







Frequency Domain De-correlation Parameter in Speech Noise Reduction System Based on Frequency Domain Adaptive Line Enhancer
基于频域自适应线谱增强器的语音降噪系统的频域去相关参数
Abstract- A speech noise reduction system based on a frequency domain adaptive line enhancer has been proposed. The adaptive line enhancer (ALE) is effective to extract sinusoidal signals blurred by a broadband noise and utilizes only one microphone; therefore, it is suitable for realization of speech noise reduction in the portable electronic devices. Moreover, the noise reduction system adopts the frequency domain adaptive filter using the modified DFT pair to obtain faster convergence. In the ALE, an input signal is generated by delaying a desired signal by the de-correlation parameter, which makes a noise in the input signal de-correlated with that in the desired one. In this paper, we introduce individual de-correlation parameters in frequency domain signals and adjust them according to the dominancy of the speech element in noisy speech. Noise reduction performance is examined through computer simulations using several speeches.
摘要 - 提出了一种基于频域自适应线增强器的语音降噪系统。自适应线增强器(ALE)仅利用一个麦克风就能有效提取被宽带噪声模糊的正弦信号;因此,它适合于在便携式电子设备中实现语音降噪。此外,该降噪系统采用了频域自适应滤波器,利用改进的DFT对获得更快的收敛速度。在ALE中,输入信号是通过去相关参数延迟期望信号而产生的,这使得输入信号中的噪声与期望信号中的噪声去相关。本文在频域信号中引入单独的去相关参数,并根据带噪语音中语音元素的优势对其进行调整。对几种语音进行了计算机仿真,验证了其降噪性能。
I . \rm I. I. INTRODUCTIO
I . \rm I. I. 引言
\quad
Speech noise reduction technique has lately attracted attention as speech communication systems are widely used in our life. Adaptive digital filter (ADF) is effective for signal processing in non-stationary environments
[
1
]
[1]
[1]. For instance, the noise canceller, the system identification, the adaptive line enhancer (ALE) and so on have been proposed as applications of the ADF. Moreover, it has been proposed to apply the ALE to a speech noise reduction system
[
2
]
[2]
[2]. The ALE is to extract sinusoidal signals blurred by broadband noise and utilizes only one microphone; therefore, it is suitable for realization of speech noise reduction in the portable electronic device. However, the convergence speed of the ADF is decreased when an input signal of the ADF is colored as the speech. We have proposed to introduce the frequency domain adaptive filter (FDAF) into the ALE
[
3
]
[
4
]
[3][4]
[3][4]. The FDAF achieves faster convergence than the ADF even when an input signal is colored. Especially, in our FDAF, both an input signal and a desired one are transformed and decomposed into frequency domain signals, that is, a fundamental frequency signal and its harmonics by using the modified Discrete Fourier Transform (MDFT) [5]. The MDFT requires only real-value operations and the inverse MDFT (IMDFT) is achieved merely by summing the MDFT output. In the ALE, an input signal is generated by delaying a desired signal by the de-correlation parameter, which makes a noise in the input signal de-correlated with that in the desired one. In general, the de-correlation parameter in the ALE should be set to the fundamental period of the signal. In this paper, we propose to introduce individual de-correlation parameter in frequency domain signals.
