







1.1引入
在人生中,我们做了多种多样的选择,高考之后选择了计算机专业,成为码农,开始996生涯抑或是进入国企,开始朝九晚五但薪资少的生活。这都是我们人生中一个又一个的决策。人生很长,我们要做一个又一个的决策。这一系列的决策我们不妨给他一个定义叫做序贯决策任务(sequential decision making)。PS:确实人生就是一个主线任务加若干个支线任务。
机器学习领域,有一类任务跟人生选择相似,即序贯决策任务。决策往往会带来“后果”,所以为了产生好的后果,我们需要采用合适的方法、策略来更好的进行序贯决策任务。在机器学习领域中,存在一类学习方法"强化学习"可以很好的进行序贯决策任务。
本文主要讨论的就是
"1.强化学习在解决什么任务
2.其数学刻画是什么。
3.学习目标。
4.跟有监督无监督学习区别"
而具体的经典的RL算法后续讨论。
1.2 什么是强化学习
广泛的讲,强化学习就是机器通过与环境进行交互来实现目标的一种计算方法。机器跟环境的一轮交互指的是机器在环境中的当前状态下根据策略产生了决策,即做出了一个动作,把这个动作作用到环境中,环境被动作影响产生改变,环境把发生的改变、奖励以及下一轮的状态传回给机器。这个交互是迭代进行的,直到这个场景结束。机器的目标是什么呢?他的目标就是在与环境的交互过程中获得更高的奖励,这个奖励是所有迭代轮次下来获得的最大奖励。
以一个例子来说,我们在打王者荣耀,操控"后羿"。那么后羿就是这个机器,但我们习惯把这个说成"智能体"。那么环境就是整场游戏的存在物,包括敌方英雄、小兵、野怪、障碍物等环境。在某个时刻,我们释放技能还是普攻抑或是移动撤退都会影响我们对线时是kill敌方英雄还是被kill。产生的奖励(获得的金币)也不相同。整场游戏的目标即为获得比赛的胜利。
智能体和环境之间具体的交互方式如图所示。在每一轮交互中,智能体感知到环境目前所处的状态,经过自身的计算给出本轮的动作,将其作用到环境中;环境得到智能体的动作后,产生相应的即时奖励信号并发生相应的状态转移。智能体则在下一轮交互中感知到新的环境状态,依次类推。
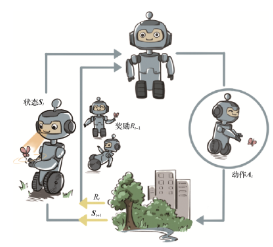
图1 强化学习中智能体和环境之间的迭代式交互
在这里,智能体有三个关键要素,分别是感知、决策、奖励。
感知:智能体在某种程度上感知环境的状态,从而知道自己所处的现状。例如,无人驾驶汽车感知旁边车辆、行人、红绿灯等;
决策:智能体根据当前的状态计算出达到目标需要采取什么动作的过程叫做决策。例如,无人车根据当前的位置、红绿灯信号、路况等信息,采取加速、减速、停止、转弯等动作。这个给出决策的方法被称为策略。
奖励:环境根据状态和智能体采取的动作,产生一个标量信号作为奖励反馈。这个标量信号衡量智能体这一轮动作的好坏。例如,无人车是否安全、平稳的行驶。最大化累积奖励期望是智能体提升策略的目标,也是衡量智能体策略好坏的关键指标。
根据这几点我们可以看出其实面向决策任务的强化学习跟有监督学习和无监督学习是不同的。
有监督学习:有监督学习是从外部监督者提供的带标注的训练集中进行学习。标注指的是根据当前情景,智能体应该做出的正确动作。但要是应用到智能体决策任务的话,我们的智能体就只能在给定场景下进行训练和应用,这并不是我们想要的。
无监督学习:无监督学习是一个典型的寻找数据集中的隐含结构的过程。但是强化学习也不找隐含结构啊,所以强化学习也不属于无监督学习。
所以那群大佬觉得强化学习是跟有监督、无监督学习并列的第三种机器学习范式。
