









前言
在了解这部分内容之前,先问大家几个问题,你是否总听到在周围互联网工作的小伙伴们一口一个降级啊、熔断啊,听到是什么感受呢?
想插嘴,却不知道该说些什么;想说些什么,却又怕说错了被人笑话。
降级和熔断听起来好像挺高大上的呀,他们究竟能应用到哪些应用场景中来呢?什么样的应用场景才能用到降级和熔断呢?我这小作坊一亩三分地的业务也需要降级和熔断么?它离我们的真实业务到底有多远?
带着这些问题我们就拉开SpringCloud服务容错——Hystrix的序幕。
服务容错——Hystrix
没错,它又是Netflix中的一部分,现在大家体会到这家影视公司的牛逼之处了吧,没想到一家影视公司这么不务正业,在微服务架构上做出了如此大的贡献,别说让国内的影视公司做这件事了,这正儿八经的IT公司还天天忙着卖假药呢,哪有我们这外国友人的公司Netfilx这么有奉献精神呢。
这个Hystrix的意思是豪猪,服务容错为什么和豪猪有关系呢?
我也不知道。。。总之给项目起名字一定要让别人猜不出你的项目是干什么的,那这个名字就起的是相当的成功。
好,我们废话不多说,来看下面内容。
服务容错解决方案
服务雪崩
大家可能都听说过缓存雪崩对吧,但是比缓存雪崩来的更猛烈一些的就是服务雪崩了,通过下图,让大家看看什么是服务雪崩:
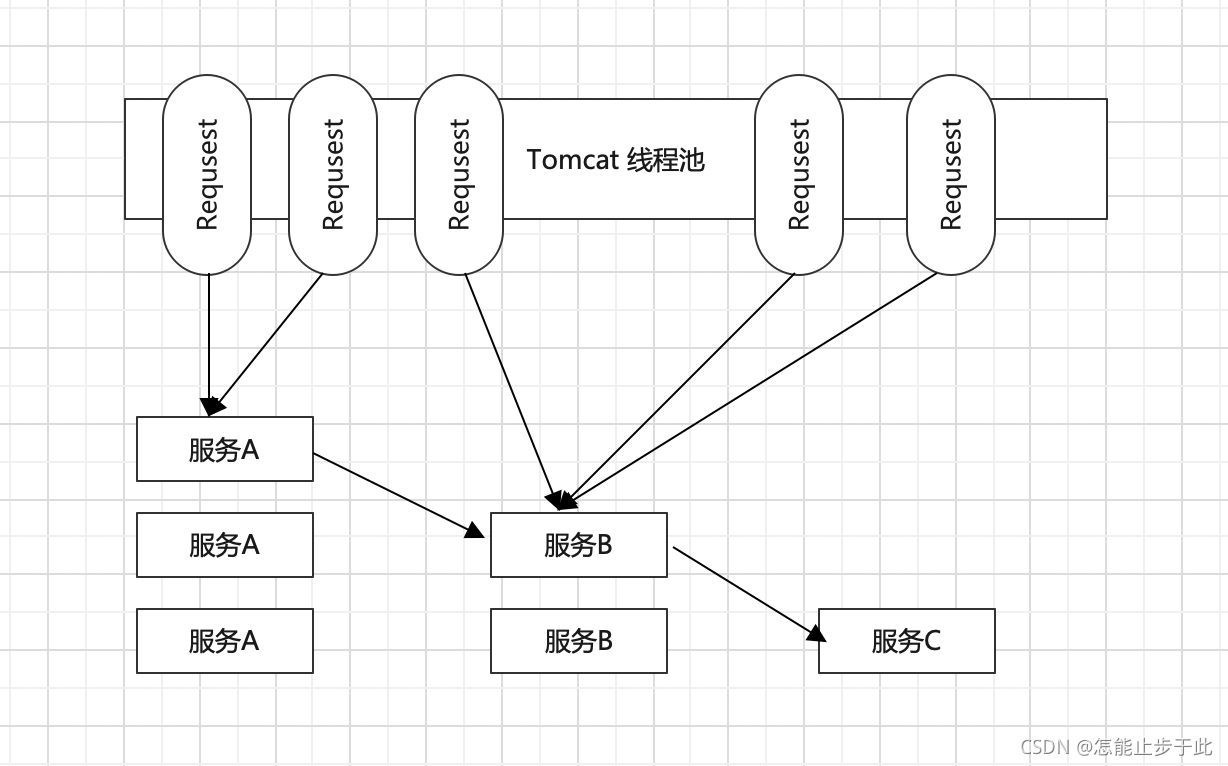
