







一. 介绍
本文是针对异构的网络融合技术,是基于上一篇OTFusion的论文进行的工作,解决了神经元关联问题。当所有的网络都具有相同的架构时,OTFusion比普通平均算法有明显的改进。与其他基于平均的模型融合方法相比,OTFusion的一个优点是,由于最优传输的性质,它可以融合不同宽度(即神经元数量)的网络。然而,OTFusion仍然是一种分层的方法,不能直接用于异构神经网络。我们需要找到两个对应的层,在平均权重矩阵之前匹配它们的神经元。这一计划面临两个挑战。首先,层与层之间的一对一映射无法提前实现。当层数不同时,具有相同索引的层之间的一对一映射可能会导致不匹配。其次,假设我们已经成功地找到了一个一对一的映射,仍然需要对没有对应层的其余层进行特殊处理。简单地删除这些层会降低更深层次网络的性能,这可能会逐渐降低融合模型,本篇论文考虑了深度不一样的网络的融合技术,将模型融合技术应用到异构的网络中。
二. 跨层对齐的模型融合
符号: 我们将
⟦
n
⟦
\llbracket n \llbracket
[[n[[定义为一个整数集合
{
1
,
…
,
n
}
\{1,\ldots, n\}
{1,…,n}和
I
n
\mathbb{I}_n
In定义为一个大小为
n
∗
n
n \ * n
n ∗n的单位矩阵。我们用A, B表示各个模型,用
F
\mathcal{F}
F表示融合模型。
l
l
l表示层索引。模型A的
l
l
l层有
p
A
(
l
)
p_A^{(l)}
pA(l)神经元和一个激活函数
f
A
(
l
)
f_A^{(l)}
fA(l)。模型A
l
l
l层的预激活向量和激活向量分别记为
z
A
(
l
)
,
x
A
(
l
)
∈
R
p
A
(
l
)
\boldsymbol{z}_A^{(l)},\boldsymbol{x}_A^{(l)} \in \mathbb{R}^{p_A^{(l)}}
zA(l),xA(l)∈RpA(l)。模型A的
l
l
l和
l
−
1
l-1
l−1层之间的权矩阵为
W
A
(
l
,
l
−
1
)
\boldsymbol{W}_A^{(l, l-1)}
WA(l,l−1)。下面的方程在模型A的两个连续层之间成立:
x
(
l
)
=
f
A
(
l
)
(
z
A
(
l
)
)
=
f
A
(
l
)
(
W
A
(
l
,
l
−
1
)
x
(
l
−
1
)
)
(1)
\boldsymbol{x}^{(l)}=f_A^{(l)}\left(\boldsymbol{z}_A^{(l)}\right)=f_A^{(l)}\left(\boldsymbol{W}_A^{(l, l-1)} \boldsymbol{x}^{(l-1)}\right) \tag1
x(l)=fA(l)(zA(l))=fA(l)(WA(l,l−1)x(l−1))(1)
我们利用
t
t
t个样本获得预激活矩阵,形成一个
t
t
t-行预激活矩阵。让
Z
A
(
l
)
∈
R
t
×
p
A
(
l
)
\boldsymbol{Z}_A^{(l)} \in \mathbb{R}^{t \times p_A^{(l)}}
ZA(l)∈Rt×pA(l)表示模型a的
l
l
l层的预激活矩阵对于
t
t
t样本,和
Z
B
(
l
)
∈
R
t
×
p
B
(
l
)
\boldsymbol{Z}_B^{(l)} \in \mathbb{R}^{t \times p_B^{(l)}}
ZB(l)∈Rt×pB(l)表示模型B的
