







输入一个int数组和一个数,找到两数和为这个数的下标。找不到的话返回[-1,-1]。只需要找一组。
给定不同面额的硬币coins和一个总金额amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
[1,2,3,4,5] 13
3 5+5+3 = 13
当线程A执行到对象引用执行分配好的内存时,这时对象还未初始化,线程B此时调用getInstance()方法,判断引用已经不为null,因此直接返回,此时对象是半初始化状态,使用会导致异常出现。
解决该问题的方法可以使用volatile修饰成员变量instance,volatile可以通过内存屏障防止上述的指令重排序问题。
硬件层面的内存屏障分为Load Barrier 和 Store Barrier即读屏障和写屏障。
对于Load Barrier来说,在指令前插入Load Barrier,可以让高速缓存中的数据失效,强制重新从主内存加载数据。
对于Store Barrier来说,在指令后插入Store Barrier,能让写入缓存中的最新数据更新写入主内存,让其他线程可见。
下面是基于JMM内存屏障的插入策略:
1.在每个volatile写操作的前面插入一个storestore屏障。
2.在每个volatile写操作的后面插入一个storeload屏障。
3.在每个volatile读操作的后面插入一个loadload屏障。
4.在每个volatile读操作的后面插入一个loadstore屏障。
public class Solution {
/**
* @param numbers: An array of Integer
* @param target: target = numbers[index1] + numbers[index2]
* @return: [index1, index2] (index1 < index2)
*/
//想法: 先判断之前有没有数e正好等于(target-现在的数),若有,则e的下标和现在数的下标都放进数组里;没有,就把现在的数放进map里.
// 提供 int []numbers =[2,7,11,15];
// 提供 int target =9;
public int[] twoSum(int[] numbers, int target) {
//*******第一个Integer是数值,第二个Integer是下标*******这里注意,
Map<Integer,Integer> map=new HashMap<>();
//遍历数组
for (int i = 0;i < numbers.length ;i++ ) {
//前面有没有遇到一个数正好等于(traget-现在的数)
//containsKey该方法判断Map集合对象中是否包含指定的键名
if(map.containsKey(target-numbers[i])){
//若找到,数组是之前数的下标和当前的下标
return new int[] {map.get(target-numbers[i]),i};
}else{
//没找到,把当前的值放到hashMap表中
map.put(numbers[i],i);
}
}
return new int [0];
}
}
面试题目
-
算法题 * 2
-
Android的四大组件,用过哪些?
-
activity
-
一个Activity通常就是一个单独的屏幕(窗口)。
-
Activity之间通过Intent进行通信。
-
android应用中每一个Activity都必须要在AndroidManifest.xml配置文件中声明,否则系统将不识别也不执行该Activity。
-
-
service
(1) service用于在后台完成用户指定的操作。service分为两种:
-
started(启动):当应用程序组件(如activity)调用startService()方法启动服务时,服务处于started状态。
-
bound(绑定):当应用程序组件调用bindService()方法绑定到服务时,服务处于bound状态。
(2) startService()与bindService()区别:
-
started service(启动服务)是由其他组件调用startService()方法启动的,这导致服务的onStartCommand()方法被调用。当服务是started状态时,其生命周期与启动它的组件无关,并且可以在后台无限期运行,即使启动服务的组件已经被销毁。因此,服务需要在完成任务后调用stopSelf()方法停止,或者由其他组件调用stopService()方法停止。
-
使用bindService()方法启用服务,调用者与服务绑定在了一起,调用者一旦退出,服务也就终止,大有“不求同时生,必须同时死”的特点。
(3) 开发人员需要在应用程序配置文件中声明全部的service,使用标签。
(4) Service通常位于后台运行,它一般不需要与用户交互,因此Service组件没有图形用户界面。Service组件需要继承Service基类。Service组件通常用于为其他组件提供后台服务或监控其他组件的运行状态。
-
-
content provider
(1)android平台提供了Content Provider使一个应用程序的指定数据集提供给其他应用程序。其他应用可以通过ContentResolver类从该内容提供者中获取或存入数据。
(2)只有需要在多个应用程序间共享数据是才需要内容提供者。例如,通讯录数据被多个应用程序使用,且必须存储在一个内容提供者中。它的好处是统一数据访问方式。
(3)ContentProvider实现数据共享。ContentProvider用于保存和获取数据,并使其对所有应用程序可见。这是不同应用程序间共享数据的唯一方式,因为android没有提供所有应用共同访问的公共存储区。
(4)开发人员不会直接使用ContentProvider类的对象,大多数是通过ContentResolver对象实现对ContentProvider的操作。
(5)ContentProvider使用URI来唯一标识其数据集,这里的URI以content://作为前缀,表示该数据由ContentProvider来管理。
-
broadcast receiver
- 你的应用可以使用它对外部事件进行过滤,只对感兴趣的外部事件(如当电话呼入时,或者数据网络可用时)进行接收并做出响应。广播接收器没有用户界面。然而,它们可以启动一个activity或serice来响应它们收到的信息,或者用NotificationManager来通知用户。通知可以用很多种方式来吸引用户的注意力,例如闪动背灯、震动、播放声音等。一般来说是在状态栏上放一个持久的图标,用户可以打开它并获取消息。
-
-
activity的生命周期有哪些?