\quad
随着语音通信系统在生活中的广泛应用,语音降噪技术越来越受到人们的关注。自适应数字滤波器(ADF)是一种有效的非平稳环境信号处理方法[1]。例如,噪声消除、系统辨识、自适应线增强(ALE)等都被认为是ADF的应用领域。此外,有人建议将ALE应用于语音降噪系统
[
2
]
[2]
[2]。ALE是一种仅利用一个麦克风来提取宽带噪声模糊的正弦信号的方法;因此,它适合于在便携式电子设备中实现语音降噪。但是,当ADF的输入信号被着色为语音信号时,ADF的收敛速度会下降。我们提出在ALE 中引入频域自适应滤波器(FDAF)
[
3
]
[
4
]
[3][4]
[3][4]。即使输入信号是彩色的,FDAF也比ADF具有更快的收敛速度。特别的是,在我们的FDAF中,通过改进的离散傅里叶变换(MDFT)[5]对输入信号和期望信号进行变换分解为频域信号,即基频信号及其谐波。MDFT只需要实值操作,而逆MDFT (IMDFT)仅通过对MDFT输出求和来实现。在ALE中,输入信号是通过去相关参数延迟期望信号而产生的,这使得输入信号中的噪声与期望信号中的噪声去相关。一般情况下,ALE中的去相关参数应设置为信号的基本周期。本文提出在频域信号中引入单独的去相关参数。
\quad
Firstly, we examine the relation between the optimal de-correlation parameter and the autocorrelation in frequency domain. Secondly, we adjust them according to the dominancy of speech element in noisy speech. The purpose of this paper is to confirm the effectiveness of the proposed frequency domain de-correlation parameter. So, in this paper, we assume that the fundamental period of speech is detectable by using the pitch detector, and speech existence and pause are detectable by using the voice activity switch. Based on the above assumptions, we set the frequency domain de-correlation parameter so as to emphasize the speech element but no to emphasize the noise element in speech pause.
\quad
首先,我们研究了最佳去相关参数与频域自相关之间的关系。其次,根据带噪语音中语音元素的支配地位对其进行调整。本文的目的是验证所提出的频域去相关参数的有效性。因此,在本文中,我们假设语音的基本周期可以通过音高检测器检测,语音存在和停顿可以通过语音活动开关检测。基于上述假设,我们设置了频域去相关参数,在语音暂停时强调语音元素而不强调噪声元素。
I I . \rm II. II. Speech Noise Reduction System
I I . \rm II. II. 语音降噪系统
\quad
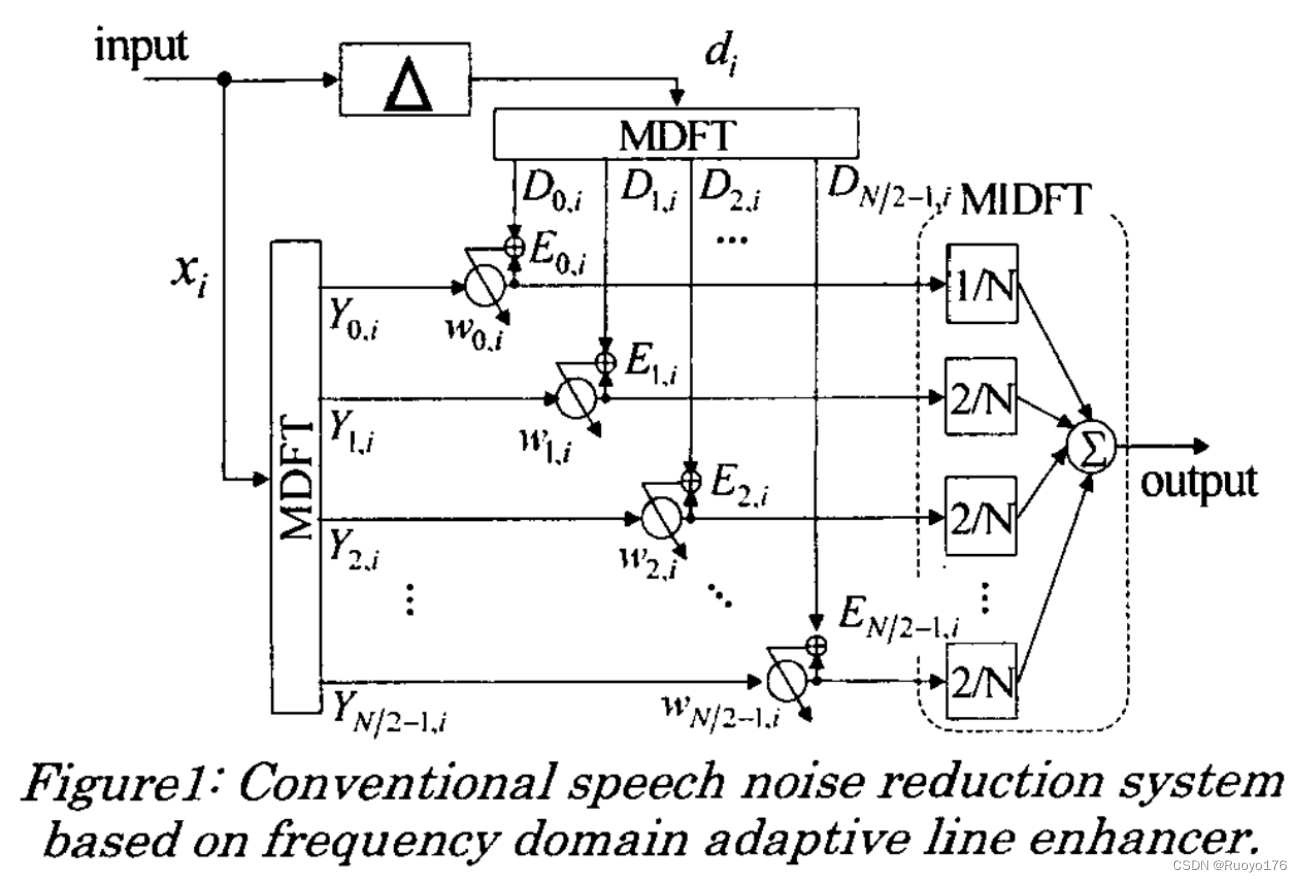
Our conventional speech noise reduction system is shown in Fig.1. The fundamental structure is based on the ALE, which is effective to extract sinusoidal signals blurred by a broadband noise. In general ALE, an input signal xi is generated by delaying a desired signal diby the de-correlation parameter A, which makes the