






模型名称INGRAM
代码:GitHub - bdi-lab/InGram: InGram: Inductive Knowledge Graph Embedding via Relation Graphs (ICML 2023)
注:我太懒了,有些不想手打,一些插图直接用组会汇报PPT和OneNote笔记的了,但大多都可以复制。
摘要
归纳知识图谱补全被认为是预测在训练过程中未观察到的新实体之间缺失的三联体的任务。虽然大多数归纳知识图谱补全方法假设所有实体都可以是新的,但它们不允许在推理时出现新的关系。这个限制禁止现有的方法适当地处理现实世界的知识图谱,其中新的实体伴随着新的关系。在本文中,我们提出了一种归纳知识图谱嵌入方法INGRAM,它可以在推理时生成新关系和新实体的嵌入。给定一个知识图谱,我们将关系图定义为由关系和它们之间的亲和权值组成的加权图。在关系图和原始知识图谱的基础上,INGRAM学习如何利用注意机制聚合相邻嵌入来生成关系嵌入和实体嵌入。实验结果表明,在不同的归纳学习场景下,INGRAM优于14种不同的最先进的方法。
一、研究现状和目的
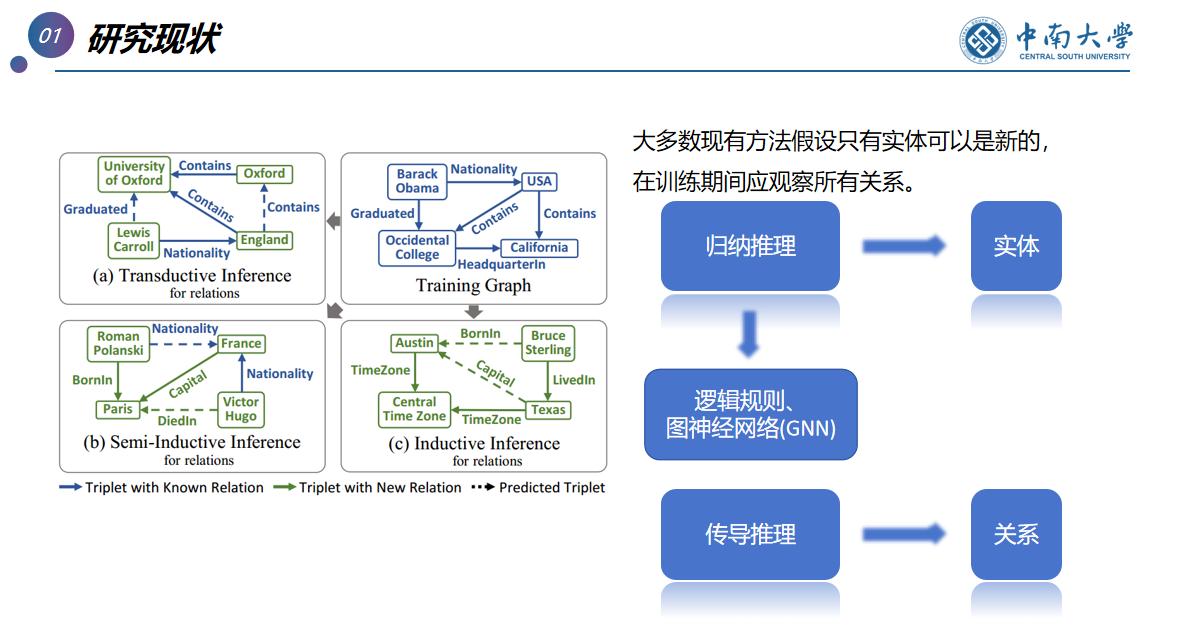
对实体,归纳推理
对关系,传导推理
目的:归纳知识图谱嵌入---------->知识图谱补全
二、相关知识
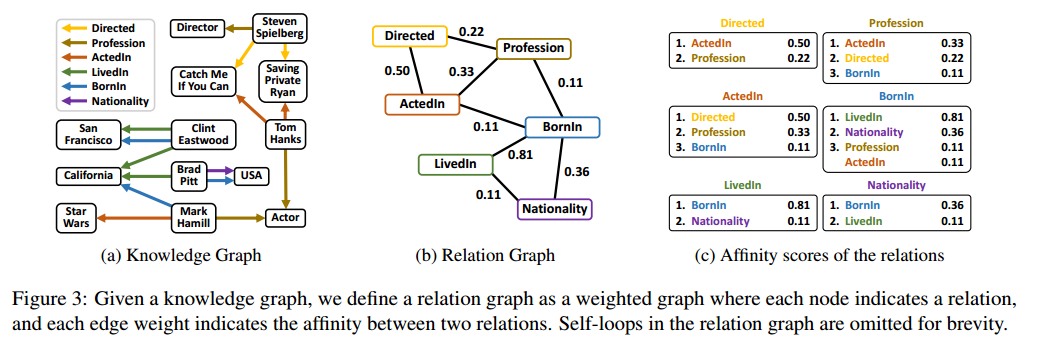
1、关系图:由关系和它们之间的亲和权值组成的加权图。(图的一种形式,其中节点表示实体,边表示实体之间的关系,边上还可以有权重,用于表示关系的强度或重要性)
2、关系间的亲和权值:用于量化两个实体(节点)之间关系强度的数值。
3、加权图:边上带有权重(weight)的图,图的形式可以是无向图或有向图,权重可以用于表示边的强度、距离、成本、容量等。