l
l
l层的预激活矩阵对于相同的
t
t
t样本。激活矩阵
X
A
(
l
)
,
X
B
(
l
)
\boldsymbol{X}_A^{(l)}, \boldsymbol{X}_B^{(l)}
XA(l),XB(l)通过对预激活矩阵按元素应用相应的激活函数得到。
问题定义: 接下来,我们考虑融合两个具有相同体系结构家族的前馈网络A和B。两个网络具有相同的输入和输出维数,但隐藏层数不同。在每个网络中,隐藏层都有一个ReLU激活函数,这是现代架构的通用设置。为了正确地处理偏差项和批处理规范化层,需要进行额外的工作,因此我们将它们留给以后的工作。设 m m m和 n n n分别为模型A和模型B的隐层数。考虑到输入和输出层,层数分别为 m + 2 m+2 m+2和 n + 2 n+2 n+2。在不丧失一般性的情况下,假设 m ≥ n m \geq n m≥n。模型A和模型B的层索引分别为 { 0 , 1 , … , m + 1 } \{0,1,\ldots, m+1\} {0,1,…,m+1}和 { 0 , 1 , … , n + 1 } \{0,1,\ldots, n+1\} {0,1,…,n+1}
标准策略: 框架有三个组件,如下图所示。第一部分是跨层对齐,即从模型B的隐层到模型a的隐层一一对应。第二部分是基于跨层对齐使两个模型的层数相等的层平衡方法。最后是一种适用于相同尺寸模型的分层模型融合方法。框架的第三部分采用任何模型融合方法,可以融合两个具有相同层数的神经网络。
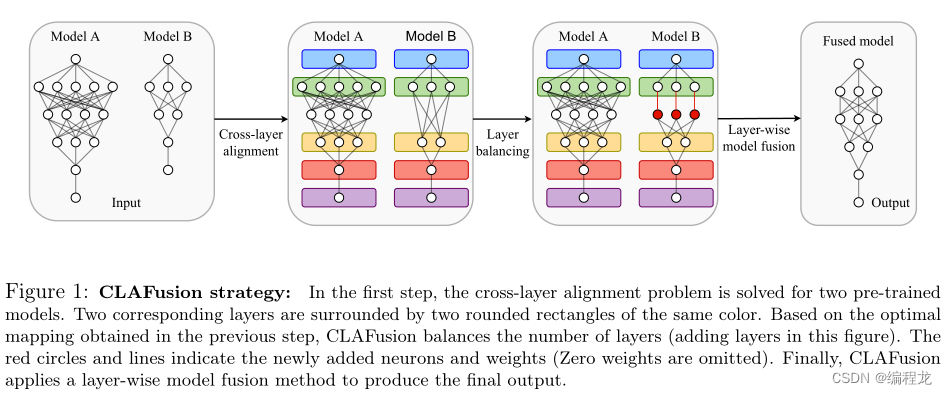
2.1 跨层对齐
由于两个模型的输入和输出层在维度和功能上都是相同的,所以我们只对齐它们的隐藏层。此外,第一层和最后一层隐藏层通常对模型性能起着关键作用[36]。因此,我们直接匹配两个模型的第一层和最后一层隐藏层。在 n = 1 n = 1 n=1的情况下,我们优先考虑第一层而不是最后一层。此外,两个网络是前馈的,因此需要映射以保持层的顺序。总之,我们将CLA问题表述如下。
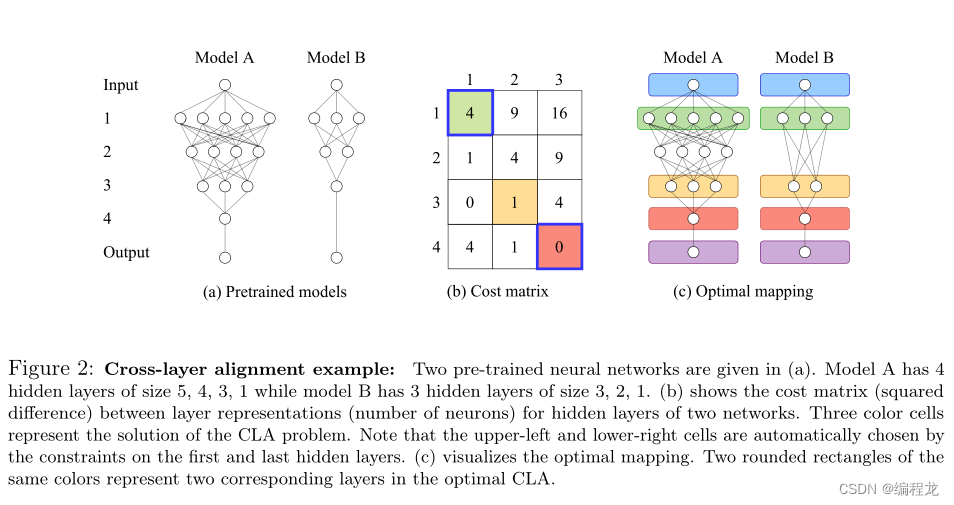
定义 1: 假设我们对两个模型的隐藏层有两个层表示, L A = { L A ( 1 ) , … , L A ( m ) } \boldsymbol{L}_A=\left\{L_A^{(1)},\ldots, L_A^{(m)}\right\} LA={LA(1),…,LA(m)}和 L B = { L B ( 1 ) , … , L B ( n ) } \boldsymbol{L}_B=\left\{L_B^{(1)},\ldots, L_B^{(n)}\right\} LB={LB(1),…,LB(n)}。设 C ∈ R m × n \boldsymbol{C} \in \mathbb{R}^{m \times n} C∈Rm×n表示它们之间的代价矩阵,即 C i , j = d ( L A ( i ) , L B ( j ) ) , i ∈ ⟦ m ⟧ , j ∈ ⟦ n ⟧ \boldsymbol{C}_{i, j}=d\left(L_A^{(i)},L_B^{(j)}\right),i \in\llbracket m \rrbracket, j \in \llbracket n \rrbracket Ci,j=d(LA(i),LB(j)),i∈[[m]],j∈[[n]],其中 d d d为层不相似的指标。