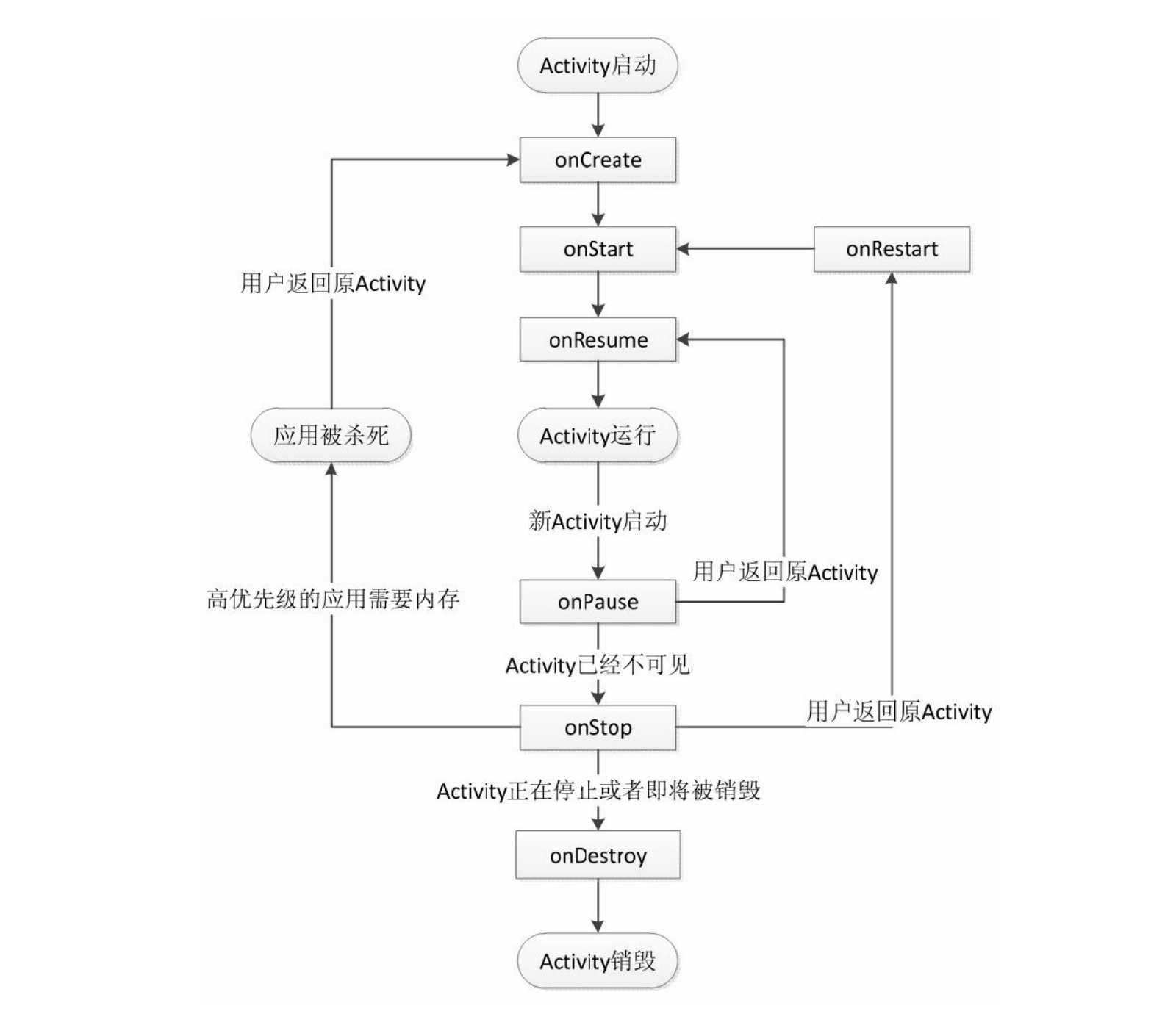
-
启动Activity:系统会先调用onCreate方法,然后调用onStart方法,最后调用onResume,Activity进入运行状态。
-
当前Activity被其他Activity覆盖其上或被锁屏:系统会调用onPause方法,暂停当前Activity的执行。
-
**当前Activity由被覆盖状态回到前台或解锁屏:**系统会调用onResume方法,再次进入运行状态。
-
当前Activity转到新的Activity界面或按Home键回到主屏,自身退居后台:系统会先调用onPause方法,然后调用onStop方法,进入停滞状态。(即后台不可见状态)
-
用户后退回到此Activity:系统会先调用onRestart方法,然后调用onStart方法,最后调用onResume方法,再次进入运行状态。
-
当前Activity处于被覆盖状态或者后台不可见状态,即第2步和第4步,系统内存不足,杀死当前Activity,而后用户退回当前Activity:再次调用onCreate方法、onStart方法、onResume方法,进入运行状态。
-
**用户退出当前Activity:**系统先调用onPause方法,然后调用onStop方法,最后调用onDestory方法,结束当前Activity。
-
-
A activity 打开 B activity,它们分别会经历哪些生命周期?
- B的launchMode为standard或者B Activity没有可复用的实例时,顺序依次为:
A.onPause -> B.onCreate -> B.onStart -> B.onResume -> A.onStop; - 当 B Activity 的 launchMode 为 singleTop 且 B Activity 已经在栈顶时(一些特殊情况如通知栏点击、连点),此时只有 B 页面自己有生命周期变化: B.onPause -> B.onNewIntent -> B.onResume
- 当 B Activity 的 launchMode 为 singleInstance ,singleTask 且对应的 B Activity 有可复用的实例时,生命周期回调是这样的: A.onPause -> B.onNewIntent -> B.onRestart -> B.onStart -> B.onResume -> A.onStop -> ( 如果 A 被移出栈的话还有一个 A.onDestory)
- B的launchMode为standard或者B Activity没有可复用的实例时,顺序依次为:
-
RecyclerView有什么特点?
