






系列文章
〇、前言
EM算法(Expectation Maximization Algorithm,期望最大化算法)是一种主要用来求解参数极大似然估计的非常简单实用的学习算法。该算法是一种迭代算法,常用于含有隐变量的概率参数模型的最大似然估计或极大后验估计。当模型似然函数的解析解无法直接求出时,可使用该算法得到模型参数的局部最优解。
一、Jensen不等式
我们先简单介绍Jensen不等式,学过高数(高中数学)的人都能很容易理解。对于一个凸函数 ,如果它有二阶导数,且二阶导恒大于等于0,
,对于随机变量
,则有
这条式子就是Jensen不等式,当且仅当 ,即
为常量时,上式取等号。Jensen不等式应用于凹函数时,不等号的方向反向。
二、EM算法
假设给定训练样本 ,各样本之间是独立同分布的。我们希望找到训练样本所隐含的类别
,最大化
,这样可以写出模型的最大似然估计如下:
这里是离散的,如果是连续的就把求和号换成积分号
下面开始EM算法的推导
对于每个样本 ,假设
表示该样本所对应的隐含变量
的某种分布,并满足以下条件:
将 引入似然函数中,并考虑到似然函数是凹函数,根据Jensen不等式可得:
第二步到第三步运用了Jensen不等式,具体是:
(1)数学期望就是 , 第二步的
可以看做随机变量为
,概率分布函数为
的期望,即:
(2)运用Jensen不等式,因为 ,是凹函数,则有:
根据我们之前在上面说到的,要让等号成立
即
两边求和,因为 ,得
将这条式子代入写有“常数”的式子中,得
这样我们就找到了未知的分布 ,似然函数的下界就有了具体的表达式。
上面建立似然函数 的下界就是EM算法的E-step,接下来的M-step要做的就是在给定的
下,极大化似然函数求出
就行。这样就可以得出EM算法的一般步骤:
E-step:对每一个 计算
M-step:计算
在一开始初始化模型参数 ,重复E步和M步,直到算法收敛或参数值稳定在某一个很小的范围内,达到精度要求即可停止。
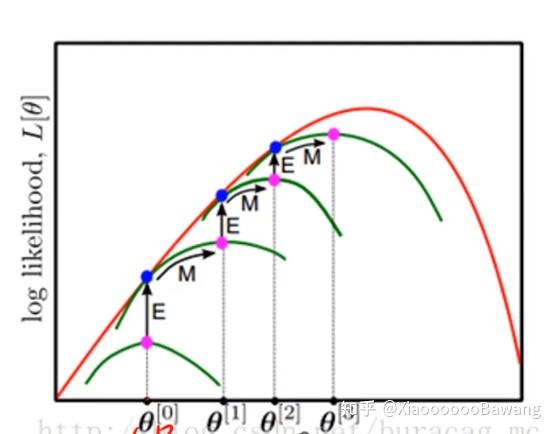

上面这张图就很好的展示EM算法在干什么,图讲得很清楚,就不解释了。
三、FA模型的EM算法求解
给定样本集 ,其中每个
都是一
维空间中的向量,为了实现对
的降维,假设:
在上一篇文章中说到, ,所以有:
这里大家可以自己用高斯分布的边缘分布与条件分布来推,或者用多元统计分析里的结论得到。
这篇文章涉及到的推导公式,具体详细的推导都可在 我的个人站的blog看到。
注意:因为我们很容易能得到 ,对于给定的数据,均值
是易求且固定的,所以为了方便后面的公式的推导和书写,我们令
(这一步就是去均值处理,对模型没影响,只要最后补上均值就行),并省去
下标
,即:
有了 和
的正态分布和对应的参数的假设,我们就可得到
之间的条件分布:
其中
还有另一个条件分布:
其中
在FA中参数 ,参数
实际有两个未知参数,它的最大似然估计不好算,因此需要使用EM 算法求解,具体步骤如下:
首先初始化参数 ,可以取任何值。(其实假设
也是一种初始化,是对隐变量的初始化)
E-step:求
M-step:算
这篇文章涉及到的推导公式,具体详细的推导都可在 我的个人站的blog看到。
通过求偏导和一系列演算,可得:
反复执行E-step和M-step,直到模型参数的值稳定在某个较小的范围内,则EM算法的迭代终止。
四、总结
EM算法用于计算模型中未知参数后验分布的点估计,这种点估计通常不包含其他信息,但它却可以估计隐变量的真实后验分布。这种算法的证明建立在Jensen不等式的基础上,通过不断优化模型似然函数的下界,找到似然函数达到极大值时对应的参数值。
因为在M-Step中是采用求导函数的方法,所以它找到的是极值点,即局部最优解,而非全局最优解。也正是因为EM算法具有局部性,所以它找到的最终解跟初始值的选取有很大关系。















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