最优CLA是满足 a ( 1 ) = 1 , a ( n ) = m a(1)=1, a(n)=m a(1)=1,a(n)=m和最小化 S ( n , m ) = ∑ i = 1 n C a ( i ) , i S(n, m)=\sum_{i=1}^n \boldsymbol{C}_{a(i), i} S(n,m)=∑i=1nCa(i),i的严格递增映射 a : ⟦ n ⟧ ↦ ⟦ m ⟧ a:\llbracket n\rrbracket \mapsto\llbracket m \rrbracket a:[[n]]↦[[m]]
上述问题是(线性)不平衡分配问题的一个特例。严格递增的条件保证了匹配时各层的顺序。如果在一维中有两个递增层表示,则可以将该问题解释为具有均匀权重的一维问题中的局部最优传输问题。然而,对层表示的不断增加的约束是相当严格的,层表示通常可能不是一维的。
跨层对齐算法: 我们提出了一种基于动态规划的高效算法来解决CLA问题。下面算法详细描述了算法的伪代码。在给定代价矩阵的情况下,其时间复杂度仅为O(mn)。注意,定义1中的最佳对齐不一定是唯一的,因此我们选择通过回溯获得的最佳对齐。

层表示: 隐藏层的恰当表示是CLA问题的关键。我们列出了两个模型的隐藏层的三种可能的层表示。第一个表示是每层神经元的数量。这促使两个神经元数量相似的层相互匹配。第二种选择是广泛用于跨层比较的(预)激活矩阵。第三种选择是预训练模型的权重矩阵。接下来,我们讨论了成本函数(层不相似)的选择。对于第一种表示,使用平方差。为了测量两个(预)激活矩阵之间的差异,我们选择了基于CKA的不相似指数,另一种选择是瓦瑟斯坦距离。最后,利用余弦距离、Kullback-Leibler散度和Wasserstein距离来表示权重矩阵。
卷积神经网络(CNN)的CLA。我们不匹配完全连接层和卷积层。自然地,卷积层与完全连接层具有不同的功能。此外,还缺乏一种合适的方法将全连通层和卷积层的权值组合起来。在本文中,我们考虑由连续卷积层和VGG和RESNET等全连接层组成的CNN体系结构。关键思想是分别解决相同类型层的CLA,然后结合两个映射。我们进一步将卷积部分分解为更小的组,并为每对组找到映射。特别地,我们将VGG按最大池化层划分为5组。在RESNET中,我们将具有相同数量通道的连续块分组,也就是阶段,并且在每个阶段中,对齐块而不是层。对于块表示,我们选择每个块中第二个卷积层的(预)激活矩阵。
2.2 层平衡方法
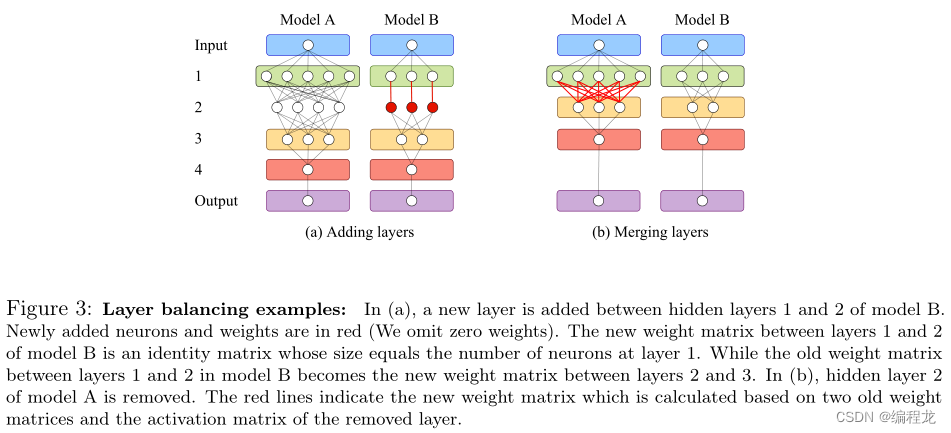
将两个模型的层进行匹配之后,我们需要考虑对那些多出来的层进行处理。也就是如果 a ( l + 1 ) − a ( l ) = 1 a(l+1) - a(l) =1 a(l+1)−a(l)=1,那么无需进行考虑,但是如果 a ( l + 1 ) − a ( l ) > 1 a(l+1) - a(l) >1 a(l+1)−a(l)>1那么我们需要对这部分进行考虑。如果大于2的话则连续执行相同的操作即可。
给模型
B
B
B添加层: 在模型b的
l
l
l和
l
+
1
l+1
l+1层之间添加一个
l
′
l^{\prime}
l′层。新的权重矩阵定义为
W
B
(
l
′
,
l
)
←
I
p
B
(
l
)
\boldsymbol{W}_B^{\left(l^{\prime},l\right)} \leftarrow \mathbb{I}_{p_B^{(l)}}
WB(l′,l)←IpB(l)和
W
B
(
l
+
1
,
l
′
)
∈
R
p
B