- 布局更丰富: layoutmanager
- 局部刷新: notifyItemChanged
- 缓存机制: 四级缓存,缓存的是ViewHolder
-
进程和线程了解吗?(根本区别,内存分配)
-
进程是执行着的应用程序,而线程是进程内部的一个执行序列。一个进程可以有多个线程。线程又叫做轻量级进程
-
**根本区别:**进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位。( 线程是可由CPU直接运行的实体)
-
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;
而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。与进程不同的是同类的多个线程共享进程的堆和方法区资源,但每个线程有自己的程序计数器、虚拟机栈和本地方法栈,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
-
**开销:**CPU切换一个线程比切换进程开销小,创建一个线程比进程开销小
-
**所处环境:**在操作系统中能同时运行多个进程(程序);而在同一个进程中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)。
-
通信:线程之间通信更方便,同一个进程下,线程共享全局变量,静态变量等数据,进程之间的通信需要以通信的方式(IPC)进行;(但多线程程序处理好同步与互斥是个难点)
-
-
线程间的通信
- android方面:(1)Handler (2)AsyncTask机制 (3)runOnUIThread()方法
- 操作系统方面:
-
为什么子线程不能更新UI?如果在子线程中直接更新UI会发生什么情况?
-
Handler机制了解吗?
-
事件的分发机制
- dispatchTouchEvent()
- onInterceptTouchEvent()
- onTouchEvent()
-
有了解MVC架构吗?MVP架构是什么?
-
TCP的三次握手
-
对锁了解吗?有用过一些什么锁吗?(这里我答的是synchronized)
-
volatile关键字了解吗?它保证了什么特性?用什么方式禁止指令重排的吗?
-
堆和栈有什么特性?
-
栈和队列有什么特性?
-
代码考核
- 要注意面试官出的题目,我这次面试的时候没有注意返回值类型!!!
- map的常用方法我记错了
- 这里我当时写错了(找一组和找很多组)
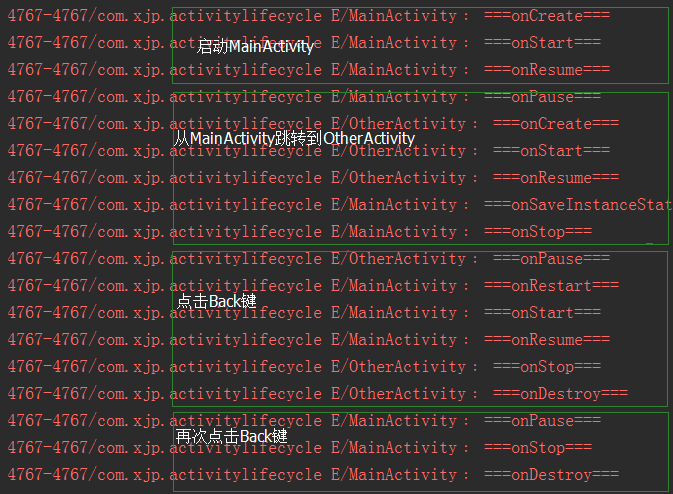
8 为什么子线程不能更新UI?
android.view.ViewRootImpl$CalledFromWrongThreadException: Only the original thread that created a view hierarchy can touch its views.
at android.view.**ViewRootImpl.checkThread(**ViewRootImpl.java:6581)
at android.view.ViewRootImpl.requestLayout(ViewRootImpl.java:924)
-
当访问UI时,
ViewRootImpl会调用checkThread方法去检查当前访问UI的线程是哪个,如果不是主线程,就会抛出异常:Only the original thread that created a view hierarchy can touch its views。异常是从android.view.ViewRootImpl的checkThread方法抛出的。而ViewRootImpl是接口ViewRoot的实现类,其控制着
View的测量、绘制等操作
每一次访问UI,Android都会重新绘制View
@Override
public void requestLayout() {
if (!mHandlingLayoutInLayoutRequest) {
checkThread();
mLayoutRequested=true;
scheduleTraversals();
}
}
- ViewRootImpl对象会调用**checkThread()**方法来检查当前线程
- 然后调用scheduleTraversals()方法,scheduleTraversals,字面理解就是线程遍历循环:
- 在线程遍历的时候会调用**doTraversal()**方法
- 在**doTraversal()**方法里面调用了performTraversals()方法,View的绘制过程就是从performTraversals方法开始的
但其实在子线程中是可以更新UI的
子线程可以在ViewRootImpl还没有被创建之前更新UI;
创建一个空白的Activity,在其xml布局文件中放一个空白TextView,在onCreate中创建一个子线程,并在该子线程中更新textView的内容,是可以成功的。
但如果我们先让子线程休眠100ms再更新UI,那就会报错,抛出异常
【问题】为什么休眠十秒后就会抛出异常
在执行onCreate方法的那个时候ViewRootImpl对象还没创建,无法去检查当前线程。
休眠10s后,ViewRootImpl对象已经创建完成,可以检查当前线程是否是主线程。
ViewRootImpl的创建是在onResume方法回调之后,而我们一开篇是在onCreate方法中创建子线程并访问UI,在那个时刻,ViewRootImpl还没有来得及创建,无法检测当前线程是否是UI线程,所以程序没有崩溃。而之后修改了程序,让线程休眠了100毫秒后再更新UI,程序就崩了。很明显在这100毫秒内ViewRootImpl已经完成了创建,并能执行checkThread方法检查当前访问并更新UI的线程是不是UI线程。
同样的,我们还可以猜测,在onStart方法和onResume方法里面创建子线程并访问更新UI,同样是可以运行成功的。
Android的UI访问是没有加锁的,多个线程可以同时访问更新操作同一个UI控件。也就是说访问UI的时候,android系统当中的控件都不是线程安全的,这将导致在多线程模式下,当多个线程共同访问更新操作同一个UI控件时容易发生不可控的错误,而这是致命的。所以Android中规定只能在UI线程中访问UI,这相当于从另一个角度给Android的UI访问加上锁,一个伪锁。
-
为什么子线程不能更新UI?
