







Java-刷题知识点笔记-P5
1.广义表
广义表即我们通常所说的列表(lists)。它放松了对表元素的原子性限制,允许他们有自身结构。
1.1 广义表示例
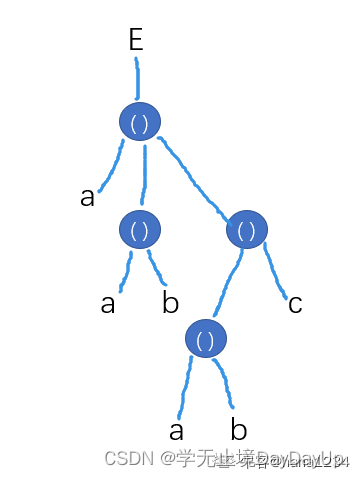
- E=()
E是一个空表,其长度为0 - L=(a,b)
L是长度为2的广义表,它的两个元素都是原子,因此它是一个线性表 - A=(x,L)=(x,(a,b))
A是长度为2的广义表,第一个元素是原子x,第二个元素是子表L。 - B=(A,y)=((x,(a,b)),y)
B是长度为2的广义表,第一个元素是子表A,第二个元素是原子y。 - C=(A,B)=((x,(a,b)),((x,(a,b)),y))
C的长度为2,两个元素都是子表。 - D=(a,D)=(a,(a,(a,(…))))
D的长度为2,第一个元素是原子,第二个元素是D自身,展开后它是一个无限的广义表。 - 由内到外依次运算:Head广义表的第一个元素(外层的括号去除),Tail取广义表除了第一个元素外的其他元素(注意外层的括号不能去除)
1.2非空广义表
- 非空广义表的第一个元素称为表头,他可以是一个单元素,也可以是一个子表;
- 除表头元素之外,由其余元素所构成的表称为表尾,非空广义表的表尾必定是一个表
1.3广义表长度和深度
广义表的长度: 若广义表不空,则广义表所包含的元素的个数,叫广义表的长度,数第一层括号内的逗号数目。
广义表的深度: 广义表中括号的最大层数叫广义表的深度。
构图为
长度:去掉一层括号剩下的是几部分。
深度:去掉几层括号可以到最后一部分。
比如: 例如E((a,(a,b),((a,b),c)))的长度和深度分别为1和4
2.线性表
线性表=顺序表+链表
2.1链表特点
- 插入、删除不需要移动元素
- 不必事先估计存储空间
- 所需空间与线性长度成正比
- 链表访问元素要从第一个节点开始遍历 ,不可随机访问任一元素
- 线性链表中,由于前一个结点包含下一个结点的指针,尾结点指针为空,要插入或删除元素,只需要改变相应位置的结点指针即可,头指针和尾指针无法决定链表长度。
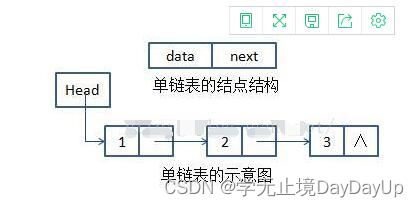
2.2单向链表
-
单链表的基本操作(判空、增、删、查)。
-
单链表头结点是一个指针,指向Node数据类型,如果头结点指示的是NULL,则该链表为空。
-
根据头结点的next指向,可以依次遍历出单链表所有节点的位置(即查找操作,但时间复杂度比较大)。
-
单链表的增删只需更改指针的指向,而查找需要从链表头依次对比(单向链表中指向头结点的指针First,可用于定位所有其他结点的位置),所以插入、删除(单向链表允许在非表头进行插入或删除操作)时间复杂度小于查找
-
判断空
不带头结点的单向链表的判空条件是head==null
带头结点单向链表的判空条件是head.next==null;
带头结点的单向循环链表的判空条件是head.next==head; -
长度不固定,可以任意增删,插入或删除节点时,只需改变相应节点的指针指向即可,无需大量移动元素,不易于存取。
-
存储空间不连续,数据元素之间使用指针相连,每个数据元素只能访问周围的一个元素(根据单链表还是双链表有所不同),所以易于扩展。
-
存储密度小,因为每个数据元素,都需要额外存储一个指向下一元素的指针(双链表则需要两个指针)。
-
要访问特定元素,链表必须从链表头开始,依次向后查找,平均需要0(n)的时间,存取速度慢。
-
如果两个单向链表相交,那他们的尾结点一定相同
-
快慢指针是判断一个单向链表有没有环的一种方法
-
有环的单向链表跟无环的单向链表不可能相交
2.3顺序表
- 在顺序表中,只要知道基地址和结点大小,就可在相同时间内求出任一结点的存储地址。
- 顺序表在计算机内存中以数组的形式保存,插入元素时,插入到的该位置以及后续位置的元素都要移动
- 存储空间可以离散分布
- 在结点等长时可以随机存取
2.4 顺序表和链表的区别和联系
顺序表:
- 空间连续,支持随机访问。
- 中间或前面部分的插入删除时间复杂度O(N)
- 增容的代价比较大
链表:
- 以节点为单位存储,不支持随机访问
- 任意位置插入时间复杂度为O(1)
- 没有增容问题
2.5循环队列
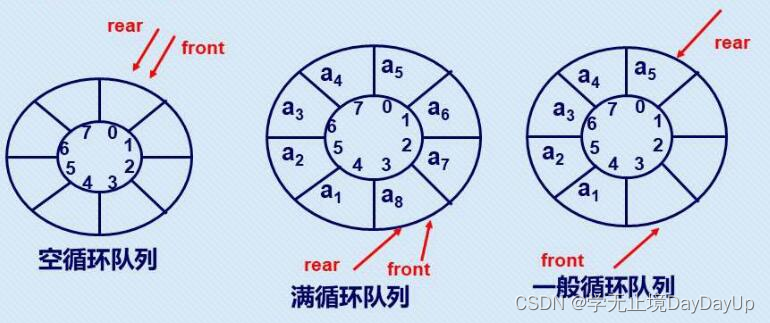
长度为SIZE的循环队列有对头指针F和队尾指针R
队列属于逻辑结构的概念,它们的物理存储既可以利用数组也可以利用链表完成,所以循环队列属于逻辑上首尾相接的抽象圆环,如上图所示。
- 空队列头尾指针指向同一个区域(0区域),所以
F==R; - 满队列是随着元素的入队,尾指针逐渐加1,直到从0区域加到SIZE-1区域,这时尾指针指向SIZE-1区域,头指针指向0区域。判断队满的条件是尾指针再加1(由于是循环)所以头尾指针重合在0区域,
(R+1)%SIZE==F - front=rear 不为空时带链的队列中只有一个元素
- 在循环队列中,队头指针和队尾指针的动态变化决定队列的长度。
循环队列的相关条件和公式:
队尾指针是rear,队头是front,其中QueueSize为循环队列的最大长度
1.队空条件:rear==front
2.队满条件:(rear+1) %QueueSIze==front
3.计算队列长度:(rear-front+QueueSize)%QueueSize
4.入队:(rear+1)%QueueSize
5.出队:(front+1)%QueueSize
2.6栈
-
和顺序栈相比,链栈有一个比较明显的优势是:通常不会出现栈满的情况
-
前缀表达式的计算机求值特点:
从右至左扫描表达式,遇到数字时,将数字压入堆栈,遇到运算符时,弹出栈顶的两个数,用运算符对它们做相应的计算(栈顶元素 op 次顶元素),并将结果入栈;重复上述过程直到表达式最左端,最后运算得出的值即为表达式的结果。 -
若一序列进栈顺序为e1,e2,e3,e4,e5,问存在多少种可能的出栈序列()
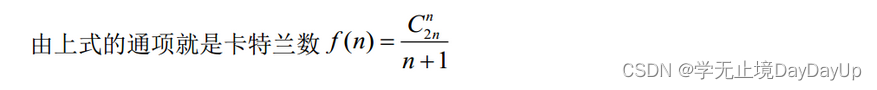
-
栈的典型应用:表达式求值,括号匹配,递归函数调用,数制转换、高级编程语言的过程调用等
-
在栈中,栈底指针保持不变,有元素入栈,栈顶指针增加,有元素出栈,栈顶指针减少。
2.7循环双链表
先搭后拆
在循环双链表的 p 所指的结点之前插入 s 所指结点的操作是
s->next = p;s->prior = p->prior;p->prior->next = s;p->prior = s