上图中,我们有三个服务,分别是服务A、服务B、服务C,由于服务C的调用量相对较少,所以我们给他分配的节点也比较少。
我们Tomcat线程池中,有五个请求,都通过了Tomcat线程池发起了对服务的访问,假如前两个请求都调用在了服务A,然后又从服务A调用到了服务B,后面三个请求直接调用服务B,然后他们这些请求调用服务B的同时,在服务B的内部还会调用服务C。
然后我们模拟这样一个场景:
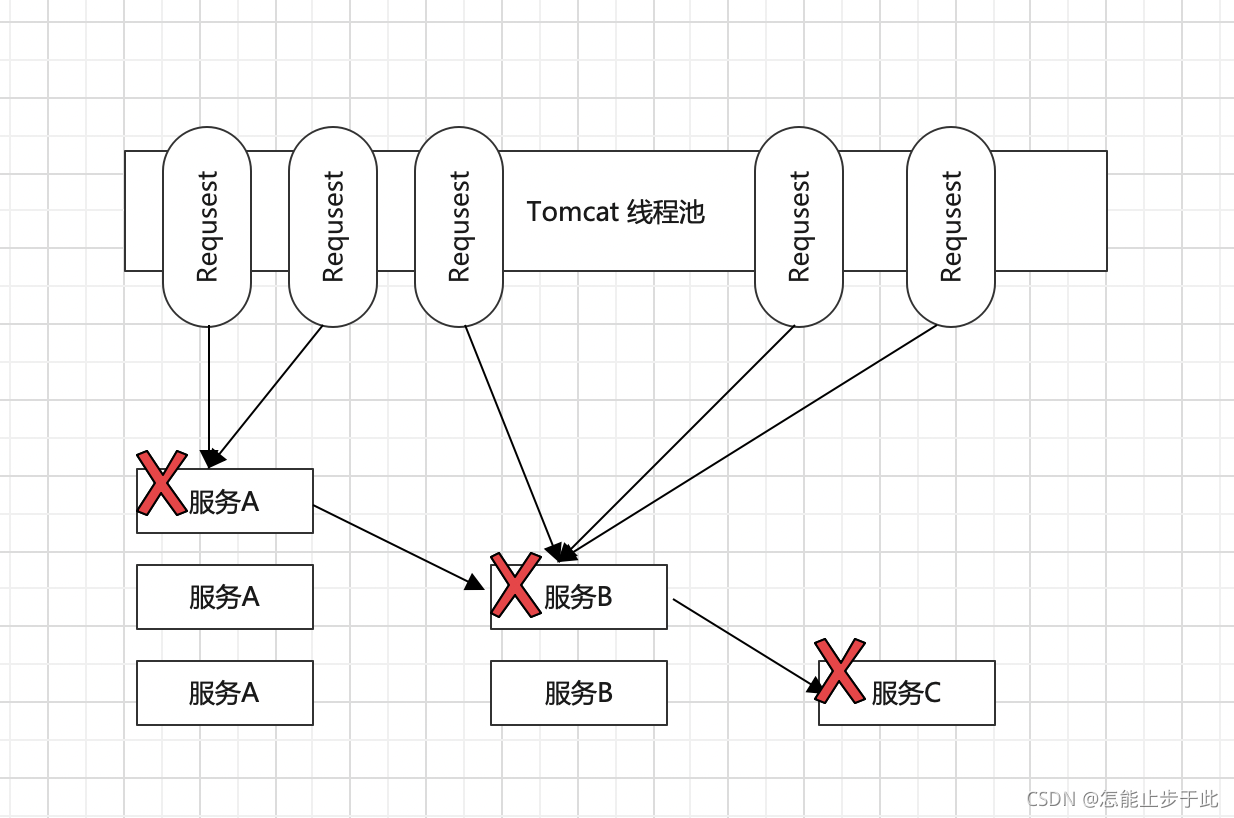
这里,假如服务C因为某些原因,比如数据库连接池被耗光了,导致查询语句和写入语句特别慢,那么调用服务C的服务将有可能会获得Timeout响应,即服务超时,那么所有到C的请求就都Timeout了,那么我们如果不做任何管控,接下来这个超时就会蔓延到了服务B,服务B牺牲了,服务A同样也牺牲了。
那么整条服务链路,因为没有对Timeout做管控,导致这个超时的问题从服务C蔓延到了B再蔓延到A,就像蝴蝶效应一样,从一个小节点引发,逐渐蔓延到了整个服务集群、整个业务链路上,那么我们称它为服务雪崩,这种情况如果发生了,后续所有请求就都不能访问了,因为你的后台整个集群瘫痪了,再来更多的请求无非是给后台带来更大的压力。
这个时候我们就需要用到熔断、降级的手段。
其实熔断相对于降级来说,更是一种雷霆手段,通常熔断都是建立在降级之上的。