- android系统当中的控件都不是线程安全的,这将导致在多线程模式下,当多个线程共同访问更新操作同一个UI控件时容易发生不可控的错误,而这是致命的。所以Android中规定只能在UI线程中访问UI,这相当于从另一个角度给Android的UI访问加上锁,一个伪锁。
-
但其实在子线程中是可以更新UI的。
-
子线程可以在
ViewRootImpl还没有被创建之前更新UI;(什么时候可以更新UI) -
ViewRootImpl是什么
- ViewRootImpl是接口ViewRoot的实现类,是
View的根类,其控制着View的测量、绘制等操作。每一次访问UI,Android都会重新绘制View,就需要创建ViewRootImpl
- ViewRootImpl是接口ViewRoot的实现类,是
-
ViewRootImpl什么时候被创建?
- ViewRootImpl的创建是在onResume方法回调之后,在ViewRootImpl创建完成之后,能执行checkThread方法检查当前访问并更新UI的线程是不是UI线程。
- 从
Activity启动过程中寻找源码,通过分析可以查看ActivityThread.java源码,并找到handleResumeActivity方法 - ViewRootImpl是在WindowManagerGlobal的addView方法中创建的
-
同样的,我们还可以猜测,在onCreate()方法、onStart方法和onResume方法里面创建子线程并访问更新UI,同样是可以运行成功的。前提是ViewRootImpl还没有被创建
9 Handler机制
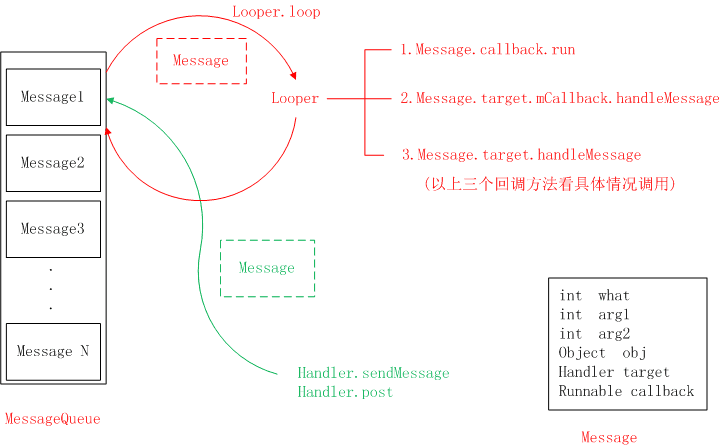
Handler机制主要是用作线程间通信,尤其是主线程和子线程之间的通信。
Handler机制里面涉及到四个对象:Handler,message、MessageQueue、Loo per
- **Handler:消息的处理者,**负责将Message添加到消息队列以及对消息队列中的Message进行处理。
- 主线程创建一个Handler对象,重写handleMessage()方法
- 在子线程中创建一个Message对象,保存要传递的消息。通过Handler的sendMessage()方法发出消息
- Handler.sendMessage: 把消息加入到主线程的MessageQueue中,主线程中的Looper从MessageQueue中取出消息,调用Message.target.handleMessage方法
- Handler.post: 基于Handler.sendMessage,把消息加入到主线程的MessageQueue中,主线程中的Looper从MessageQueue中取出消息,调用Message.callback.run方法
- 这条message被添加到MessageQueue中等待处理。MessageQueue: 消息队列,用来存放通过Handler发布的消息,按照先进先出执行。
- Looper (消息队列管家):Looper发现有新消息到来时,就会处理这个消息。会调用Looper.loop()方法来
- 一个线程最多只有一个Looper对象。当没有Looper对象时,去创建一个Looper
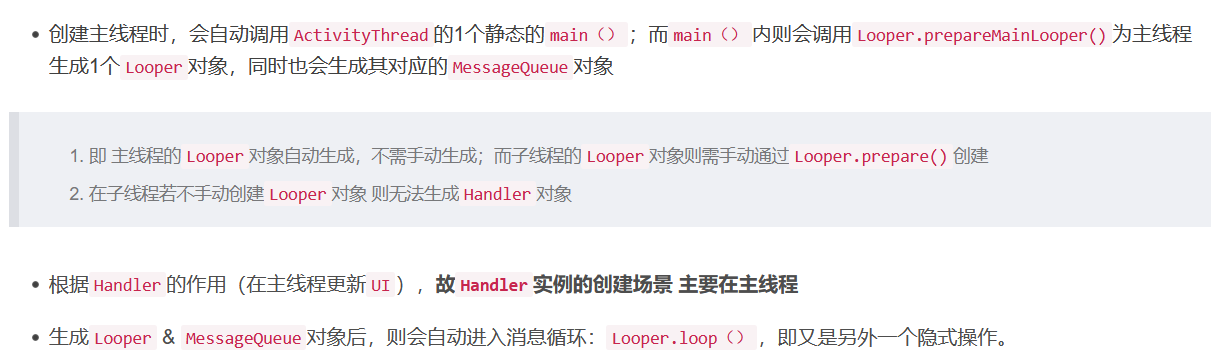
- **在Looper的构造方法里面,会创建消息队列MessageQueue,**并让它供Looper持有,因为一个线程最多只有一个Looper对象,所以一个线程最多也只有一个消息队列。然后再把当前线程赋值给mThread。
创建Handler还是需要调用Looper.prepare的,我们平常在主线程不需要手动调用,是因为系统在启动App时,就帮我们调用了。并且还需要调用Looper.loop方法
所以使用Handler通信之前需要有以下三步:
-
调用Looper.prepare()
- 所以Looper.prepare()的作用主要有以下三点
- 创建Looper对象 & 存放在ThreadLocal变量中
- 创建MessageQueue对象,并让Looper对象持有(在Looper的构造方法里面,会创建消息队列MessageQueue,并让它供Looper持有)
- 让Looper对象持有当前线程
- 所以Looper.prepare()的作用主要有以下三点
-
创建Handler对象
-
在Handler的构造方法里面:得到当前线程调用sThreadLocal.set保存的Looper对象,让Handler持有它。接下来就会判断得到的Looper对象是否为空,如果为空,就会抛出异常(得到当前线程的Looper对象,并判断是否为空)
-
让创建的Handler对象持有Looper、MessageQueue、Callback的引用
-
当创建
Handler对象时,则通过 构造方法 自动关联当前线程的Looper对象 & 对应的消息队列对象(MessageQueue),从而 自动绑定了 实现创建Handler对象操作的线程
-
-
调用Looper.loop()
- 从当前线程的MessageQueue从不断取出Message,并调用其相关的回调方法。
-
判断了当前线程是否有Looper,然后得到当前线程的MessageQueue
-
(死循环)不断调用MessageQueue的next方法取出MessageQueue中的Message,注意,当MessageQueue中没有消息时,next方法会阻塞,导致当前线程挂起
