






1 常用命令 官方文档地址:https://clickhouse.com/docs/zh/getting-started
1.1 查看库相关信息
SELECT name FROM system.databases;
1.2 查看表相关信息
SELECT * FROM system.tables WHERE database =‘your_database_name’ AND name = ‘your_table_name’
1.3 查看分区相关信息
SELECT database, table, partition, active, min_date, max_date FROM system.parts WHERE active AND database = ‘your_database_name’ AND table = ‘your_table_name’;
1.4 查看分片相关信息
SELECT *
FROM system.clusters
WHERE cluster = ‘your_cluster_name’ – 替换为你的集群名称
AND shard_num IS NOT NULL;
2 基本概念
一、表分区(Partition)概念
表中的数据可以按照指定的字段分区存储,每个分区在文件系统中都是都以目录的形式存在。常用时间字段作为分区字段,数据量大的表可以按照小时分区,数据量小的表可以在按照天分区或者月分区,查询时,使用分区字段作为Where条件,可以有效的过滤掉大量非结果集数据。
ClickHouse 分区的目的是为了尽可能地减少读取的数据量,那么它有哪些特点呢?
创建分区的方法比较简单,只需要在建表时通过partition by语法指定即可;
不止可以按某个字段做partition by,还可以支持按任意合法的表达式进行分区操作,比如toYYYYMM()按月做分区;
支持对partition进行TTL管理,淘汰过期的分区数据;
插入数据到分区表中时,先会将数据写入到分区目录下的segment文件中,后台程序会自动进行合并,当然也可以通过optimize命令手动触发合并。
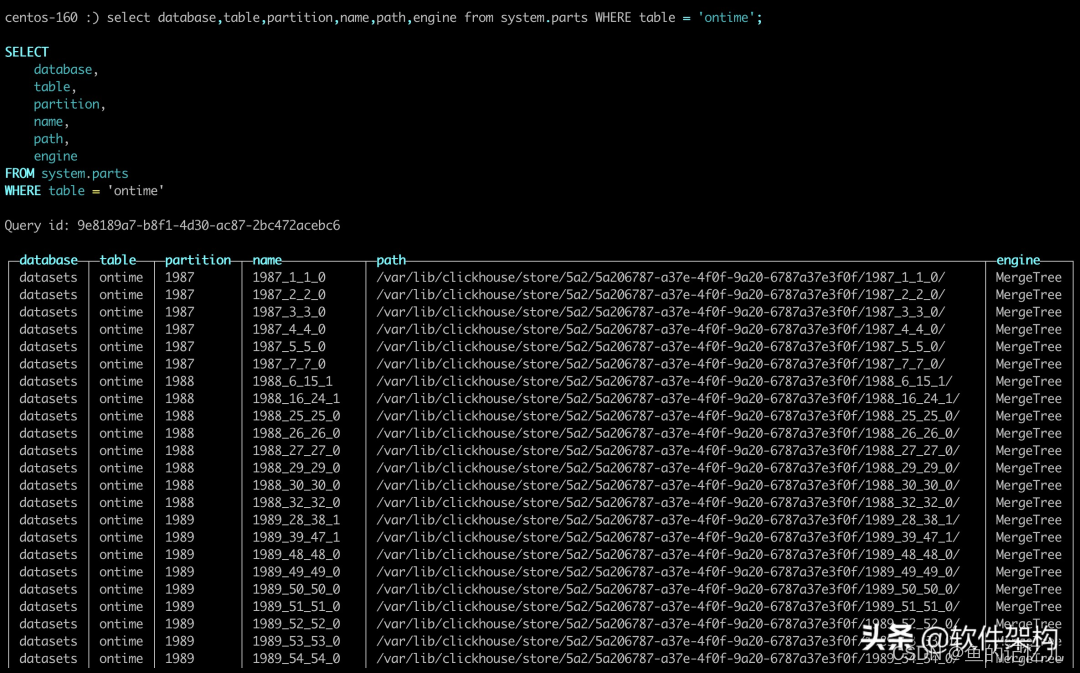
在ClickHouse中有专门一张表对partition进行管理,那就是system.parts。