4、注意力机制:在处理某个数据点(如词或像素)时,根据其重要性对其他相关数据点进行加权,从而集中关注最相关的信息,从而提高模型的性能。
5、嵌入:将知识图谱中的节点(实体)和边(关系)映射到低维向量空间中,嵌入不仅能捕捉实体和关系的语义信息,还能使复杂的图结构变得易于操作和分析。
6、聚合:对每个节点,根据邻居节点的嵌入和对应的注意力权重进行加权求和,从而得到该节点的新嵌入。
7、嵌入对知识图谱补全的作用:
(1)嵌入技术通过将知识图谱中的实体和关系映射到低维向量空间中,捕捉了其语义和结构特征,使得模型能够进行高效的计算和推理,这种向量表示使得知识图谱补全任务变得可行和高效。
- 语义相似性:相似的实体(如两个相似的药物)会被映射到相近的向量。
- 关系依赖性:特定关系(如"治疗"关系)会对应特定的向量变换。
(2)在嵌入空间中,向量运算(如向量加法、向量乘法等)能够高效地表示和操作实体和关系。这种简单的向量运算能够快速计算出潜在的关系和实体,从而高效地进行知识图谱补全。
8、传导推理:在给定的特定数据集上进行推理和预测,它不试图从训练数据中抽象出一个普遍适用的模型,而是直接在训练数据和测试数据的特定实例上进行推理。(知识图谱中假定在训练中观察到所有的实体和关系)
9、半归纳推理:介于传导推理(transductive inference)和归纳推理(inductive inference)之间,它在模型训练和推理时,部分利用了测试数据的信息,同时也具备一定的泛化能力。半归纳推理结合了两种推理方法的优点,适用于一些特定的应用场景。
10、归纳推理:从训练数据中学习一个普遍适用的模型,并将其应用到新的、未见过的数据上,模型在训练过程中不使用任何测试数据的信息,只依赖于训练数据进行学习。