-
拿到Message以后,会调用它的target的dispatchMessage方法,这个target其实就是发送消息时用到的Handler。并调用其相关的回调方法(拿到Message之后,调用相关的回调方法)
sendMessage的全部过程,其实就是把Message加入到MessageQueue的合适位置
然后,会判断when,它是表示延迟的时间,我们这里没有延时,所以为0,满足if条件。把消息插入到消息队列的头部。如果when不为0,则需要把消息加入到消息队列的合适位置。
- Handler.sendMessage: 把消息加入到主线程的MessageQueue中,主线程中的Looper从MessageQueue中取出消息,调用Message.target.handleMessage方法
- Handler.post: 基于Handler.sendMessage,把消息加入到主线程的MessageQueue中,主线程中的Looper从MessageQueue中取出消息,调用Message.callback.run方法
- Activity.runOnUiThread: 基于Handler.post
- View.post: 基于Handler.post
所以,以上子线程更新主线程UI的所有方式,都是依赖于Handler机制。
消息的延时处理
https://www.jianshu.com/p/edf4f5ee0057/
MessageQueue是按照Message触发时间的先后顺序排列的,队头的消息是将要最早触发的消息。排在越前面的越早触发,那我们现在应该了解到了,这个所谓的延时呢,不是延时发送消息,而是延时去处理消息,我们在发消息都是马上插入到消息队列当中。
可以看到,在这个方法内,如果头部的这个Message是有延迟而且延迟时间没到的(now < msg.when),会计算一下时间(保存为变量nextPollTimeoutMillis),然后在循环开始的时候判断如果这个Message有延迟,就调用nativePollOnce(ptr, nextPollTimeoutMillis)进行阻塞。nativePollOnce()的作用类似与object.wait(),只不过是使用了Native的方法对这个线程精确时间的唤醒。
1、postDelay()一个10秒钟的Runnable A、消息进队,MessageQueue调用nativePollOnce()阻塞,Looper阻塞;
2、紧接着post()一个Runnable B、消息进队,判断现在A时间还没到、正在阻塞,把B插入消息队列的头部(A的前面),然后调用nativeWake()方法唤醒线程;
3、MessageQueue.next()方法被唤醒后,重新开始读取消息链表,第一个消息B无延时,直接返回给Looper;
4、Looper处理完这个消息再次调用next()方法,MessageQueue继续读取消息链表,第二个消息A还没到时间,计算一下剩余时间(假如还剩9秒)继续调用nativePollOnce()阻塞;直到阻塞时间到或者下一次有Message进队;
(1) Handler引起内存泄漏
在Java中,非静态内部类和匿名类都会持有当前类的外部引用。
而在这里Handler是非静态内部类,所以次MHandler持有当前Activity的隐式引用,如果Handler没有被释放,其持有的外部引用也就是Activity也不可能被释放。
发送的消息中包含有 Handler 实例的引用,只有消息被处理后,handler 的引用才会释放,如果 Activity 已经销毁,但是Looper 中还有消息没有处理完,handler 就不能释放。如果handler 不是 Activity 的静态内部类,那么 handler 就会持有 Activity 的引用,导致该 Activity 不能正常回收,这样就造成了内存泄露。
(2)Handler内存泄漏解决方法
- 使用静态内部类并继承Handler(或者也可以单独存放成一个类文件)
- 因为静态的内部类不会持有外部类的引用,所以不会导致外部类实例的内存泄露。当你需要在静态内部类中调用外部的Activity时,我们可以使用弱引用来处理
- 使用弱引用解决静态内部类访问外部类
- 创建一个静态的Handler内部类,然后对Handler持有的外部对象使用弱引用, 这样在回收时JVM可以销毁Handler持有的对象。但就算如此,在退出MainActivity后,Looper线程的消息队列中还是可能会有待处理的消息,因此建议在Activity销毁时,移除消息队列中的消息。
10 ThreadLocal类
ThreadLocal类提供【线程局部变量】,它通常是希望将状态与线程关联的静态字段。即ThreadLocal提供了线程间数据隔离的功能
1. ThreadLocal底层实现
ThreadLocal 底层是通过 ThreadLocalMap 这个静态内部类来存储数据的,ThreadLocalMap 就是一个键值对的 Map,它的底层是 Entry 对象数组,Entry 对象中存放的键是 ThreadLocal 的弱引用对象,值是 Object 类型的具体存储内容。
2. ThreadLocal为什么要使用弱引用