noise in the desired signal de-correlated with that in the input signal. Therefore, only correlative sinusoidal signals can be emphasized in the ALE. However, it is well known that the convergence speed of the ADF is decreased when the input signal of the ADF is colored as speech. In order to cope with such a problem, we have adopted the frequency domain adaptive filter (FDAF) based on the modified DFT (MDFT) pair. The FDAF achieves faster convergence than the time domain ADF even if an input signal is colored [11. The MDFT is obtained by simplifying the original DFT and defined as
\quad
我们的传统语音降噪系统如图1所示。该方法的基本结构是基于ALE的,能够有效地提取被宽带噪声模糊的正弦信号。在一般的ALE中,输入信号
x
i
x_i
xi是通过去相关参数
Δ
\Delta
Δ对期望信号
d
i
d_i
di进行延迟产生的,这使得期望信号中的噪声与输入信号中的噪声去相关。因此,ALE中只能增强相关的正弦信号。但是,众所周知,当ADF的输入信号被着色为语音信号时,ADF的收敛速度会下降。为了解决这一问题,我们采用了基于改进的DFT (MDFT)对的频域自适应滤波器(FDAF)。即使输入信号是彩色的,FDAF的收敛速度也比时域ADF快[11]。MDFT是通过简化原来的DFT得到的,定义为
Y
k
,
i
=
∑
n
=
0
N
−
1
x
i
−
n
c
o
s
(
2
π
n
k
/
N
)
(
k
=
0
,
1
,
2
,
⋯
,
N
/
2
−
1
)
(
1
)
Y_{k,i} = \sum_{n=0}^{N-1}x_{i-n}cos(2\pi nk/N) (k=0,1,2,\cdots ,N/2-1) \qquad (1)
Yk,i=n=0∑N−1xi−ncos(2πnk/N)(k=0,1,2,⋯,N/2−1)(1)
The MDFT decomposes an input signal and a desired signal into a fundamental frequency signal and its harmonics. The inverse MDFT (IMDFT) is defined as
MDFT将输入信号和期望信号分解为基频信号及其谐波。逆MDFT (IMDFT)定义为
x
i
=
Y
0
,
i
N
+
2
N
∑
k
=
1
N
/
2
−
1
Y
k
,
i
(
2
)
x_i = \frac{Y_{0,i}}{N} + \frac{2}{N}\sum_{k=1}^{N/2-1} Y_{k,i} \qquad \qquad\qquad (2)
xi=NY0,i+N2k=1∑N/2−1Yk,i(2)
The MDFT pair requires only real-value operations, and the IMDFT is achieved merely by summing the MDFT output. When an input signal consists of multiple harmonic frequency signals, the MDFT decomposes it into each harmonic signal keeping the phase difference. Therefore, the adaptive signal processing can be simply achieved by adjusting the amplitude of the MDFT signal.