select database,table,partition,name,path,engine from system.parts WHERE table = ‘ontime’;
二、分片(Shard)概念
一个分片本身就是ClickHouse一个实例节点,分片的本质就是为了提高查询效率,将一份全量的数据分成多份(片),从而降低单节点的数据扫描数量,提高查询性能。
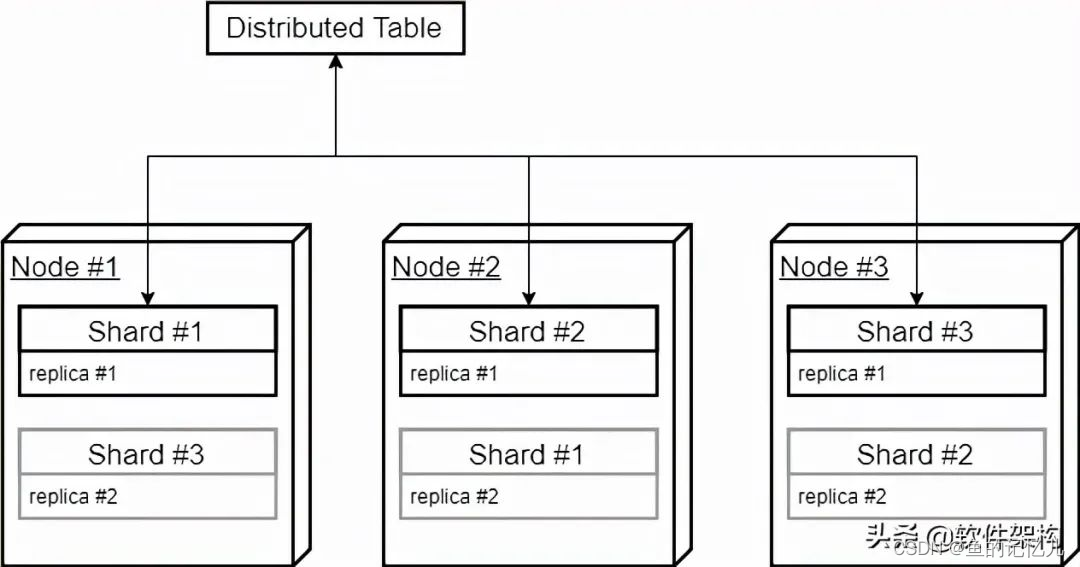
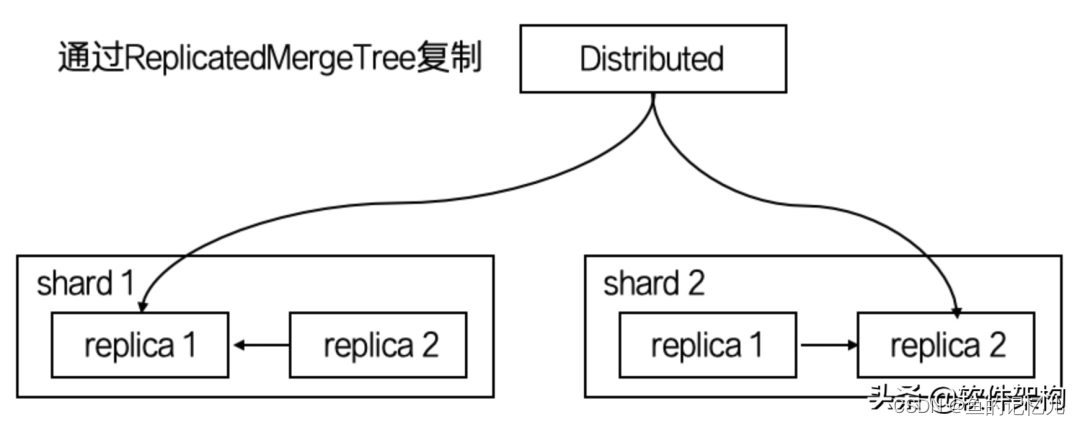
上图中,除了分片(Shard)之外,还同时引入了副本(Replica)概念。
副本(Replica)简单理解就是相同的数据备份,在ClickHouse中通过复制集,我们实现了保障数据可靠性外,也通过多副本的方式,增加了ClickHouse查询的并发能力。这里一般有2种方式:1.基于ZooKeeper的表复制方式;2.基于Cluster的复制方式。由于我们推荐的数据写入方式本地表写入,禁止分布式表写入,所以我们的复制表只考虑ZooKeeper的表复制方案。
在集群配置中,Shard标签里面配置的replica互为副本,将internal_replication设置成true,此时写入同一个Shard内的任意一个节点的本地表,ZooKeeper会自动异步的将数据同步到互为副本的另一个节点。
1 常用库引擎
一般就采用默认的
常见表引擎

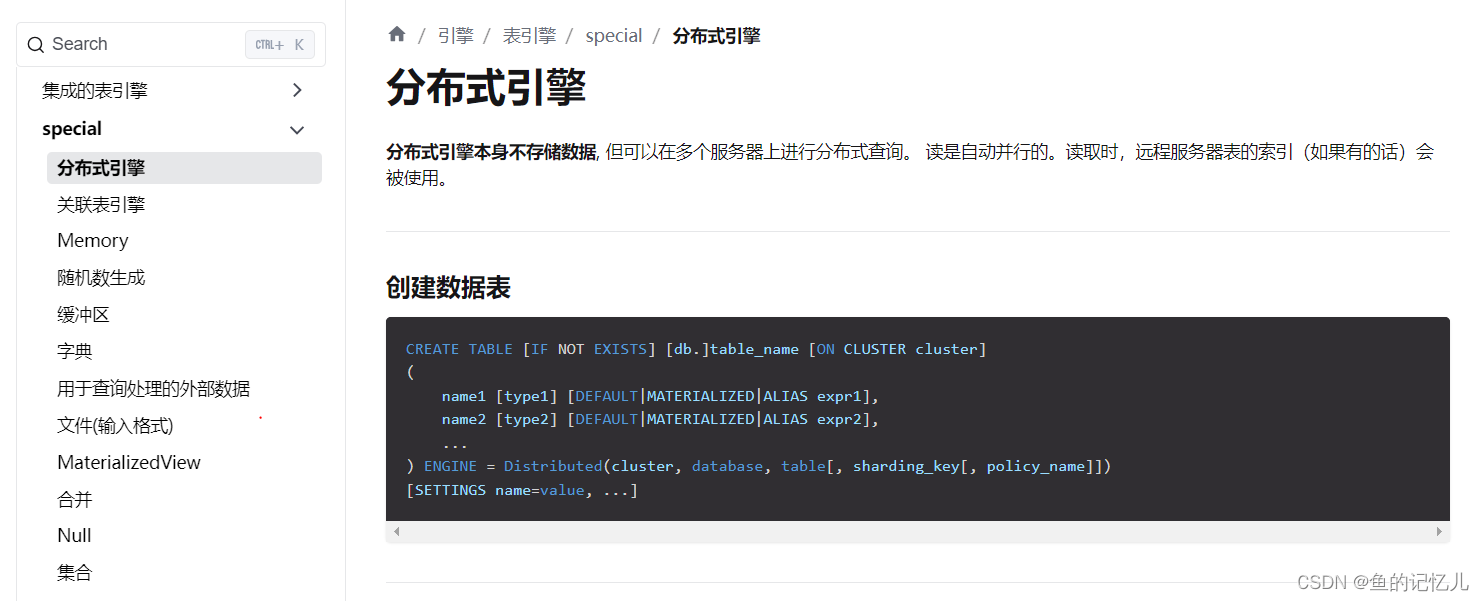
其中只有分布式引擎distribute,replaceingMergeTree,summingMergeTree较为常用,可以单独学习一下这三种引擎
三 MergeTree(重点)
ClickHouse中最强大的表引擎当属MergeTree(合并树)引擎及该系列(MergeTree)中的其他引擎,支持索引和分区,地位可以相当于innodb之于Mysql。 而且基于MergeTree,还衍生除了很多小弟,也是非常有特色的引擎。
建表语句:
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);
四 partition by 分区(可选)
作用
学过hive的应该都不陌生,分区的目的主要是降低扫描的范围,优化查询速度
如果不填
只会使用一个分区。
分区目录
MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文件就会保存到不同的分区目录中。
并行
分区后,面对涉及跨分区的查询统计,ClickHouse会以分区为单位并行处理。
数据写入与分区合并
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入后的某个时刻(大概10-15分钟后),ClickHouse会自动执行合并操作(等不及也可以手动通过optimize执行),把临时分区的数据,合并到已有分区中。
optimize table xxxx final;
例如插入一部分数据,可见插入的数据未纳入任何分区
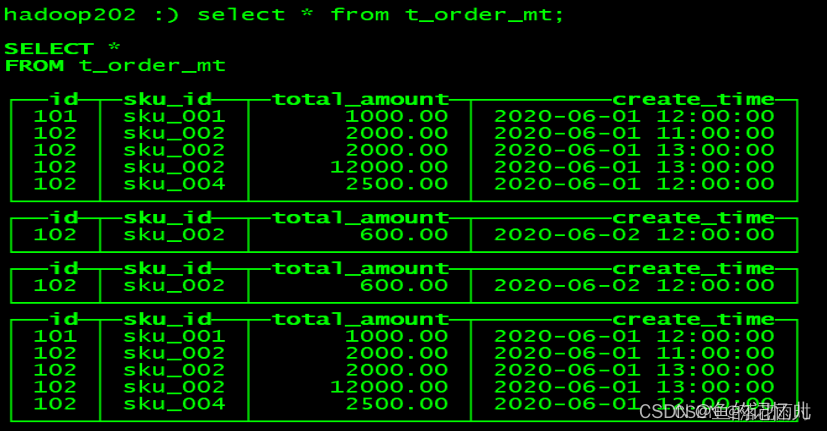
手动进行合并后
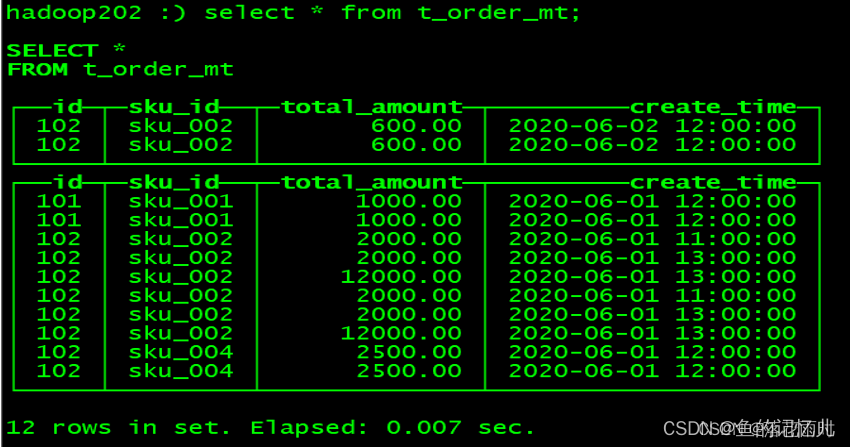
optimize table t_order_mt final;
再次查询:
五 primary key主键(可选)
ClickHouse中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束。这就意味着是可以存在相同primary key的数据的。
主键的设定主要依据是查询语句中的where 条件。
根据条件通过对主键进行某种形式的二分查找,能够定位到对应的index granularity,避免了全表扫描。
index granularity: 直接翻译的话就是索引粒度,指在稀疏索引中两个相邻索引对应数据的间隔。ClickHouse中的MergeTree默认是8192。官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据。
稀疏索引:
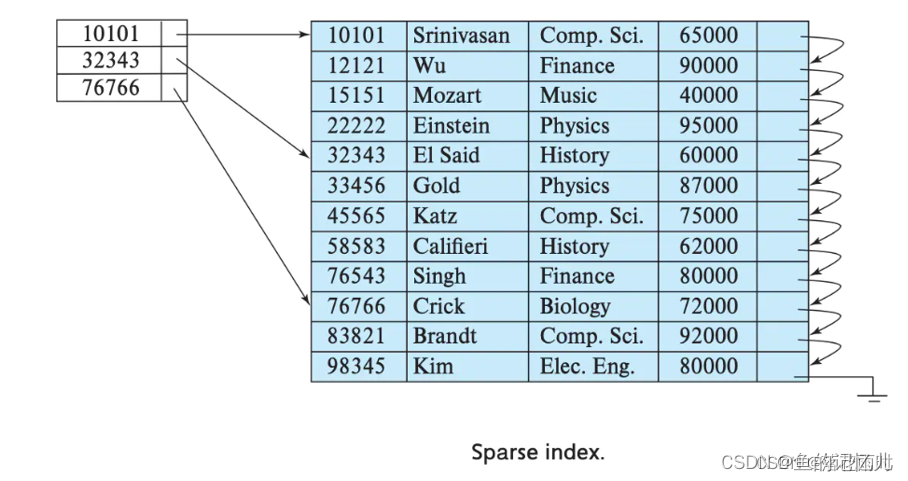
稀疏索引的好处就是可以用很少的索引数据,定位更多的数据,代价就是只能定位到索引粒度的第一行,然后再进行进行一点扫描。
六 order by(必选)
order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
order by是MergeTree中唯一一个必填项,甚至比primary key 还重要,因为当用户不设置主键的情况,很多处理会依照order by的字段进行处理(比如后面会讲的去重和汇总)。