ThreadLocalMap中的Key是ThreadLocal的弱引用,如果使用弱引用,拿指向ThreadLocal对象的引用有两个:存在栈中的ThreadLocal 强引用 和 ThreadLocalMap中Entry的key的弱引用。一旦存在栈中的ThreadLocal 强引用被回收,则指向ThreadLocal对象的就只有 ThreadLocalMap中Entry的key的弱引用,那么在下次GC的时候,这个ThreadLocal对象就会回收。
如果使用强引用,那么在存在栈中的ThreadLocal 强引用 被回收后,ThreadLocal对象会因为和Entry存在强应用无法被回收,造成内存泄漏。
但是ThreadLocal对象作为ThreadLocalMap的一个key,它被回收了,而它对应的value没有被回收(),会造成内存泄漏。
3. ThreadLocal内存泄漏及解决方法
一个Thread维持着一个ThreadLocalMap对象,而该Map对象的key又由提供该value的ThreadLocal对象弱引用提供,所以这就有这种情况:
如果ThreadLocal不设为static的,由于Thread的生命周期不可预知,这就导致了当系统gc时将会回收它,而ThreadLocal对象被回收了,此时它对应key必定为null,这就导致了该key对应的value拿不出来了,而value之前被Thread所引用,所以就存在key为null、value存在强引用导致这个Entry回收不了,从而导致内存泄露。
所以避免内存泄露的方法
- 当 线程的某个ThreadLocal使用完了,就手动remove掉该ThreadLocal的值,这样Entry就能够在系统gc的时候正常回收,而关于ThreadLocalMap的回收,会在当前Thread销毁之后进行回收。
- remove()方法:将与当前线程关联的ThreadLocal值删除
- 对于ThreadLocal 变量要设为private static静态的
- 这样的话ThreadLocal的生命周期就更长了,由于一直存在ThreadLocal的强引用,所以ThreadLocal也就不会回收,也就能保证任何时候根据ThreadLocal的弱引用访问Entry的value值,然后remove它,可以防止内存泄漏。
4. 扩容机制
ThreadLocalMap 的初始容量是 16:
下面聊一下 ThreadLocalMap 的扩容机制 ,它在扩容前有两个判断的步骤,都满足后才会进行最终扩容:
- ThreadLocalMap#set(ThreadLocal<?> key, Object value) 方法中可能会触发启发式清理,在清理无效 Entry 对象后,如果数组长度大于等于数组定义长度的 2/3,则首先进行 rehash;
// rehash 条件
private void setThreshold(int len) {
threshold = len * 2 / 3;
}
1234
- rehash 会触发一次全量清理,如果数组长度大于等于数组定义长度的 1/2,则进行 resize(扩容);
// 扩容条件
private void rehash() {
expungeStaleEntries();
// Use lower threshold for doubling to avoid hysteresis
if (size >= threshold - threshold / 4)
resize();
}
12345678
- 进行扩容时,Entry 数组为扩容为 原来的2倍 ,重新计算 key 的散列值,如果遇到 key 为 NULL 的情况,会将其 value 也置为 NULL,帮助虚拟机进行GC。
11.volatile关键字
volatile关键字了解吗?它保证了什么特性?用什么方式禁止指令重排的吗?
-
保证线程可见性(多线程环境下保证内存可见性)
- 线程修改后的共享变量值能够及时刷新,从工作内存中刷新回主内存;
- 其它线程能够及时的把共享变量的值从主内存中更新到自己的工作内存中;
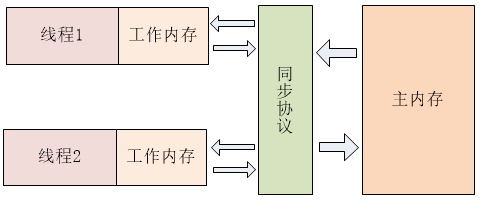
- Java 内存模型规定,对于多个线程共享的变量,存储在主内存当中,每个线程都有自己独立的工作内存,并且线程只能访问自己的工作内存,不可以访问其它线程的工作内存。工作内存中保存了主内存中共享变量的副本,线程要操作这些共享变量,只能通过操作工作内存中的副本来实现,操作完毕之后再同步回到主内存当中,其 JVM 模型大致如下图。
-
禁止指令重排序优化(多线程模式下禁止指令重排序优化)
-
哪条代码需要指令重排?
instance = new instance();
-
使用了volatile关键字之后,重排序被禁止,所有的写操作(write)都发生在读操作(read)之前。
-
用什么方式禁止指令重排的吗?
内存屏障:
-
读屏障(Load Barrier):在读指令前插入Load Barrier,可以让高速缓存中的数据失效,强制重新从主内存加载数据,保证读取的是最新数据。
-
写屏障(Store Barrier):在写指令后插入Store Barrier,能让写入缓存中的最新数据更新写入主内存,保证写入的数据立刻对其他线程可见。
- 在工作内存中,每次使用V(volatile变量)前都必须先从主内存刷新最新的值,用于保证能看见其他线程对变量V所做的修改。
- 在工作内存中,每次修改V后都必须立刻同步回主内存中,用于保证其他线程可以看到自己对变量V所做的修改。
12. 堆和栈有什么特性?
13. 栈和队列有什么特性?
