







Follow Your Heart:面临太多的选择,人总会迷茫,有好有坏,理性的选择往往是最好的选择,但往往会有人选择感性,遵从自己的内心,哪怕举步维艰,不知道是成功还是失败,还是想这样选择,可能有些人有些事有些东西值得你付出,但愿这一切都会变得好起来。
一、神经网络
初步接触神经网络,感觉被高大上名词给吓住了,高深莫测的CNN,DNN,让人望而却步。
简单来说神经网络是用来预测数据的一种模型,而这种模型是由一个个神经元组成,共同对数据进行训练决策,输出结果。一个神经元会接收信号,输出信号。
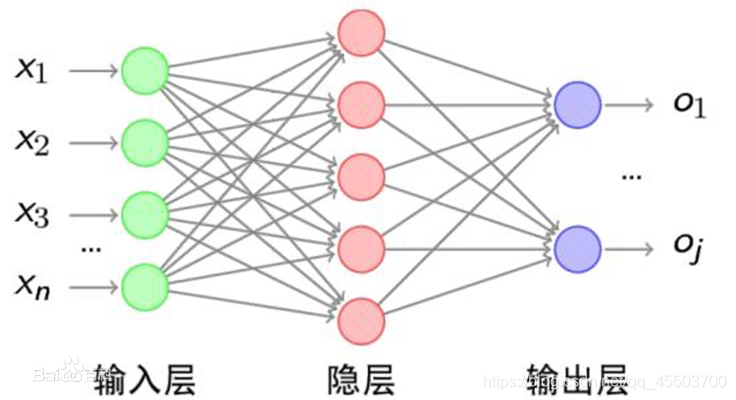
二、 搭建神经网络
构建神经网络的一般方法是:
- 定义神经网络结构(输入单元的数量,隐藏单元的数量等)。
- 初始化模型的参数
- 循环:
- 实施前向传播
- 计算损失
- 实现向后传播
- 更新参数(梯度下降)
搭建一个两层神经网络
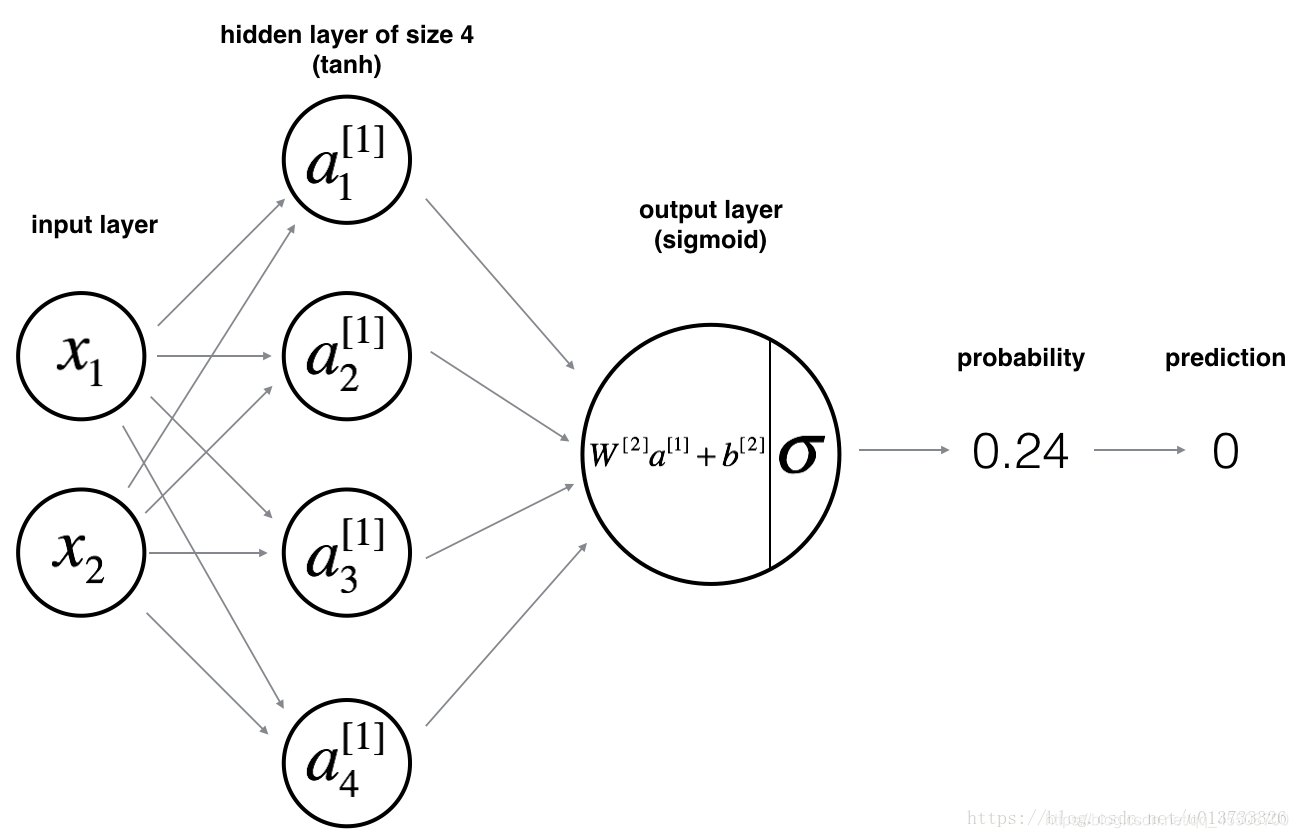
1. 向前传播计算Z,A
计算Z和A
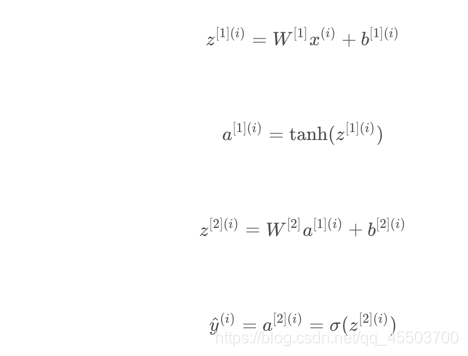
代码:
def initialize_parameters(n_x, n_h, n_y):
"""
参数:
n_x - 输入层节点的数量
n_h - 隐藏层节点的数量
n_y - 输出层节点的数量
返回:
parameters - 包含参数的字典:
W1 - 权重矩阵,维度为(n_h,n_x)
b1 - 偏向量,维度为(n_h,1)
W2 - 权重矩阵,维度为(n_y,n_h)
b2 - 偏向量,维度为(n_y,1)
"""
np.random.seed(2) # 指定一个随机种子,以便你的输出与我们的一样。
W1 = np.random.randn(n_h, n_x) * 0.01
b1 = np.zeros(shape=(n_h, 1))
W2 = np.random.randn(n_y, n_h) * 0.01
b2 = np.zeros(shape=(n_y, 1))
# 使用断言确保我的数据格式是正确的
assert (W1.shape == (n_h, n_x))
assert (b1.shape == (n_h, 1))
assert (W2.shape == (n_y, n_h))
assert (b2.shape == (n_y, 1))
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
def forward_propagation( X , parameters ):
"""
参数:
X - 维度为(n_x,m)的输入数据。
parameters - 初始化函数(initialize_parameters)的输出
返回:
A2 - 使用sigmoid()函数计算的第二次激活后的数值
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型变量
"""
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
#前向传播计算A2
Z1 = np.dot(W1 , X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2 , A1) + b2
A2 = sigmoid(Z2)
#使用断言确保我的数据格式是正确的
assert(A2.shape == (1,X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return (A2, cache)
2. 向前传播计算Cost
计算Cost
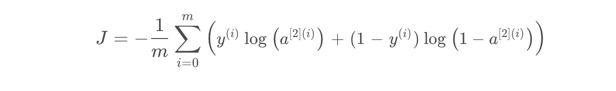
代码:
def compute_cost(A2,Y,parameters):
"""
计算方程(6)中给出的交叉熵成本,
参数:
A2 - 使用sigmoid()函数计算的第二次激活后的数值
Y - "True"标签向量,维度为(1,数量)
parameters - 一个包含W1,B1,W2和B2的字典类型的变量
返回:
成本 - 交叉熵成本给出方程(13)
"""