我觉得最主要的问题还是,这是一个面向序贯决策任务的,决策任务是多轮的,智能体需要在每轮做决策时就考虑未来环境相应的改变。如果是单轮的话,我们也可以将其视为有监督的预测任务。
1.3 环境
刚才简单介绍了王者荣耀中的环境例子,以及提到"强化学习的智能体是在和一个动态环境的交互中完成序贯决策的"。环境是动态的,意思是他会随着一些因素变化而变化。举几个例子:天空因为工厂有害气体变得不再蓝,湖水因为污水变得不在清澈。以色列对巴勒斯坦开火,无数人受伤死亡......这些都是一个又一个环境的改变。环境的改变在数学里面,往往用随机过程来刻画,对于一个随机过程,其最关键的要素就是状态以及状态转移的条件概率分布。
环境自身的演变是随机的,但是也会收到一些外来因素影响。比如一个地方的湖泊只有虾,还没有鱼,他自己演变估计得几千年之后有鱼,但是有个哥们往里面投鱼苗,进程加快或者工厂排污水,虾也没了,喜提灭族。这些不确定的行为就是干扰因素。而在强化学习中,我们把这个因素定义为智能体的动作。用数学公式来表示:
![]()
这个公式表明,智能体根据![]() (当前状态)选择执行某一动作之后,环境发生改变,并返回新的状态
(当前状态)选择执行某一动作之后,环境发生改变,并返回新的状态![]()
1.4 强化学习目标
在上面的动态环境中,智能体和环境每次进行交互,环境会产生相应的奖励信号,这个奖励信号由实数标量来表示,来诠释当前状态下进行的某个动作的好坏的即时反馈信号。还是以王者为例,每个操作都会影响到我们获得的金币的多少,整个过程获得的金币即奖励是可以累加的。整个交互过程中的每一轮获得的建立信号都可以进行累加,获得智能体的整体回报。
环境是动态的,所以我们就算不改变环境和智能体策略,初始状态不变,智能体和环境产生的效果也是不同的,因此获得的回报也不一样。因此,我们关注回报的期望,将其定义为价值,这就是强化学习的优化目标。
通俗的讲就是,奖励是即时的,智能体在当前时刻就能在下一时刻立马获得反馈,他所选择的动作是好是坏。PS:这个奖励可以是正值也可以是负值。价值即表示了从长远的角度来看什么是好的,价值是从当前时刻到任务结束这个时间段的所有奖励的期望值。这个值是一个期望,并不能在下一刻得到。
那奖励和价值谁重要呢?我们在指定智能体选择动作的策略的时候更加关注的可能还是价值。以人为例,我们在此刻打游戏确实很愉快,学习强化学习内容枯燥,但等到毕业之后,我们因为自己的专业知识可能会轻松很多。
1.5 强化学习四要素
前面讲了很多,其实总结起来强化学习可以归结为四要素。
策略、奖励、价值、环境
奖励和价值在1.4已经讲过,不再提。
什么是策略,策略定义了学习智能体在特定时间的行为方式,简单地说,策略是环境状态到动作的映射。就是在某个时刻的状态下,智能体根据当前状态选择什么动作。
环境:也可以说是对环境建立的模型,这是对环境的反应模式的模拟,更一般地说,它允许对外部环境的行为进行推断。例如给定一个状态s1和动作a1,模型就会预测得到下一个状态和下一个收益。这就是一个虚拟的仿真环境。
1.6总结
大概介绍了一下强化学习的样貌,最后再对强化学习和有监督学习进行一下区分吧。梳理了强化学习和有监督学习在范式以及思维方式上的相似点和不同点。在大多数情况下,强化学习任务往往比一般的有监督学习任务更难,因为一旦策略有所改变,其交互产生的数据分布也会随之改变,并且这样的改变是高度复杂、不可追踪的,往往不能用显式的数学公式刻画。这就好像一个混沌系统,我们无法得到其中一个初始设置对应的最终状态分布,而一般的有监督学习任务并没有这样的混沌效应。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