(
l
+
1
)
×
p
B
(
l
)
\boldsymbol{W}_B^{\left(l+1, l^{\prime}\right)} \in \mathbb{R}^{p_B^{(l+1)} \times p_B^{(l)}}
WB(l+1,l′)∈RpB(l+1)×pB(l)。新的激活函数定义为
f
B
(
l
′
)
←
f
A
(
a
(
l
)
+
1
)
f_B^{\left(l^{\prime}\right)} \leftarrow f_A^{(a(l)+1)}
fB(l′)←fA(a(l)+1),即ReLU。因为
x
B
(
l
)
⪰
0
x_B^{(l)} \succeq 0
xB(l)⪰0对于所有
l
∈
⟦
n
⟧
l \in \llbracket n \rrbracket
l∈[[n]],从方程1中我们得到:
x
B
(
l
′
)
=
f
B
(
l
′
)
(
W
B
(
l
′
,
l
)
x
B
(
l
)
)
=
Re
L
U
(
x
B
(
l
)
)
=
x
B
(
l
)
(1)
x_B^{\left(l^{\prime}\right)}=f_B^{\left(l^{\prime}\right)}\left(\boldsymbol{W}_B^{\left(l^{\prime}, l\right)} x_B^{(l)}\right)=\operatorname{Re} L U\left(x_B^{(l)}\right)=x_B^{(l)} \tag1
xB(l′)=fB(l′)(WB(l′,l)xB(l))=ReLU(xB(l))=xB(l)(1)
因此,在添加
l
′
l'
l′层后,模型B的信息保持不变。注意,新层只是一个标识映射,这是RESNET和NET2NET中使用的技巧。在NET2NET中也讨论过,添加层方法是一种函数保持转换,它允许我们生成有价值的初始化来训练更大的网络。
合并模型A中的层: 我们将模型a中的
a
(
l
)
+
1
a(l)+1
a(l)+1层直接与
a
(
l
+
1
)
a(l+1)
a(l+1)层连接,将
a
(
l
)
+
1
a(l)+1
a(l)+1层合并到模型A的
a
(
l
)
a(l)
a(l)层中。因为
f
A
(
a
(
l
)
+
1
)
f_A^{(a(l)+1)}
fA(a(l)+1)是ReLU,新的权重矩阵可以写成:
W
A
(
a
(
l
+
1
)
,
a
(
l
)
)
=
W
A
(
a
(
l
+
1
)
,
a
(
l
)
+
1
)
D
A
(
a
(
l
)
+
1
)
W
A
(
a
(
l
)
+
1
,
a
(
l
)
)
(2)
\boldsymbol{W}_A^{(a(l+1), a(l))}=\boldsymbol{W}_A^{(a(l+1), a(l)+1)} \boldsymbol{D}_A^{(a(l)+1)} \boldsymbol{W}_A^{(a(l)+1, a(l))} \tag2
WA(a(l+1),a(l))=WA(a(l+1),a(l)+1)DA(a(l)+1)WA(a(l)+1,a(l))(2)
其中
D
A
(
a
(
l
)
+
1
)
∈
R
p
A
(
a
(
l
)
+
1
)
×
p
A
(
a
(
l
)
+
1
)
\boldsymbol{D}_A^{(a(l)+1)} \in \mathbb{R}^{p_A^{(a(l)+1)} \times p_A^{(a(l)+1)}}