容器线程耗尽
我们都知道Tomcat在容器级别是有一个线程池专门接待来访请求,我们来看下这个图:
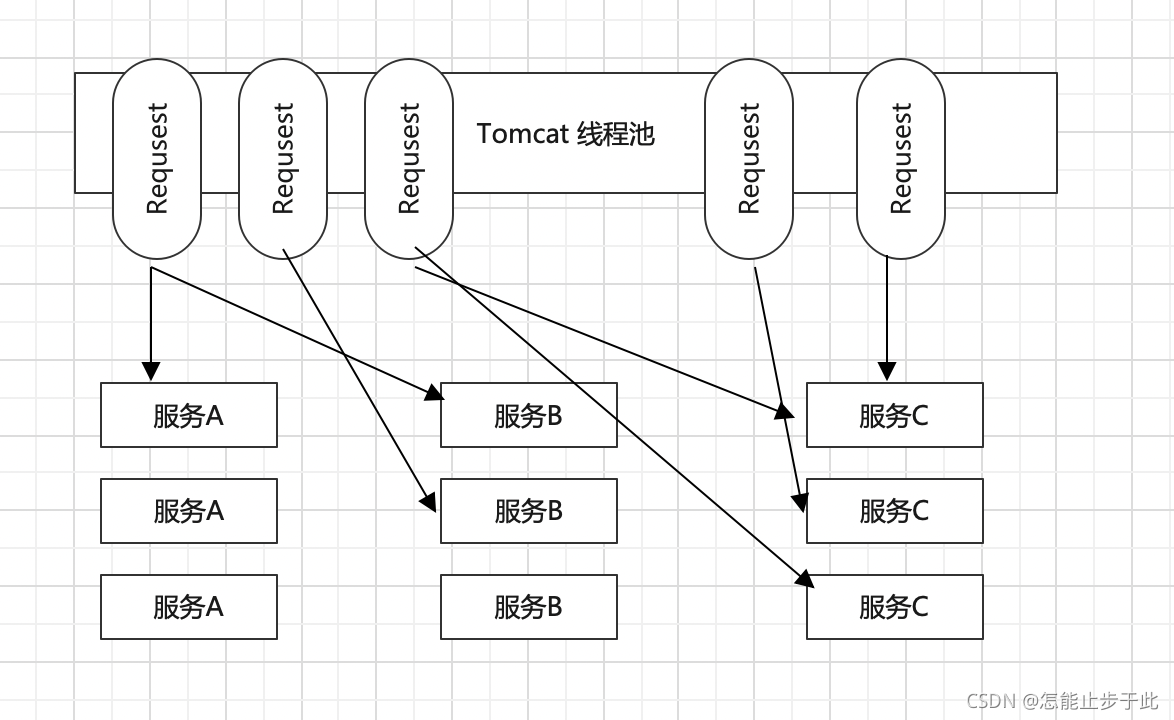
这里我们分配了三个数量一样的服务节点,我们的请求都随意访问,但是突然意外又发生了:

这时候,两个服务C又挂了,但是这里并不是完全挂掉了,是一种半死不活的状态,也就是说它还可以处理别的请求,只不过是因为性能瓶颈或者各种原因导致它的响应特别慢,这时候你的所有请求就会长时间阻塞在这里。
那这两个服务C半死不活不要紧,但是它这里就连累了调用的服务方了,就会导致调用服务C的Request都长时间得不到返回,那这就会导致随着时间的推移,Tomcat线程池中的线程逐渐被访问C的Request占据了,也就是说服务C导致的响应过慢,就有可能会传导到Tomcat的容器线程池当中,使所有访问C的Request都处于挂起状态,这种时间持续的越长,就有可能导致容器中被访问C的Request挤满,进而导致访问其他服务器的请求都无法处理了。
这种场景,我们就需要用到线程隔离方案,Hystrix的独门武艺。















 8222
8222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









