






Python数据容器
列表(list)
元组(tuple)
字符串(str)
集合(set)
字典(dict)
一、列表(list)
1.列表的定义
list = [元素1,元素2...]
2.列表中的元素类型没有限制,可以不同,也可以嵌套
比如:my_list = ["test",666,True]
3.列表的下标索引
(1)正序取索引


(2)倒叙取索引


4.列表中的方法(增删改查)

具体代码示例如下:
my_list = ["tangbb", "kanyy"]
# 查询 语法:list.index(元素)
item = my_list.index("tangbb")
print(item)
# 修改 修改特定位置的元素值 语法:list[下标] = 值
my_list[0] = "tangyc"
print(my_list[0])
# 插入 在指定位置插入元素 语法:list.insert(下标,元素)
my_list.insert(1, "tangyc")
print(my_list)
# 追加 将元素追加到列表尾部 语法:list.appent(元素)
my_list.append("kyy")
print(my_list)
# 批量追加 语法:list.extend(其他数据容器)
my_list_2 = ["kyy", "tbb"]
my_list.extend(my_list_2)
print(my_list)
#删除 语法:1. del list[下标] 2. list.pop(下标) 3. list.remove(元素) 【此方法如果有多个元素从前往后值删除第一个查到元素】
my_list = ["tangbb", "kanyy","kyy","kyy"]
del my_list[0]
print(my_list)
my_list.pop(0)
print(my_list)
my_list.remove("kyy")
print(my_list)
# 清空 语法:list.clear()
my_list.clear()
print(my_list)
# 统计元素在列表中的数据 语法:list.count(元素)
my_list = ["tangbb", "kanyy","kyy","kyy"]
num = my_list.count("kyy")
print(num)
# 统计列表中的元素个数 语法:len(列表)
my_list_length = len(my_list)
print(my_list_length)5.列表的遍历
(1)while循环

(2)for循环

二、元祖(tuple)
1.元祖
元祖的大部分特性都与列表类似,但是元祖一旦被定义 内容不可变 ,有个特例,如果元祖中嵌套了list,list的元素时可以改的。
2.元组中的方法
"""
元祖一旦被定义 内容不可变
但是,如果元祖中嵌套了list,list的元素时可以改的
"""
# 元祖的定义
my_tuple = ("tangbb", 111, True)
my_tuple2 = ()
my_tuple3 = tuple()
# 查询 指定位置元素
item = my_tuple[0]
print(item)
# 查询 指定元素位置
index = my_tuple.index("tangbb")
print(index)
# 查询 指定元素数量
count = my_tuple.count("tangbb")
print(count)
# 查询 元素元素个数
length = len(my_tuple)
print(length)
# 元祖的遍历 while
index = 0
while index < len(my_tuple):
print(f"元祖中元素有:{my_tuple[index]}")
index += 1
# 元祖的遍历 for
for item in my_tuple:
print(f"元祖中元素有:{item}")三、字符串(str)
1.定义
字符串本质是存放字符的数据容器
2.字符串中的方法
"""
字符串是存放字符的数据容器
"""
my_str = "tangbingbing love kanyangyang"
# 通过下标索引取值
val1 = my_str[0]
val2 = my_str[1]
print(f"字符串中元素{val1},{val2}")
# index方法 返回指定字符的下标
val3 = my_str.index("k")
print(val3)
# replace方法
new_str = my_str.replace("e", "o")
print(new_str)
# split 方法
new_str_1 = my_str.split("love")
print(new_str_1)
# 输出结果 ['tangbingbing ', ' kanyangyang']
# strip 方法 (不传参数会把头尾空格去除,传参数会剔除头尾包含参数的元素,比如传"12" 会剔除头尾的1,2字符)
test_str = " 12test21 "
test_str_12 = "12test21"
test_str_1 = test_str.strip()
test_str_2 = test_str_12.strip("12")
print(test_str_1)
print(test_str_2)
# 输出结果:
# 12test21
# test
# 统计字符串中某字符出现的次数
count = my_str.count("y")
print(count)
# 统计字符串的长度
length = len(my_str)
print(length)
四、集合(set)
1.集合的定义
列表使用:[]
元组使用:()
字符串使用:""
集合使用:{}2.集合的特点
去重、无序、可修改、不支持下标索引访问
3.集合中的方法

"""
列表使用:[]
元组使用:()
字符串使用:""
集合使用:{}
"""
# 集合的定义
my_set = {"tangbb", "tangbb", "kanyy", "kanyy"}
print(my_set)
# 添加元素 add
my_set.add("tangyc")
my_set.add("kanqz")
print(my_set)
# 移除元素 remove
my_set.remove("kanqz")
print(my_set)
# 随机取出一个元素 pop
item = my_set.pop()
print(item)
# 清空集合 clear
my_set.clear()
print(my_set)
# 取两个集合的差集(原有集合不变) difference
set1 = {1, 2, 3}
set2 = {1, 5, 6}
# 取出set1中有的但是set2中没有的
set3 = set1.difference(set2)
print(set3)
print(set1)
print(set2)
# 消除两个集合的差集 difference_update
set1 = {1, 2, 3}
set2 = {1, 5, 6}
# 在set1内,删除和set2相同的元素。结果set1被修改,set2不变
set1.difference_update(set2)
print(set1)
print(set2)
# 2个集合合并 union
set1 = {1, 2, 3}
set2 = {1, 5, 6}
set3 = set1.union(set2)
print(set3)
# 统计集合的元素数量 len
length = len(set3)
print(length)
4.集合的遍历
# 集合的遍历 (集合不支持下标索引,不能用while循环)
for item in set3:
print(item)五、字典(dict)
1.字典的定义