下面的算法题是自己额外添加,非面试内容
相同点
(1)都是线性结构。
(1)插入操作都是限定在表尾进行。
(3)都可以通过顺序结构和链式结构实现。
(4)插入与删除的时间复杂度都是O(1),在空间复杂度上两者也一样。
(5)多链栈和多链队列的管理模式可以相同。
1. 栈和队列的区别
- 队列先进先出,栈先进后出
- 对插入和删除操作的"限定"
- 栈是限定只能在表的一端进行插入和删除操作的线性表
- 队列是限定只能在表的一端进行插入和在另一端进行删除操作的线性表。
- 线性表允许在表内任一位置进行插入和删除
- 遍历数据速度不同
- 栈只能从头部取数据,也就最先放入的需要遍历整个栈最后才能取出来,而且在遍历数据的时候还得为数据开辟临时空间,保持数据在遍历前的一致性
- 队列则不同,它基于地址指针进行遍历,而且可以从头或尾部开始遍历,但不能同时遍历,无需开辟临时空间,因为在遍历的过程中不影响数据结构,速度要快的多
2. 用两个stack实现queue
https://leetcode-cn.com/problems/implement-queue-using-stacks-lcci/
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )

class CQueue {
private Stack<Integer> stack1;// 用于加入队尾操作
private Stack<Integer> stack2;// 用来将元素倒叙,从而实现删除队首操作
public CQueue() {
stack1 = new Stack<>();
stack2 = new Stack<>();
}
/*
//也可以用两个LinkedList来模拟队列
private LinkedList<Integer> stack1, stack2;
public CQueue() {
stack1 = new LinkedList<Integer>();
stack2 = new LinkedList<Integer>();
} */
public void appendTail(int value) {
stack1.push(value);
}
public int deletedHead(){
if(!stack2.isEmpty()){
return stack2.pop();
} else {
while(!stack1.isEmpty()) {
stack2.push(stack1.pop())
}
return stack2.isEmpty() ? -1: stack2.pop();
}
}
/** Get the front element. */
public int peek() {
if(!stack2.isEmpty()) {
return stack2.peek();
} else {
if(stack1.isEmpty()) {
return -1;
} else {
while(!stack1.isEmpty()) {
stack2.push(stack1.pop());
}
return stack2.peek();
}
}
}
/** Returns whether the queue is empty. */
public boolean empty() {
return stack1.isEmpty() && stack2.isEmpty();
}
}
---
class CQueue {
LinkedList<Integer> A, B;
public CQueue() {
A = new LinkedList<Integer>();
B = new LinkedList<Integer>();
}
public void appendTail(int value) {
A.addLast(value);
}
public int deleteHead() {
if(!B.isEmpty()) return B.removeLast();
if(A.isEmpty()) return -1;
while(!A.isEmpty())
B.addLast(A.removeLast());
return B.removeLast();
}
}
3. 两个队列实现stack
思路
- 假设有两个队列Q1和Q2,当二者都为空时,入栈操作可以用入队操作来模拟,
- 可以随便选一个空队列,假设选Q1进行入栈操作,现在假设a,b,c依次入栈了(即依次进入队列Q1),
- 这时如果想模拟出栈操作,则需要将c出栈,因为在栈顶,这时候可以考虑用空队列Q2,将a,b依次从Q1中出队,
- 而后进入队列Q2,将Q1的最后一个元素c出队即可,此时Q1变为了空队列,Q2中有两个元素,队头元素为a,队尾元素为b,
- 接下来如果再执行入栈操作,则需要将元素进入到Q1和Q2中的非空队列,即进入Q2队列,出栈的话,就跟前面的一样,
- 将Q2除最后一个元素外全部出队,并依次进入队列Q1,再将Q2的最后一个元素出队即可。
public class QueueToStack{//如果要实现添加任意类型的栈,就使用泛型QueueToStack<T>,然后将所有int(Integer)改成T
Queue<Integer> queueA, queueB;
public QueueToStack {
queueA = new LinkedList<>();
queueB = new LinkedList<>();
}
public void push(int value) {
if(queueA.isEmpty() && queueB.isEmpty()){
queueA.add(value);
} else if (queueA.isEmpty() && !queueB.isEmpty()) {
queueA.add(value);
} else {
queueB.add(value);
}
}
public int pop() {
if(queueA.isEmpty() && queueB.isEmpty()) {
return -1;//return null;
}
int result = -1;
if (queueA.size()==0&&queueB.size()!=0){
while (queueB.size()>0){
result = queueB.poll();
if (queueB.size()!=0){
queueA.add(result);
}
}
}else if (queueA.size()!=0&&queueB.size()==0){
while (queueA.size()>0){
result = queueA.poll();
if (queueA.size()!=0){
queueB.add(result);
}
}
}
return result;
}
}
https://leetcode-cn.com/problems/min-stack/
https://leetcode-cn.com/problems/min-stack-lcci/ 栈的最小值
https://leetcode-cn.com/problems/dui-lie-de-zui-da-zhi-lcof/ 队列的最大值
14. 动态规划
下面的算法题是自己额外添加,非面试内容
步骤:
-
定义数组或者变量保存历史记录,避免重复计算,一般在程序中用dp[]定义,定义数组元素或者变量的含义。
-
找到数组元素之间的关系
-
找到计算的起点和值。找到第一项,第二项等
1. 最小路径和:
求从(0, 0 ) 到 (m, n)
//dp[m][n] = Math.min (dp[m - 1][n], dp[m][n - 1]) + dp[m][n];
public int minPathSum(int[][] grid) {
if(grid == null || grid.length == 0 || grid[0].length == 0) return 0;
int m = grid.length;
int n = grid[0].length;
for(int i = 0; i < m; i++) {
for(int j= 0; j < n; j++){
if(i != 0 && j != 0) {
grid[i][j] =Math.min( grid[i - 1][j] , grid[i][j - 1]) + grid[i][j];
} else if(i == 0) {
grid[i][j] = grid[i][j - 1] + grid[i][j];
} else if (j == 0){
grid[i][j] = grid[i - 1][j] + grid[i][j];
} else continue;
}
}
return grid[m - 1][n - 1];
}
2. 硬币兑换
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
