







Hi,我是山月。
之前给大家分享了函数实例详解的第二篇文章,主要讲解了var()、std()、quantile()、cov()、corr()、skew()、kurt()、mode()函数。
今天来给大家分享下面三个函数:
describe() | 描述性统计(一次性返回多个统计结果) |
groupby() | 分组 |
aggregate() | 聚合运算(可以自定义统计函数) |
用到的数据如下:
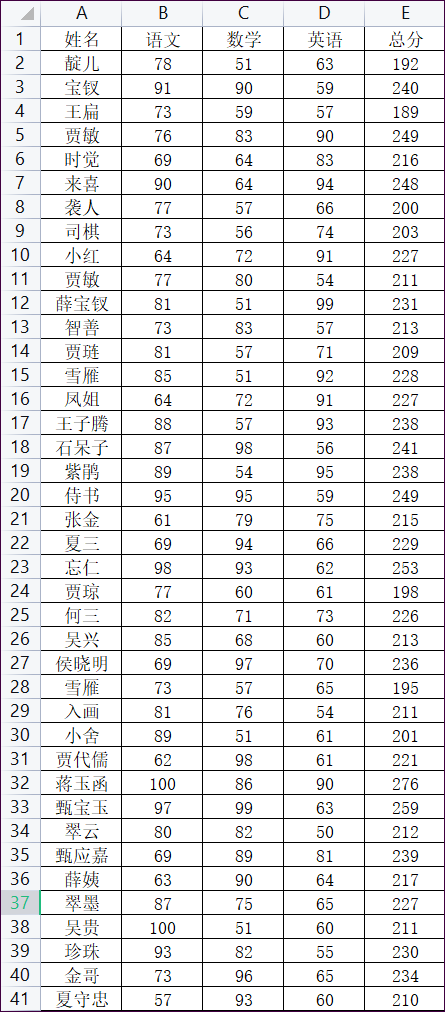
1、describe()
生成描述性统计数据。
描述性统计包括那些总结数据集分布的集中趋势、离散度和形状的统计数据,不包括 NaN 值。
describe(percentiles=None, include=None, exclude=None, datetime_is_numeric=False)
参数:
percentiles:可选。是一个列表,列表的元素值是介于 0 和 1 之间的百分位数。默认值为 [.25, .5, .75],意思是返回第 25、第 50 和第 75 个百分位数。
include:可选。选项有:‘all’、类似 dtypes 的列表、None(默认)。
all:输入的所有列都将包含在输出中。
类似 dtypes 的列表 :将结果限制为提供的数据类型。要限制为数字类型,可以提交 numpy.number;要限制为对象列,可以提交数据类型 numpy.object;字符串也可以以 select_dtypes 的样式使用(例如 df.describe(exclude=['O']));要限制为 pandas 分类列,可以使用“category”。
None(默认):结果将包括所有数字列。
exclude:可选。选项有:类似 dtypes 的列表、None(默认)。
类似 dtypes 的列表 :从结果中排除提供的数据类型。要排除数字类型,可以提交 numpy.number。要排除对象列,可以提交数据类型 numpy.object。字符串也可以以 select_dtypes 的样式使用(例如 df.describe(exclude=['O']))。要排除 pandas 分类列,可以使用“category”。
None(默认):结果将不排除任何内容。
datetime_is_numeric:布尔值,默认为 False。
是否将 datetime dtypes 视为数字。这会影响为列计算的统计信息。对于 DataFrame 输入,这还控制默认情况下是否包含日期时间列示例:
import pandas as pd
import numpy as np
scores = pd.read_excel("学生成绩.xlsx", sheet_name="Sheet1") # 读取表格数据
default_describe = scores.describe() # 默认条件的描述性统计数据
print(default_describe)
print('---')
describe_1 = scores.describe(include="all") # include选项为all
print(describe_1)
print('---')
describe_2 = scores.describe(include=[np.number]) # include选项为类似 dtypes 的列表,限制为统计数字类型
print(describe_2)
print('---')
describe_3 = scores.describe(include=[object]) # include选项为类似 dtypes 的列表,限制为统计对象列
print(describe_3)
print('---')
describe_4 = scores.describe(exclude=[np.number]) # exclude选项为类似 dtypes 的列表,排除统计数字类型
print(describe_4)
'''
语文 数学 英语 总分
count 40.000000 40.000000 40.000000 40.000000
mean 79.400000 74.525000 70.125000 224.050000
std 11.531006 16.624029 14.176882 19.603702
min 57.000000 51.000000 50.000000 189.000000
25% 72.000000 57.000000 60.000000 211.000000
50% 79.000000 75.500000 65.000000 226.500000
75% 88.250000 90.000000 81.500000 238.000000
max 100.000000 99.000000 99.000000 276.000000
---
姓名 语文 数学 英语 总分
count 40 40.000000 40.000000 40.000000 40.000000
unique 38 NaN NaN NaN NaN
top 贾敏 NaN NaN NaN NaN
freq 2 NaN NaN NaN NaN
mean NaN 79.400000 74.525000 70.125000 224.050000
std NaN 11.531006 16.624029 14.176882 19.603702
min NaN 57.000000 51.000000 50.000000 189.000000
25% NaN 72.000000 57.000000 60.000000 211.000000
50% NaN 79.000000 75.500000 65.000000 226.500000
75% NaN 88.250000 90.000000 81.500000 238.000000
max NaN 100.000000 99.000000 99.000000 276.000000
---
语文 数学 英语 总分
count 40.000000 40.000000 40.000000 40.000000