MDFT对只需要实值操作,而IMDFT仅通过对MDFT输出求和来实现。当一个输入信号包含多个谐波频率信号时,MDFT将其分解为每个谐波信号,保持相位差不变。因此,可以通过调整MDFT信号的幅值简单地实现自适应信号处理。
\quad
In Fig.1, r,;and Dk,i are a MDFT signal and its desired one in the frequency domain, respectively. N is the number of samples for the DFT analysis and assumed to be even hereafter. An adaptive weight Wk,; is multiplied to each MDFT signal and updated to reduce an error Ek.i between a MDFT signal and its desired one.
\quad
在图1中,r,,;和Dk,i分别为频域内的MDFT信号及其期望信号。N为DFT分析的样本数,以后假定为偶数。适应性权重Wk,;乘到每个MDFT信号,并进行更新,以减少一个错误Ek。i在一个MDFT信号和它想要的信号之间。.

The normalized step size algorithm is used for updating an adaptive weight.
采用归一化步长算法更新自适应权值。
w
k
,
i
+
1
=
w
k
,
i
+
2
μ
k
,
i
E
k
,
i
Y
(
k
=
0
,
1
,
2
,
⋯
,
N
/
2
−
1
)
(
4
)
w_{k,i+1}=w_{k,i}+2\mu _{k,i}E_{k,i}Y \quad (k=0,1,2,\cdots,N/2-1) \qquad\qquad(4)
wk,i+1=wk,i+2μk,iEk,iY(k=0,1,2,⋯,N/2−1)(4)
μ
k
,
i
=
0.5
/
(
Y
k
p
e
r
k
)
2
(
5
)
\mu_{k,i}=0.5/(Y_k^{perk})^2\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\quad(5)
μk,i=0.5/(Ykperk)2(5)
μ
k
,
i
\mu_{k,i}
μk,i is the normalized step size, and
Y
k
p
e
r
k
Y_k^{perk}
Ykperk is the maximum of each MDFT signal. Finally, all adapted MDFT outputs are summed in the IMDFT and then a noise-reduced speech signal is reconstructed.
μ
k
,
i
\mu_{k,i}
μk,i是归一化步长,
Y
k
p
e
r
k
Y_k^{perk}
Ykperk是每个MDFT信号的最大值。最后,将所有自适应MDFT输出加到IMDFT中,然后重构一个降噪语音信号。
By the way, the phase spectrum is not adjusted in the FDAF using the MDFT pair; therefore, the de-correlation parameter should be set to the fundamental period of an input signal. In general, the fundamental period of speech is changeable, so that it is necessary to adjust the de-correlation parameter according to such change. However, if the delay between an input signal and a desired one is changed dynamically, it causes discontinuity in the input signal of the FDAF and it results in degradation of the output signal. For such a reason, in our conventional system, a desired signal is delayed instead of an input signal:
顺便说一下,在FDAF中使用MDFT对不调整相位谱;因此,去相关参数应设置为输入信号的基周期。一般来说,语音的基本周期是变化的,因此需要根据这种变化来调整去相关参数。然而,如果动态地改变输入信号和期望信号之间的延迟,就会导致FDAF输入信号的不连续,并导致输出信号的退化。因此,在我们的传统系统中,所需要的信号被延迟,而不是输入信号:

















 788
788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