要求:主键必须是order by字段的前缀字段。
比如order by 字段是 (id,sku_id) 那么主键必须是id 或者(id,sku_id)
二级索引
目前在ClickHouse的官网上二级索引的功能是被标注为实验性的。
七 数据TTL
TTL即Time To Live,MergeTree提供了可以管理数据或者列的生命周期的功能。
(1) 列级别TTL
创建测试表
create table t_order_mt2(
id UInt32,
sku_id String,
total_amount Decimal(16,2) TTL create_time+interval 10 SECOND,
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id, sku_id);
(2) 表级TTL
下面的这条语句是数据会在create_time 之后10秒丢失
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;
涉及判断的字段必须是Date或者Datetime类型,推荐使用分区的日期字段。
能够使用的时间周期:
SECOND
MINUTE
HOUR
DAY
WEEK
MONTH
QUARTER
YEAR
八. ReplacingMergeTree
ReplacingMergeTree是MergeTree的一个变种,它存储特性完全继承MergeTree,只是多了一个去重的功能。 尽管MergeTree可以设置主键,但是primary key其实没有唯一约束的功能。如果你想处理掉重复的数据,可以借助这个ReplacingMergeTree。
去重时机
数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。
去重范围
如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区的去重。
所以ReplacingMergeTree能力有限, ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。















 1458
1458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