mean 79.400000 74.525000 70.125000 224.050000
std 11.531006 16.624029 14.176882 19.603702
min 57.000000 51.000000 50.000000 189.000000
25% 72.000000 57.000000 60.000000 211.000000
50% 79.000000 75.500000 65.000000 226.500000
75% 88.250000 90.000000 81.500000 238.000000
max 100.000000 99.000000 99.000000 276.000000
---
姓名
count 40
unique 38
top 贾敏
freq 2
---
姓名
count 40
unique 38
top 贾敏
freq 2
''2、groupby()
使用映射器或通过一系列的列对DataFrame进行分组。
groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True)
参数:
by:映射、函数、标签或标签列表
用于确定 groupby 的组。如果 by 是一个函数,它会在对象索引的每个值上调用。如果传递了 dict 或 Series,则 Series 或 dict VALUES 将用于确定组(Series 的值首先对齐;参见 .align() 方法)。如果传递了长度等于所选轴的列表或 ndarray,则按原样使用这些值来确定组。一个标签或标签列表可以通过 self 中的列传递给 group。请注意,元组被解释为(单个)键。
axis:可选项:0/'index'、 1/'columns',默认0
沿行 (0) 或列 (1) 拆分。
level:可选项:整数、 级别名称或其序列、 None(默认)
如果轴是多索引(层次),则按特定级别分组。
as_index:布尔值,默认为 True
对于聚合输出,返回以组标签为索引的对象。仅与 DataFrame 输入相关。as_index=False 实际上是“SQL 风格”的分组输出。
sort:布尔值,默认为 True
对组键进行排序。关闭此功能可获得更好的性能。请注意,这不会影响每组内的观察顺序。Groupby 保留每个组内的行顺序。
group_keys:布尔值,默认为 True
调用apply时,将组键添加到索引以识别片段。
squeeze:布尔值,默认为 False
尽可能减少返回类型的维数,否则返回一致的类型。
observed:布尔值,默认为 False
如果为True:仅显示分类Grouper的观察值。如果为False:显示分类分组的所有值。
dropna:布尔值,默认为 True。
如果为True,并且组键包含NA值,则将删除NA值以及行/列。如果为False,NA值也将被视为组中的键示例:
import pandas as pd
scores = pd.read_excel("学生成绩.xlsx", sheet_name="Sheet1") # 读取表格数据
scores_15 = scores.head(15)
chinese_groupby = scores_15.groupby(by=['语文'])
print(chinese_groupby)
print('---')
print(chinese_groupby.size()) # 计数
'''
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000021F90BA23C8>
---
语文
64 2
69 1
73 3
76 1
77 2
78 1
81 2
85 1
90 1
91 1
dtype: int64我们可以看到前15个学生里,64分的有两个:小红和凤姐,所以64的计数为2。但语文为69的只有一个,所以为1。
当然,这只是groupby最简单的一个示例。更复杂的比如和agg结合的这里我们就先不说了,以后可以在实例中给大家演示。
3、aggregate()
在一个或多个列上应用某些聚合运算,常见的聚合运算有:sum(求和)、max(最大值)、min(最小值)。
aggregate(func=None, axis=0, *args, **kwargs)
参数:
func:函数、字符串、列表或字典
用于聚合数据的函数。如果是函数,则必须在传递 DataFrame 或传递给 DataFrame.apply 时工作。
接受的组合是:函数;字符串函数名;函数和/或函数名称列表,例如 [np.sum, 'mean'];轴标签的字典 -> 函数、函数名称或此类列表。
axis:0/'index'、 1/'columns',默认0
如果为 0 或“index”:将函数应用于每一列。如果为 1 或“columns”:将函数应用于每一行。
*args
要传递给 func 的位置参数。
**kwargs
要传递给 func 的关键字参数示例:
import pandas as pd
scores = pd.read_excel("学生成绩.xlsx", sheet_name="Sheet1") # 读取表格数据
agg_scores = scores.agg({'语文' : ['max', 'min'], '数学' : ['max', 'min'], '英语' : ['max', 'min'], '总分' : ['max', 'min']})
print(agg_scores)
'''
语文 数学 英语 总分
max 100 99 99 276
min 57 51 50 189
'''我们在第一篇介绍min、max函数的用法时,就计算了三科的最大最小值:

只是那是一个一个的来计算的,比较繁冗,不过通过agg函数,就简洁多了。
好啦,今天的三个函数就介绍到这里。
--- End ---














 4027
4027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