2.8 栈 和 堆区别
-
==栈区(stack)由编译器自动分配释放 ==,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
-
堆区(heap)一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事。
-
管理方式:
对于栈来讲,是由编译器自动管理,无需我们手工控制;
对于堆来说,释放工作由程序员控制,容易产生内存溢出。 -
空间大小:
栈一般都是有一定的空间大小。
堆内存几乎是没有什么限制。 -
碎片问题:
对于栈来讲,则不会存在这个问题。
对于堆来讲,频繁的new/delete会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。 -
分配方式:
栈有2种分配方式:静态分配和动态分配。
堆都是动态分配的,没有静态分配的堆。 -
分配效率:
栈的效率比较高。
堆的效率比栈要低得多。 -
增长方向:
堆的增长方向是从程序低地址到高地址向上增长,
栈是连续的,生长方向是向下的,即向着内存地址减小的方向增长
3.堆
3.1大顶堆
- 大顶堆,在n位置上的数要比在2n+1和2n+2位置上的数大
3.2小顶堆
- i 位置的数,小于 2i 和 2i + 1 位置上的数
- 创建最小堆,从下往上,从右到左的顺序,从第一个非叶结点开始调整。
- 筛选法就是开始按现有的顺序从上到下,从左到右放到一个完全二叉树里面。















 1086
1086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