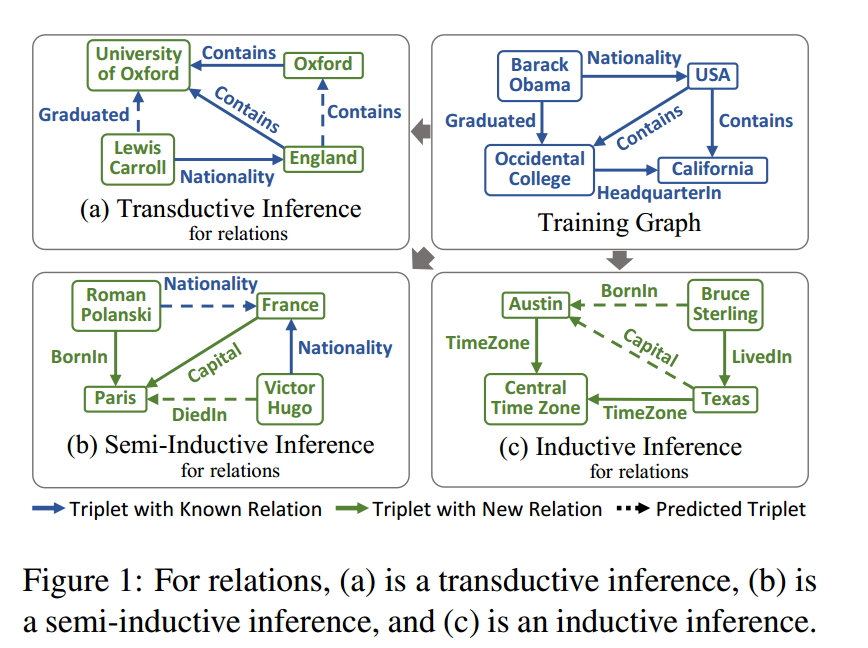
三、核心思想——关系图
关系图中,一个节点就是一个关系,边权值表示关系之间的亲和力。
将关系图定义为一个加权图,其中每个节点对应一个关系,每条边的权重表示两个关系之间的亲疏关系。为了简单起见,在图中省略了关系图中的反向关系和自循环。
本文通过考虑两个关系之间共享多少个实体以及它们共享同一个实体的频率来衡量两个关系之间的亲和性。
以下为亲和性计算方法:

四、模型概述
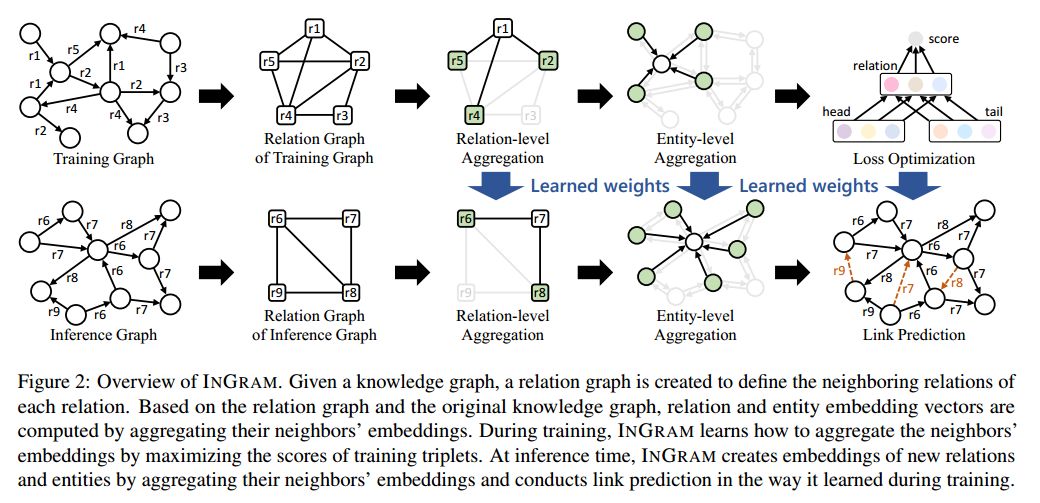
模型步骤流程:
1、定义关系图
2、利用注意力机制,根据相邻节点的重要性权重聚合嵌入向量
3、通过实体级别的聚合来表示实体
4、关系-实体交互的建模,进行聚合后的优化训练,提高可信度评分
五、模型详解
(一)定义关系图
具体定义和计算亲和度过程如“核心思想”所示
一旦定义了关系图,就可以为每个关系指定相邻关系。在给定关系图和原始知识图谱的情况下,关系和实体的嵌入向量通过基于注意力的相邻嵌入聚合(利用注意力机制,根据相邻节点的重要性权重聚合邻居的嵌入向量。重要性权重通过注意力机制计算,表示邻居节点对目标节点的影响程度)来计算。聚合过程经过优化,以最大化训练知识图谱中三元组的可信度评分。INGRAM在训练过程中学习的是如何聚合相邻嵌入以生成关系和实体嵌入。在推理阶段,INGRAM通过基于推理知识图谱计算的新关系图和在训练期间学习的注意力权重,聚合相邻的嵌入生成新的关系和实体嵌入。
(二)通过基于关系图的聚合来更新关系表示向量
利用注意力机制,根据相邻节点的重要性权重聚合嵌入向量。本文通过聚合自己和相邻关系的表示向量来更新每个关系的表示。
通过知识图谱定义关系图A,可以用A来指定每个关系的相邻关系。本文通过聚合自己和相邻关系的表示向量来更新每个关系的表示。具体来说,定义前向传播如下:
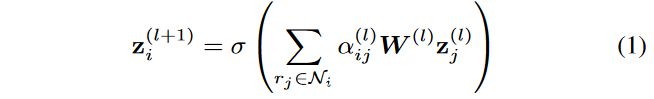
因为是关系图,所以节点z是关系表示向量。

其中的注意力值定义为:
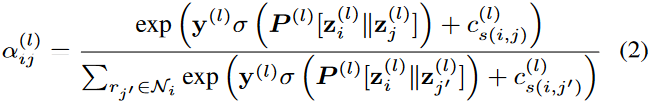
用于加权邻居节点 𝑗对节点 𝑖的影响。

分子:节点i和邻居节点j的加权注意力分数
分母:节点i和所有邻居节点的加权注意力分数之和
(三)通过实体级别的聚合来表示实体
首先,为了得到实体的自循环的注意权重,计算与实体相邻的关系表示向量的平均:
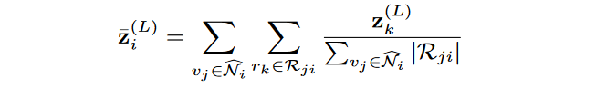

z是实体对自己的聚合表示嵌入,分子部分是关系rk的嵌入表示,分母是从所有邻居节点vj到实体 i 的关系数的总和,确保每个关系表示被平均化处理并进行归一化。
然后通过以下方式更新实体表示向量:


上式中,前面自循环项,后面邻居节点聚合项。
其中,注意力系数定义为:
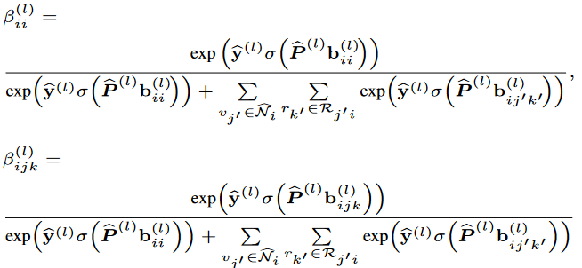
注意力系数: βii是自我表示的特征向量,P是权重矩阵,y是另一个权重向量,分子计算了自我表示的注意力得分,分母包含自我表示的得分和所有邻居节点的得分之和,βijk同理。
(四)关系-实体交互的建模
为了模拟关系和实体嵌入之间的相互作用,本文使用了DistMult的一个变种,通过以下方式定义评分函数:
![]()
W权重矩阵,通过将关系 rk的嵌入向量zk乘以权重矩阵 W ,得到一个新的关系加权向量。
DistMult 是一种用于知识图谱嵌入的模型f(h,r,t)=h ⊤diag(r)t,简洁而有效,用于知识图谱中实体和关系的表示学习,该模型的主要思想是使用矩阵乘法来捕捉实体和关系之间的相互作用。
基于边际的排序损失定义为:
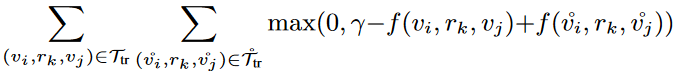
公式作用是通过最小化损失函数,使得正三元组得分要比负三元组得分至少高r,如果正比负明显高r,则损失为0,说明已经区分很好了;否则损失为正,需要调整权重矩阵和嵌入,使得正三元组评分更高。
六、实验
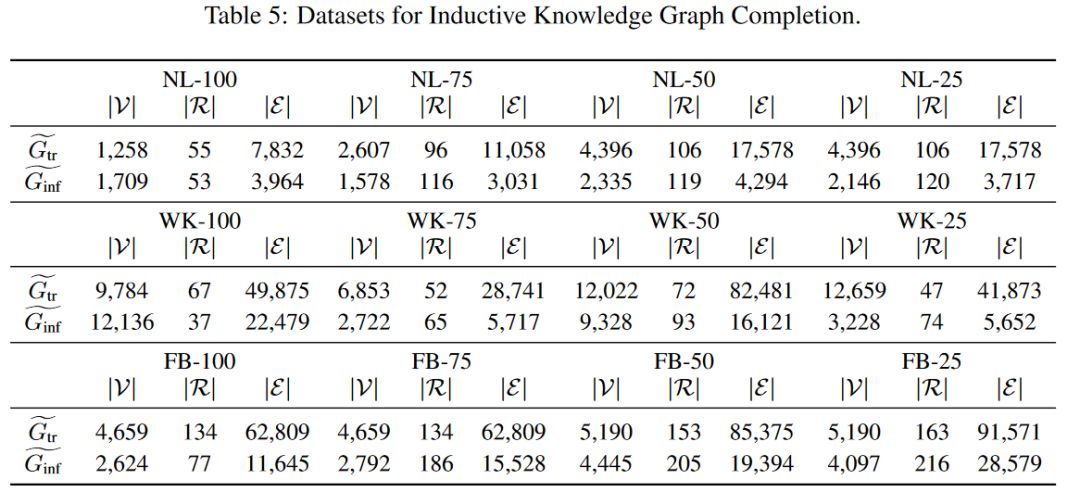
(一)数据集
使用三个基准(NELL995、Wikidata68K、FB15K237)创建了12个数据集。对于每个基准,通过改变具有新关系的三元组的百分比来创建四个数据集: 100%,75%,50%和25%。
(二)实验结果
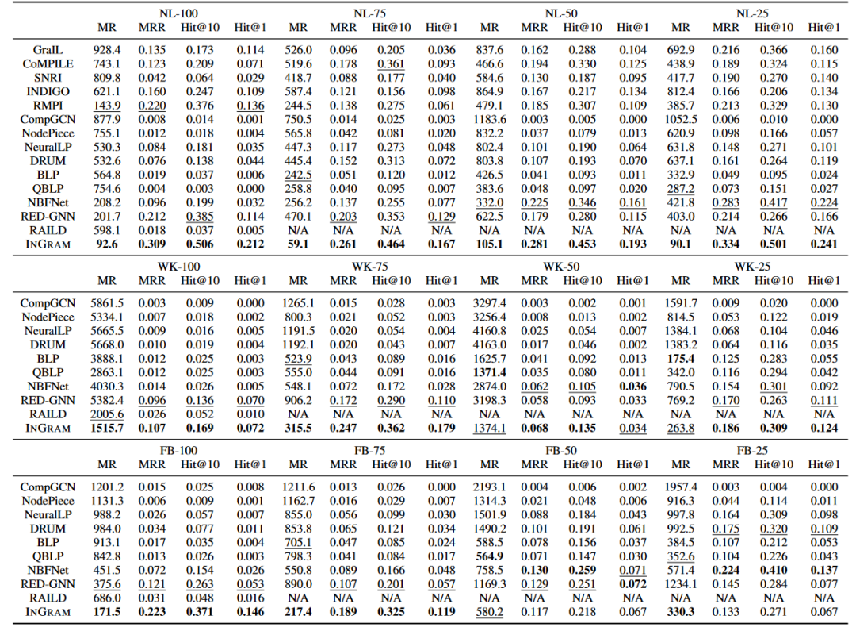
MR(↓)、MRR(↑)、Hit@10(↑)和Hit@1(↑)。
上表显示了12个不同数据集的结果,其中所有实体都是新的,每个数据集都有不同的新关系比例。 在12个具有不同新关系比例的数据集上,INGRAM在归纳链接预测方面显著优于14种不同的知识图补全方法,特别是当新关系的比例很高时,INGRAM与最佳基线方法比较起来表现更有效。
注:RMPI和INGRAM的区别 RMPI (Geng et al ., 2023)同时研究了处理新关系的问题,尽管RMPI和INGRAM解决问题的方式有很大不同。
1、RMPI为每个候选实体提取一个局部子图来对相应的三元组进行评分,而INGRAM直接利用给定知识图的整体结构。
2、RMPI对每个单独的三元组使用一个未加权的关系视图,而INGRAM定义了一个全局关系图,其中权重很重要。
3、INGRAM比RMPI更具可扩展性和有效性。例如,INGRAM对NL-100数据集的处理时间为15分钟,RMPI为52小时,而INGRAM的链路预测性能要比RMPI好得多。
