







一、Torch.NN简介
torch.nn 是 PyTorch 中用于构建神经网络的模块。它提供了一组类和函数,用于定义、训练和评估神经网络模型。
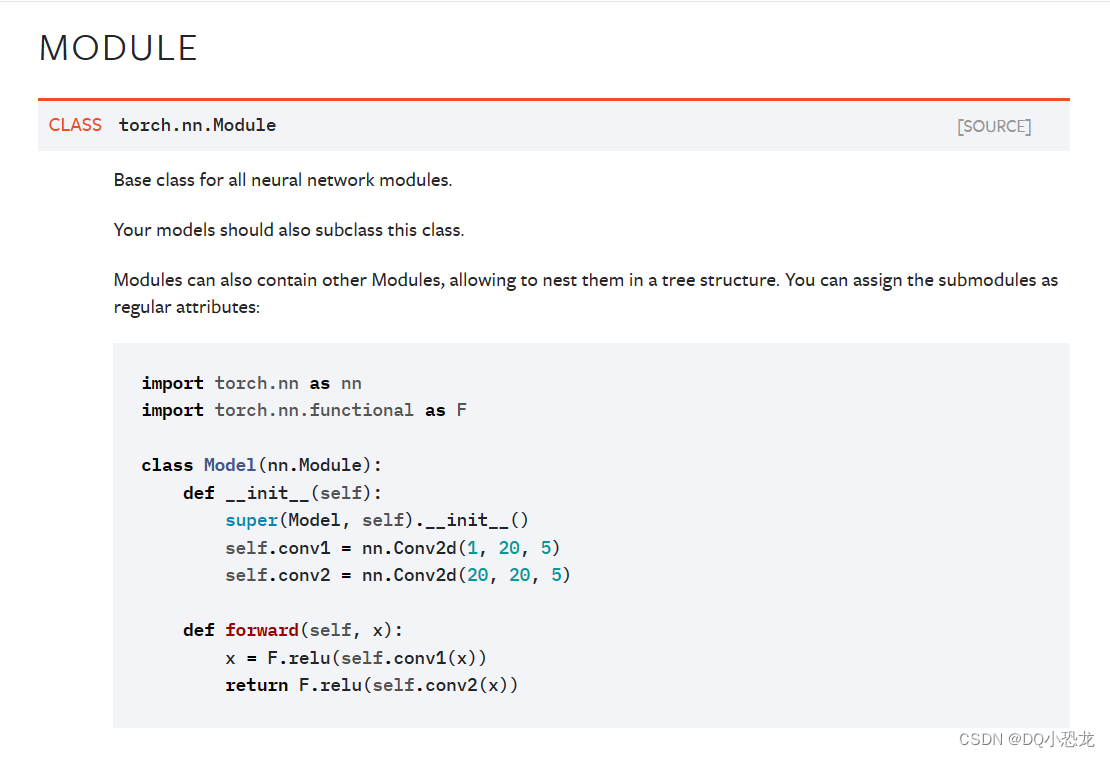
torch.nn 模块的核心是 nn.Module 类,它是所有神经网络模型的基类。在Containers中
通过继承 nn.Module 类,您可以创建自己的神经网络模型,并定义模型的结构和操作。
以下是 torch.nn 模块中常用的一些类和函数:
nn.Linear: 线性层,用于定义全连接层。nn.Conv2d: 二维卷积层,用于处理图像数据。nn.ReLU: ReLU 激活函数。nn.Sigmoid: Sigmoid 激活函数。nn.Dropout: Dropout 层,用于正则化和防止过拟合。nn.CrossEntropyLoss: 交叉熵损失函数,通常用于多类别分类问题。nn.MSELoss: 均方误差损失函数,通常用于回归问题。nn.Sequential: 顺序容器,用于按顺序组合多个层。
使用 torch.nn 模块,您可以创建自定义的神经网络模型,并使用 PyTorch 提供的优化器(如 torch.optim)和损失函数来训练和优化模型。

Module
二、简单示例