2.字典中的方法

"""
字典
"""
# 字典的定义
my_dict = {"tangbb": 88, "kanyy": 99, "tangyc": 100}
# 字典的取值
score = my_dict["tangbb"]
print(score)
# 字典新增/修改元素 (key存在即修改,不存在即新增)
my_dict["zhangs"] = 66
print(my_dict)
# 字典删除 pop(元素) 取出元素拿到对应的值,并且从字典中删除
score = my_dict.pop("zhangs")
print(my_dict)
# 清空
my_dict.clear()
# 获取全部key
my_dict = {"tangbb": 88, "kanyy": 99, "tangyc": 100}
keys = my_dict.keys()
print(keys)
# 遍历字典
# 方式一:通过获取到字典的keys,进行遍历
for item in keys:
val = my_dict[item]
print(f"key:{item},value:{val}")
# 方式二:直接遍历字典 (每次取出的元素都是key,实际和上面的是一样的,只是更加简单了)
for key in my_dict:
val = my_dict[key]
print(f"key:{key},value:{val}")
# 统计字典的元素数量
length = len(my_dict)
print(length)
序列
1.序列的概念:
序列是指:内容连续、有序,可使用下标索引的一类数据容器。
列表、元祖、字符串,均可以看作序列。
2.序列的常用操作-切片
(1) 切片定义:
从一个序列中取出一个子序列。此操作不会影响序列本身,它会得到一个新序列。
(2)语法:(起始下标、结束下标都可以为空,默认表示从头和结尾)
序列[起始下标:结束下标:步长]

# 对list进行切片 从1开始4结束步长1
my_list = [1, 2, 3, 4, 5]
new_list = my_list[1:4:1]
print(new_list)
# 输出:[2, 3, 4]
# 对tuple进行切片 从头开始,到最后结束,步长1
my_tuple = (1, 2, 3, 4, 5, 6)
new_tuple = my_tuple[::1]
print(new_tuple)
# 输出:(1, 2, 3, 4, 5, 6)
# 对str进行切片 从头开始,到最后结束,步长2
my_str = "always online"
new_str = my_str[::2]
print(new_str)
# 输出:awy nie
数据容器的通用操作
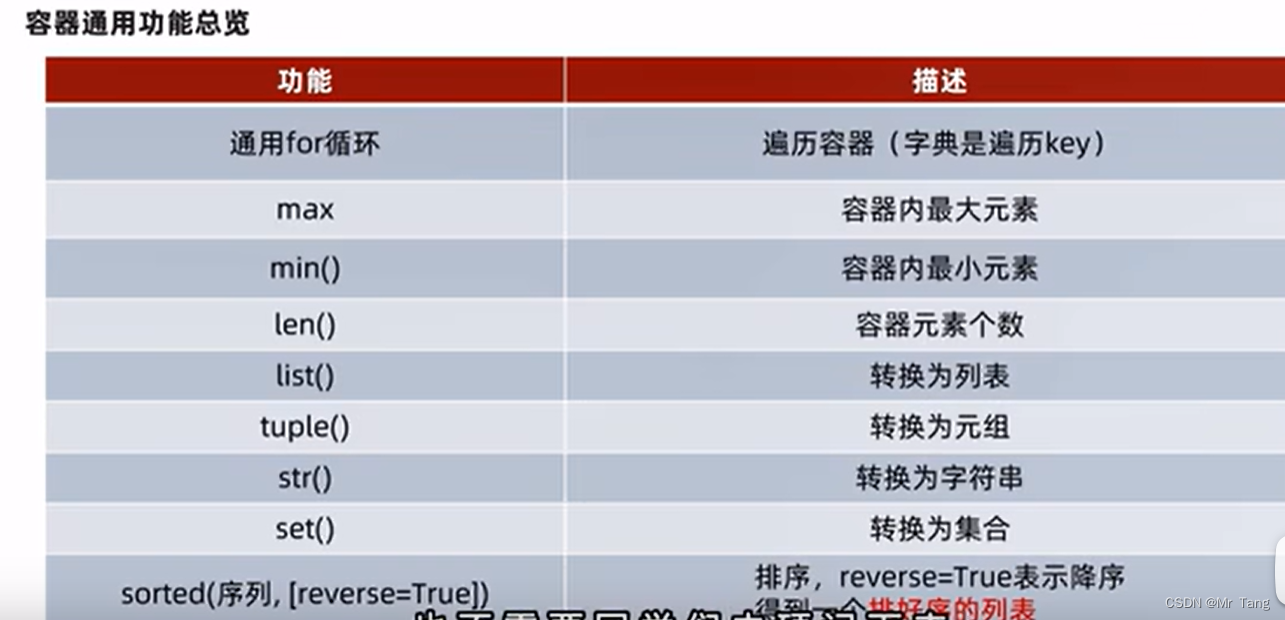
1.for循环
2.len、max、min

3.容器转换

4.排序


















 1694
1694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