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
#计算成本
logprobs = logprobs = np.multiply(np.log(A2), Y) + np.multiply((1 - Y), np.log(1 - A2))
cost = - np.sum(logprobs) / m
cost = float(np.squeeze(cost))
assert(isinstance(cost,float))
return cost
3. 向后传播

代码:
def backward_propagation(parameters,cache,X,Y):
"""
使用上述说明搭建反向传播函数。
参数:
parameters - 包含我们的参数的一个字典类型的变量。
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型的变量。
X - 输入数据,维度为(2,数量)
Y - “True”标签,维度为(1,数量)
返回:
grads - 包含W和b的导数一个字典类型的变量。
"""
m = X.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
A1 = cache["A1"]
A2 = cache["A2"]
dZ2= A2 - Y
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2 }
return grads
三、完整运行与代码
#!/usr/bin/python
# -*- coding: UTF-8 -*-
"""
@company:UDAI
@author:tianjian
@file:network.py
@time:2021/05/10
"""
import numpy as np
import pandas as pd
def sigmoid(x):
s = 1 / (1 + np.exp(-x))
return s
def layer_sizes(X, Y):
"""
参数:
X - 输入数据集,维度为(输入的数量,训练/测试的数量)
Y - 标签,维度为(输出的数量,训练/测试数量)
返回:
n_x - 输入层的数量
n_h - 隐藏层的数量
n_y - 输出层的数量
"""
n_x = X.shape[0] # 输入层
n_h = 4 # ,隐藏层,硬编码为4
n_y = Y.shape[0] # 输出层
return (n_x, n_h, n_y)
def initialize_parameters(n_x, n_h, n_y):
"""
参数:
n_x - 输入层节点的数量
n_h - 隐藏层节点的数量
n_y - 输出层节点的数量
返回:
parameters - 包含参数的字典:
W1 - 权重矩阵,维度为(n_h,n_x)
b1 - 偏向量,维度为(n_h,1)
W2 - 权重矩阵,维度为(n_y,n_h)
b2 - 偏向量,维度为(n_y,1)
"""
np.random.seed(2) # 指定一个随机种子,以便你的输出与我们的一样。
W1 = np.random.randn(n_h, n_x) * 0.01
b1 = np.zeros(shape=(n_h, 1))
W2 = np.random.randn(n_y, n_h) * 0.01
b2 = np.zeros(shape=(n_y, 1))
# 使用断言确保我的数据格式是正确的
assert (W1.shape == (n_h, n_x))
assert (b1.shape == (n_h, 1))
assert (W2.shape == (n_y, n_h))
assert (b2.shape == (n_y, 1))
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
def forward_propagation(X, parameters):
"""
参数:
X - 维度为(n_x,m)的输入数据。
parameters - 初始化函数(initialize_parameters)的输出
返回:
A2 - 使用sigmoid()函数计算的第二次激活后的数值