import torch.nn as nn class DQLD(nn.Module): def __init__(self): super().__init__() def forword(self,input): output = input + 1 return output dqld = DQLD() output = dqld.forword(1.0) print(output)
继承nn.Module类,重写init并调用父类init,重写forward前向传播方法,本示例中只进行了加1操作,当然可以进行卷积等操作,再进行输出。
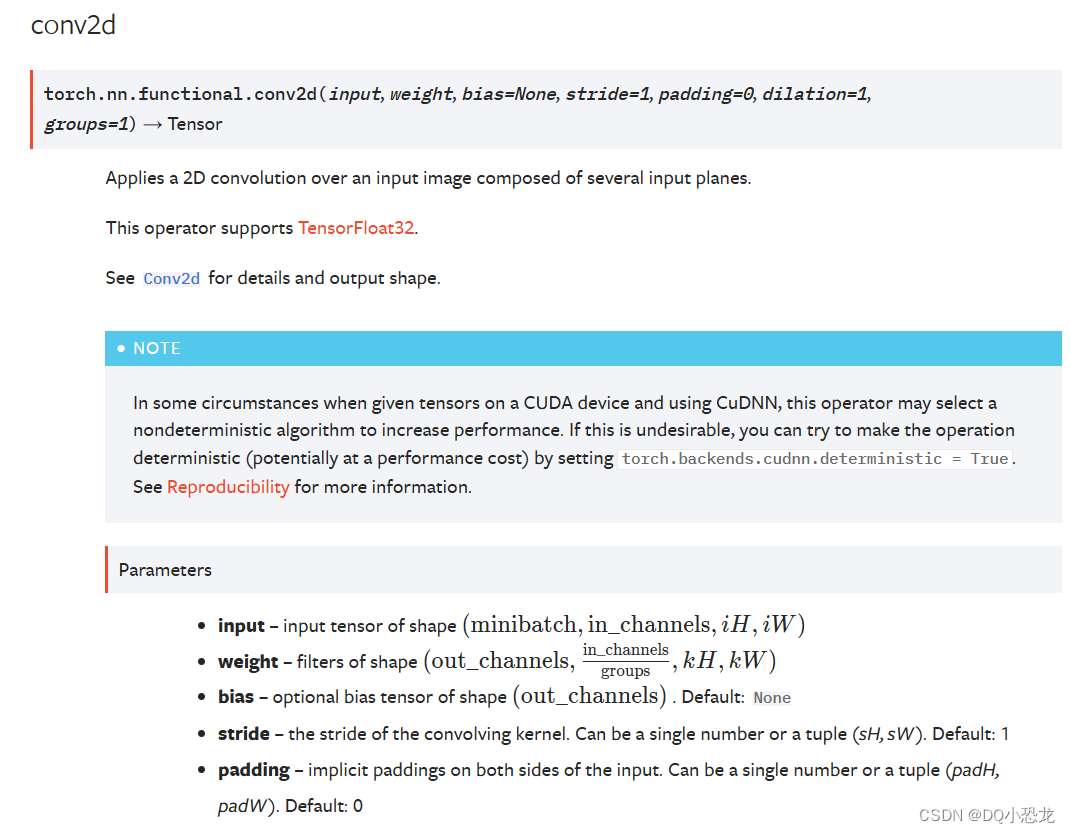
三、卷积介绍-conv2d
3.1conv2d二维卷积

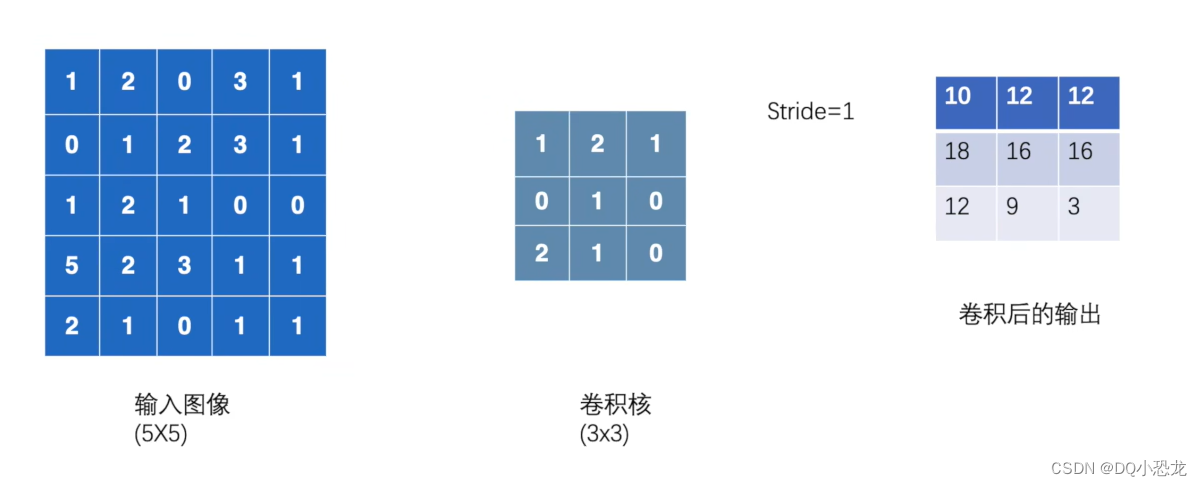
3.2示例
代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
input = torch.Tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.Tensor([[1,2,1],
[0,1,0],
[2,1,0]])
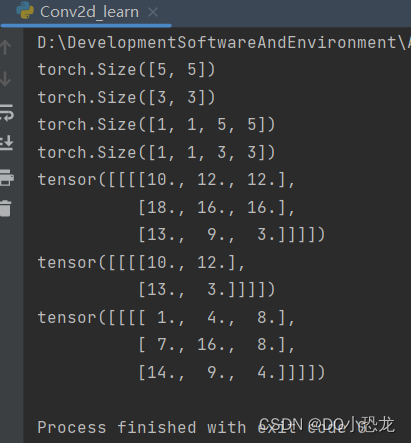
print(input.shape)
print(kernel.shape)
input = torch.reshape(input,[1,1,5,5])
kernel = torch.reshape(kernel,[1,1,3,3])
print(input.shape)
print(kernel.shape)
