






左表
CREATE TABLE `branch` (
`id` varchar(36) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT 'id',
`sort` int(3) NOT NULL COMMENT '单位排序',
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '所属单位名称',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '所属单位表' ROW_FORMAT = Dynamic;
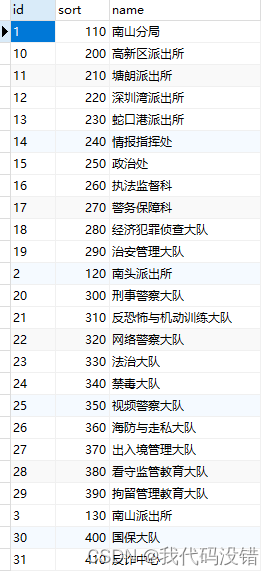
右表
CREATE TABLE `letter_data` (
`id` bigint(36) NOT NULL AUTO_INCREMENT COMMENT 'id,后端生成',
`source` int(2) NOT NULL COMMENT '信件来源',
`number` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '信件编号',
`day` varchar(128) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '来件日期',
`letter_type` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT '' COMMENT '信件类别',
`branch_id` varchar(150) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT '' COMMENT '责任单位',
`create_time` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0) COMMENT '创建时间',
`update_time` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0) ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE,
INDEX `branch_id_index`(`branch_id`) USING BTREE,
INDEX `source_index`(`source`) USING BTREE,
INDEX `day_index`(`day`) USING BTREE,
INDEX `index_Source`(`source`) USING BTREE,
INDEX `index_LetterType`(`letter_type`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8574042 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '信件详情表' ROW_FORMAT = Dynamic;
当你需要查询letter_data中branch_id中的数量并通过branch表连接查询,
查询语句
SELECT DISTINCT
b.name ,
count(*) AS count
FROM
branch AS b
LEFT JOIN letter_data AS ld ON ld.branch_id = b.id
where 1=1
and ld.`day` between '2023-03-04 00:00:00' and '2023-03-04 12:00:00'
GROUP BY
b.name
ORDER BY
count DESC,b.name DESC
查询出来的视图
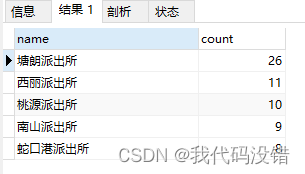
这种left join on后的where条件会使原本在on之后查询左表的字段筛选掉,从而即使左表的字段所count的值为null也不显示出来
解决的办法有三种:
第一种
将左连接表后的where条件加到on后面,使得不筛掉左表的值
SELECT DISTINCT
b.name ,
count(branch_id) AS count
FROM
branch AS b
LEFT JOIN letter_data AS ld ON ld.branch_id = b.id and ld.`day` between '2023-03-04 00:00:00' and '2023-03-04 12:00:00'
GROUP BY
b.name
ORDER BY
count DESC,b.name DESC
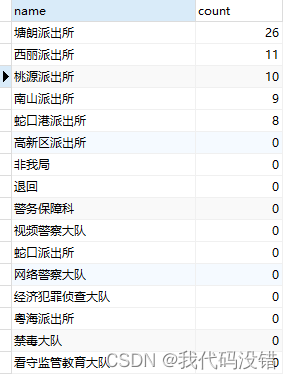
第二种
在where条件后加 or branch_id is null,为的是显示右表没有数据的字段也显示出来,在count函数中的括号里面填branch_id字段,也就是count(branch_id)
SELECT DISTINCT
b.name ,
count(branch_id) AS count
FROM
branch AS b
LEFT JOIN letter_data AS ld ON ld.branch_id = b.id
where 1=1 and ld.`day` between '2023-03-04 00:00:00' and '2023-03-04 12:00:00'
or branch_id is null
GROUP BY
b.name
ORDER BY
count DESC,b.name DESC
第三种
通过后端去筛选,将右表branch_id没有的数据设为0并加入到列表。
**BranchRankingListVo.java**
@Data
public class BranchRankingListVo {
@ApiModelProperty(value = "责任单位")
private String name;
private Integer count;
}
**BranchEntity.java**
@Data
@NoArgsConstructor
@AllArgsConstructor
@TableName("branch")
@ApiModel(value="Branch对象", description="所属单位表")
public class BranchEntity {
@ApiModelProperty(value = "id")
@TableField("id")
private String id;
@ApiModelProperty(value = "单位排序")
@TableField("sort")
private Integer sort;
@ApiModelProperty(value = "所属单位名称")
@TableField("name")
private String name;
}
实现方法
-
调用letterDataMapper的getBranchRankinglist方法获取时间范围内的责任单位排名列表,保存在BranchRankinglist变量中。
-
调用branchMapper的getBranches方法获取所有的责任单位列表,保存在branches变量中。
-
对于每个责任单位,遍历BranchRankinglist列表,查找是否存在该责任单位的排名信息。如果存在,则不做任何操作;如果不存在,则新建一个BranchRankingListVo对象,设置其名称为该责任单位的名称,设置其数量为0,最后将其添加到BranchRankinglist列表中。
-
循环结束后,BranchRankinglist列表中将包含所有时间范围内出现过的责任单位的排名信息,并且可能会包含一些数量为0的责任单位信息。
List<BranchRankingListVo> BranchRankinglist = letterDataMapper.getBranchRankinglist(startDate, endDate);
// 获取责任单位列表
List<BranchEntity> branches = branchMapper.getBranches();
branches.forEach(f ->{
boolean tempFlag = true;
for (BranchRankingListVo branchRankingListVo : BranchRankinglist) {
if (f.getName().equals(branchRankingListVo.getName())) {
tempFlag = false ;
break;
}
}
if (tempFlag){
BranchRankingListVo temp = new BranchRankingListVo();
temp.setName(f.getName());
temp.setCount(0);
BranchRankinglist.add(temp);
}
});
















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