4、RMPI仅为知识图谱补全而设计,不计算嵌入向量,而INGRAM返回一组实体和关系的嵌入向量,这些向量也可以用于许多其他下游任务。
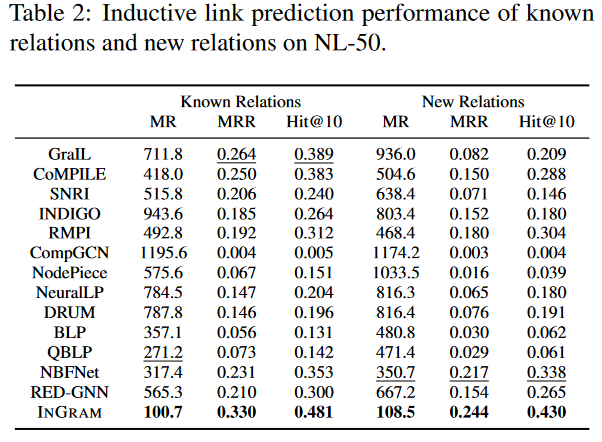
在上表中分析了NL-50上具有已知关系和新关系的三元组的模型性能。所有的方法在已知关系上的表现都比新关系好。另外,对于基线方法,已知关系和新关系之间的性能差距很大。可以看到,对于已知关系和新关系,INGRAM的性能在所有指标上都比最好的基线方法好很多。
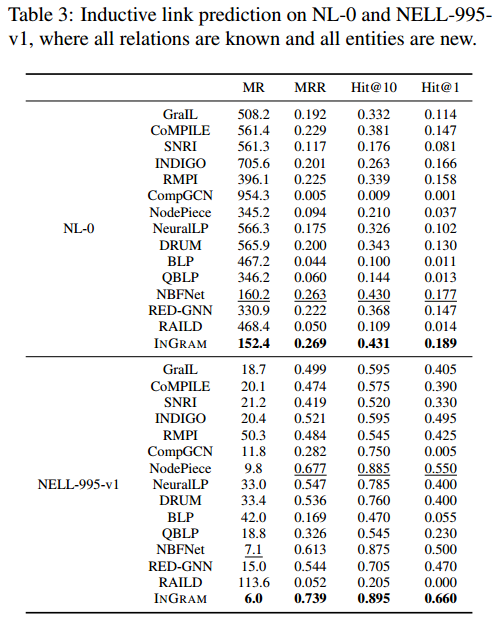
尽管INGRAM被设计为考虑在推理时出现新关系的情况,本文也对传统的归纳链接预测场景进行了实验,其中所有关系都是已知的,所有实体都是新的。 表3显示了对NL-0和NELL-995-v1的归纳链路预测结果,其中所有实体都是新的,所有关系都是已知的。可以看到,INGRAM在所有指标上都优于所有基线。尽管INGRAM没有像其他基线那样学习特定的关系模式,但INGRAM在关系的归纳推理上显示出合理的性能,同时对关系的半归纳和归纳推理有额外的概括能力。
七、创新点
定义关系图,将关系看成实体节点,就可以用实体节点的嵌入方式进行嵌入,最后再利用注意力机制进行聚合,很巧妙。

八、模型不足
实体嵌入和关系嵌入排列敏感
为了提高模型的表达能力,本模型选择在训练过程中使用glorot初始化对每个epoch随机重新初始化所有节点和关系类型的输入嵌入,随机初始特征打破了生成的表示的双重等变性,使它们对节点和关系类型索引的排列敏感。















 444
444

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









