







 本文详细介绍了如何在Windows 10环境中配置Anaconda和PaddleOCR,包括创建虚拟环境、安装特定版本的paddlepaddle和相关依赖,如paddlehub和Shapely。通过实例展示了如何使用PaddleOCR进行图像中文文字识别,适合初学者参考。
本文详细介绍了如何在Windows 10环境中配置Anaconda和PaddleOCR,包括创建虚拟环境、安装特定版本的paddlepaddle和相关依赖,如paddlehub和Shapely。通过实例展示了如何使用PaddleOCR进行图像中文文字识别,适合初学者参考。
PS:本文主要用于自我整理总结,涉及代码已成功在我电脑上运行,如果恰好帮到各位,不甚荣幸。
配置环境
配置
Win10
Anaconda3-5.0.0-Windows-x86_64(对应python3.6)
环境
第一步:安装虚拟环境
打开Anaconda Prompt,输入conda create -n test python=3.6,创建虚拟环境
(虽然我看GitHub中的PaddleOCR配置要求是python3.7+,但是我用3.6也可以跑起来)
第二步:安装paddle环境
在命令提示符中,进入虚拟环境activate test
然后进入paddle官网,找到安装命令
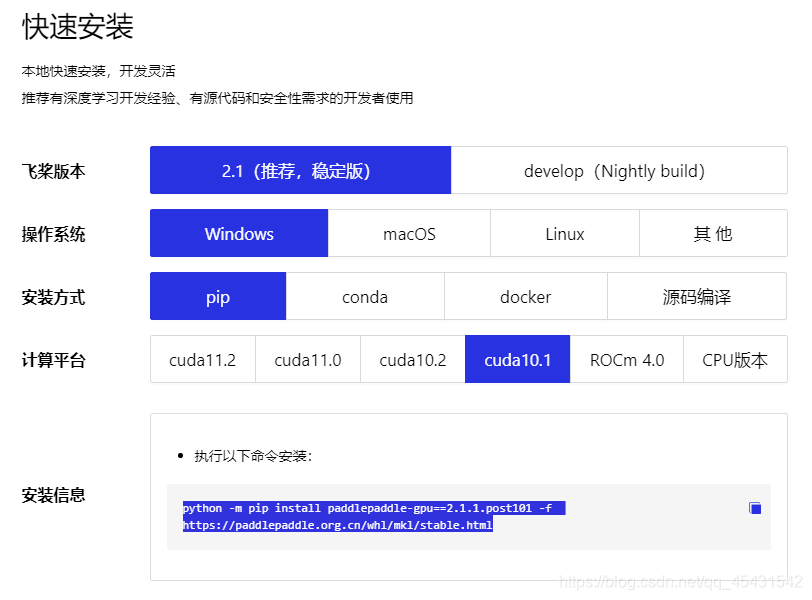
python -m pip install paddlepaddle-gpu==2.1.1.post101 -f https://paddlepaddle.org.cn/whl/mkl/stable.html
然后在安装几个需要用到的wheel
①
pip install paddlehub
②
pip install pyclipper
③
还有一个库Shapely安装后,运行还是出现问题

解决方法是:
不能简单的pip install,而是要选择对应的单独下载下来再安装,我选择的是Shapely‑1.7.1‑cp36‑cp36m‑win_amd64.whl
下载地址是https://link.csdn.net/?target=https%3A%2F%2Fwww.lfd.uci.edu%2F~gohlke%2Fpythonlibs%2F%23shapely

都安装完成后,就可以在此环境下运行代码了。
运行
import cv2
import glob
import paddlehub as hub
path = r'dataset\*.jpg' # 图片存放地址
outpath = r'result' # 结果存放地址
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile") # 加载移动端预训练模型
# ocr = hub.Module(name="chinese_ocr_db_crnn_server") # 服务端可以加载大模型,效果更好
for jpgfile in glob.glob(path):
np_images = [cv2.imread(jpgfile)]
results = ocr.recognize_text(
images=np_images, # 图片数据,ndarray.shape 为 [H, W, C],BGR格式
use_gpu=False, # 是否使用 GPU。否即False,是即请先设置CUDA_VISIBLE_DEVICES环境变量
output_dir=outpath, # 图片的保存路径
visualization=True, # 是否将识别结果保存为图片文件
box_thresh=0.5, # 检测文本框置信度的阈值
text_thresh=0.5) # 识别中文文本置信度的阈值
# print(results)
for result in results:
data = result['data']
for infomation in data:
print('text: ', infomation['text'], '\nconfidence: ', infomation['confidence'], '\ntext_box_position: ', infomation['text_box_position'])
结果展示:

参考
①https://blog.csdn.net/qq_44486439/article/details/109698115?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-4&spm=1001.2101.3001.4242
②https://blog.csdn.net/jialibang/article/details/107762921
更新
2021/07/29
检测图像时遇到这个报错:
AttributeError: ‘NoneType’ object has no attribute ‘copy’
解决方案:点击这里


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