DA(a(l)+1)∈RpA(a(l)+1)×pA(a(l)+1)是一个输入依赖的对角线矩阵,对角线上有0和
1
1
1。如果
z
A
(
a
(
l
)
+
1
)
\boldsymbol{z}_A^{(a(l)+1)}
zA(a(l)+1)的
i
th
i^{\text {th}}
ith条目为正数,则对角线上的
i
t
h
i^{t h}
ith条目的值为1,否则为0。由于层
a
(
l
)
+
1
a(l)+1
a(l)+1上神经元
i
i
i的实际符号随输入的不同而不同,我们提供了一个简单的估计。假设神经元
i
∈
⟦
p
A
(
a
(
l
)
+
1
)
⟧
i \in \llbracket p_A^{(a(l)+1)} \rrbracket
i∈[[pA(a(l)+1)]]在t个样本上有一个预激活向量
z
,
i
∈
R
t
\boldsymbol{z}_{, i} \in \mathbb{R}^t
z,i∈Rt,它是预激活矩阵
z
A
(
a
(
l
)
+
1
)
\boldsymbol{z} _A^{(a(l)+1)}
zA(a(l)+1)的
i
t
h
i^{t h}
ith列。我们用求和的任意一个符号来估计神经元i的符号
sum
(
sgn
∑
j
=
1
t
z
j
,
i
)
\operatorname{sum}\left(\operatorname{sgn} \sum_{j=1}^t \boldsymbol{z}_{j, i}\right.)
sum(sgn∑j=1tzj,i)或多数符号(即如果至少
t
/
2
t / 2
t/2样本具有正激活值,则为1,否则为0)。
上述两个方法的利弊:合并层的一个优点是融合的模型有更少的层。但合并层会降低模型A的精度,而且速度比不需要复杂计算的添加层法要慢。另一方面,增加层数并不影响模型B的准确性,但会产生更深的融合模型。令人惊讶的是,在我们的多层感知器(MLP)实验中,合并层比添加层表现出了相对更好的性能。同样,也可以用更先进的网络扩展技术代替添加层的方法。在这里,我们只介绍两种自然而快速的方法来演示我们的框架。
平衡CNN的图层数量: 同样的合并方法在CNN中不起作用。另一方面,添加层的方法可以很容易地应用于卷积层。对于VGG,我们可以设置一个新的卷积层的所有过滤器来标识内核。对于RESNET,我们增加了一个新的块,其中两个卷积层的所有滤波器都变成了零核,而捷径连接保留为恒等映射。
2.3 多模型的融合
解决多个神经网络的CLA问题是一个非平凡的任务。在这里,我们只提出一个简单而有效的方法来将CLAFusion扩展到多个网络的情况。考虑K个预训练模型 { M i } K = 1 K \left\{M_i\right\}_{K =1}^K {Mi}K=1K。我们的方法与他们在OTFusion中所做的类似。从对融合模型 M F M_{\mathcal{F}} MF的估计开始,我们将CLAFusion K K K times的第一部分和第二部分应用于与融合模型相对的深度对齐 K K K预训练模型。之后,我们将OTFusion应用到这些深度对齐的网络中,以生成融合模型的最终权重。 M F M_{\mathcal{F}} MF的选择在这种方法中起着重要作用。然而,目前还不清楚它是如何被OTFusion选中的。在我们的实验中,选择层数最多的网络作为 M F M_{\mathcal{F}} MF的初始化。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