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型变量
"""
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# 前向传播计算A2
Z1 = np.dot(W1, X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = sigmoid(Z2)
# 使用断言确保我的数据格式是正确的
assert (A2.shape == (1, X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return (A2, cache)
def compute_cost(A2, Y, parameters):
"""
计算方程(6)中给出的交叉熵成本,
参数:
A2 - 使用sigmoid()函数计算的第二次激活后的数值
Y - "True"标签向量,维度为(1,数量)
parameters - 一个包含W1,B1,W2和B2的字典类型的变量
返回:
成本 - 交叉熵成本给出方程(13)
"""
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
# 计算成本
logprobs = logprobs = np.multiply(np.log(A2), Y) + np.multiply((1 - Y), np.log(1 - A2))
cost = - np.sum(logprobs) / m
cost = float(np.squeeze(cost))
assert (isinstance(cost, float))
return cost
def backward_propagation(parameters, cache, X, Y):
"""
使用上述说明搭建反向传播函数。
参数:
parameters - 包含我们的参数的一个字典类型的变量。
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典类型的变量。
X - 输入数据,维度为(2,数量)
Y - “True”标签,维度为(1,数量)
返回:
grads - 包含W和b的导数一个字典类型的变量。
"""
m = X.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
A1 = cache["A1"]
A2 = cache["A2"]
dZ2 = A2 - Y
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2}
return grads
def update_parameters(parameters, grads, learning_rate=1.2):
"""
使用上面给出的梯度下降更新规则更新参数
参数:
parameters - 包含参数的字典类型的变量。
grads - 包含导数值的字典类型的变量。
learning_rate - 学习速率
返回:
parameters - 包含更新参数的字典类型的变量。
"""
W1, W2 = parameters["W1"], parameters["W2"]
b1, b2 = parameters["b1"], parameters["b2"]
dW1, dW2 = grads["dW1"], grads["dW2"]
db1, db2 = grads["db1"], grads["db2"]
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
def nn_model(X, Y, n_h, num_iterations, print_cost=False):
"""
参数:
X - 数据集,维度为(2,示例数)
Y - 标签,维度为(1,示例数)
n_h - 隐藏层的数量
num_iterations - 梯度下降循环中的迭代次数
print_cost - 如果为True,则每1000次迭代打印一次成本数值
返回:
parameters - 模型学习的参数,它们可以用来进行预测。
"""
np.random.seed(3) # 指定随机种子
