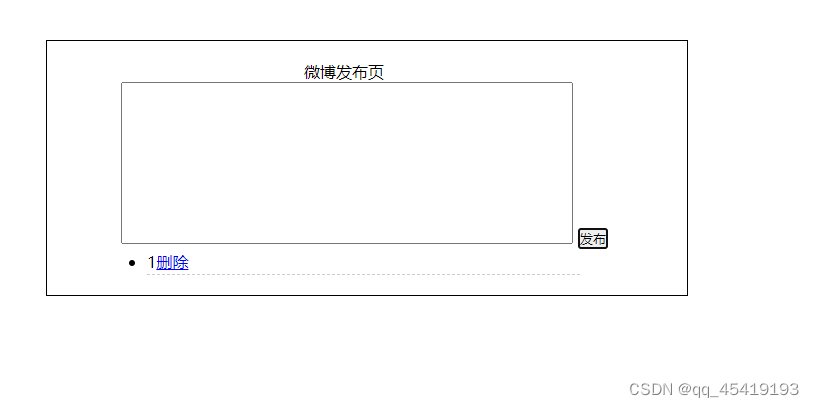
效果















 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