public int coinChange(int[] coin, int amount) {
if(amount < 0) return -1;
if(amout == 0) return 0;
int[] dp = new int[amount + 1];
//填充dp数组,用一个一定大于兑换硬币数的值即可
Arrays.fill(dp, amount + 1);
dp[0] = 0;
for(int i = 1; i <= amount; i++) {
for(int coin: coins) {
if(i - coin >= 0) dp[i] = Math.min(dp[i], dp[i - coin] + 1);
}
}
//判断是否能兑换
return dp[amount] > amount ? -1: dp[amount]
}
3. 买卖股票的最佳时机
/*允许买卖1次*/
class Solution {
public int maxProfit(int[] prices) {
if(prices == null || prices.length == 0) return 0;
int min = Integer.MAX_VALUE;
int res = 0;
//第i天的最大利润 = Max(第i-1天的最大利润, 第i天价格 - 之前的最小值)
//如果是(第i-1天的最大利润),说明当天价格下跌
//如果是(第i天价格 - 之前的最小值),说明当天价格上涨
for(int price: price) {
min = Math.min(min, price);
res = Math.max(res, price - min);
}
return res;
}
}
public int maxProfit(int[] prices) {
if (prices.length < 2) return 0; // 没有卖出的可能性
// 定义状态,第i天卖出的最大收益
int[] dp = new int[prices.length];
dp[0] = 0; // 初始边界
int cost = prices[0]; // 成本
for (int i = 1; i < prices.length; i++) {
dp[i] = Math.max(dp[i - 1], prices[i] - cost);
// 选择较小的成本买入
cost = Math.min(cost, prices[i]);
}
return dp[prices.length - 1];
}
-----
/*允许买卖多次*/
//找到价格上涨的天数,然后加起来就可以了
class Solution {
public int maxProfit(int[] prices) {
int tmp = 0;
int res = 0;
for(int i = 1; i < prices.length; i++) {
tmp = prices[i] - prices[i - 1];
if(tmp > 0) {
res = res + tmp;
}
}
return res;
}
}
4. 连续子数组的最大和

dp[i] = Math.max (dp[i - 1], 0) + nums[i];
- dp[i - 1] > 0:dp[i] = dp[i - 1] + nums[i] (要加上去)
- dp[i - 1] < 0:dp[i] = nums[i] (对最大值无用,不要加上去)
初始状态:dp[0] = nums[0];
因为要求的是最大值,所以要用一个变量res存储遍历过程中产生的最大值
class Solution {
public int maxSubArray(int[] nums) {
if(nums.length == 0) return 0;
if(nums.length == 1) return nums[0];
int res = nums[0];
for(int i = 1; i < nums.length; i++) {
nums[i] = nums[i] + Math.max(nums[i - 1], 0);
res = Math.max(res, nums[i]);
}
return res;
}
}
15. HashMap
看美团复盘
16 Top K问题
注意找前 K 大/前 K 小问题不需要对整个数组进行 O(NlogN) 的排序!
例如本题,直接通过快排切分排好第 K 小的数(下标为 K-1),那么它左边的数就是比它小的另外 K-1 个数啦~
Arrays的copyOf()方法传回的数组是新的数组对象,改变传回数组中的元素值,不会影响原来的数组。
copyOf()的第二个自变量指定要建立的新数组长度,如果新数组的长度超过原数组的长度,则保留数组默认值
class Solution {
public int[] getLeastNumbers(int[] arr, int k) {
if(k == 0 || arr.length == 0) return new int[0];
return quickSort(arr, 0, arr.length - 1, k - 1);
}
int[] quickSort(int[] arr, int left, int right, int k) {
int pivot = partition(arr, left, right);
if(pivot == k) return Arrays.copyOf(arr, pivot + 1);
else if(pivot > k) {
return quickSort(arr, left, pivot - 1, k);
} else {
return quickSort(arr, pivot + 1, right, k);
}
}
int partition(int[] arr, int left, int right) {
int pivot = arr[left];
while(left < right) {
while(left < right && arr[right] >= pivot) {
right--;
}
arr[left] = arr[right];
while(left < right && arr[left] <= pivot) {
left++;
}
arr[right] = arr[left];
}
arr[left] = pivot;
return left;
}
}
17. 相交链表
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode curA = headA;
ListNode curB = headB;
while(curA != curB) {
curA = curA != null ? curA.next: headB;
curB = curB != null ? curB.next: headA;
}
return curA;
}
}
最后一道算法: [剑指 Offer 38. 字符串的排列 - 力扣(LeetCode) (leetcode-cn.com)](javascript:void(0)😉
算法题: [230. 二叉搜索树中第K小的元素 - 力扣(LeetCode) (leetcode-cn.com)](javascript:void(0)😉
*
-
Definition for singly-linked list.
-
public class ListNode {
-
int val; -
ListNode next; -
ListNode(int x) { -
val = x; -
next = null; -
} -
}
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode curA = headA;
ListNode curB = headB;while(curA != curB) { curA = curA != null ? curA.next: headB; curB = curB != null ? curB.next: headA; } return curA;}
}
---
最后一道[算法](https://www.nowcoder.com/jump/super-jump/word?word=算法): [剑指 Offer 38. 字符串的排列 - 力扣(LeetCode) (leetcode-cn.com)](javascript:void(0);)
[算法题](https://www.nowcoder.com/jump/super-jump/word?word=算法题): [230. 二叉搜索树中第K小的元素 - 力扣(LeetCode) (leetcode-cn.com)](javascript:void(0);)















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