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
parameters = initialize_parameters(n_x, n_h, n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
print("initialize_parameters is {}".format(parameters))
for i in range(num_iterations):
A2, cache = forward_propagation(X, parameters)
cost = compute_cost(A2, Y, parameters)
grads = backward_propagation(parameters, cache, X, Y)
parameters = update_parameters(parameters, grads, learning_rate=0.3)
if print_cost:
if i % 500 == 0:
print("第 ", i, " 次循环,成本为:" + str(cost))
return parameters
def predict(parameters, X):
"""
使用学习的参数,为X中的每个示例预测一个类
参数:
parameters - 包含参数的字典类型的变量
X - 输入数据(n_x,m)
返回
predictions - 我们模型预测的向量(红色:0 /蓝色:1)
"""
A2, cache = forward_propagation(X, parameters)
predictions = np.round(A2)
return predictions
if __name__ == '__main__':
data = pd.read_csv("/Users/tian/Projects/my_learning/算法/data/my_data_guest.csv")
X = data.iloc[:, 2:].values.T
Y = data.iloc[:, 1].values.reshape(1, -1)
parameters = nn_model(X, Y, n_h=4, num_iterations=5000, print_cost=True)
predictions = predict(parameters, X)
print('准确率: %d' % float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100) + '%')
结果:
initialize_parameters is w1:(4, 12),b1:(4, 1),w2:(1, 4),b2:(1, 1)
第 0 次循环,成本为:0.6931408605278057
第 500 次循环,成本为:0.4838800210980355
第 1000 次循环,成本为:0.4711467204406175
第 1500 次循环,成本为:0.4674346759771225
第 2000 次循环,成本为:0.4667805426351949
第 2500 次循环,成本为:0.46655892747687916
第 3000 次循环,成本为:0.4664142526117049
第 3500 次循环,成本为:0.4661852602735777
第 4000 次循环,成本为:0.46571144989740265
第 4500 次循环,成本为:0.46486402363012647
准确率: 81%
参考
https://blog.csdn.net/u013733326/article/details/79702148
https://mooc.study.163.com/learn/2001281002?tid=2403041000&trace_c_p_k2=19be870afe394ccab70e07eff9f18a61#/learn/announce














 9422
9422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