output = F.conv2d(input,kernel,stride=1)
print(output)
output = F.conv2d(input,kernel,stride=2)
print(output)
#padding参数表示在输入矩阵的一周扩充几个维度再进行运算,一般扩充填充值为0
output = F.conv2d(input,kernel,padding=1,stride=2)
print(output)结果:
四、卷积层
4.1简介
卷积层是卷积神经网络(CNN)中的核心组件之一,它在图像处理和其他领域的深度学习任务中发挥着重要作用。卷积层通过卷积操作对输入数据进行特征提取和特征映射,具有以下几个主要作用:
-
特征提取:卷积层通过卷积操作从输入数据中提取有用的特征。卷积操作通过滑动窗口的方式在输入数据上进行局部采样,并使用卷积核(也称为滤波器)与采样到的数据进行卷积运算。这样可以检测出输入数据中的边缘、纹理、形状等低级特征。
-
特征映射:卷积层通过应用多个卷积核并对它们的输出进行叠加,生成多个特征映射(feature map)。每个特征映射对应一个卷积核,它可以捕捉输入数据中不同方面的特征。通过多个卷积核的组合,卷积层可以提取更加丰富和抽象的特征。
-
参数共享:卷积层通过参数共享的机制减少了需要学习的参数数量。在卷积操作中,卷积核的权重在整个输入数据上共享,这意味着在不同位置采样到的数据使用相同的权重进行卷积运算。参数共享有效地减少了模型的复杂性,提高了模型的泛化能力。
-
空间不变性:卷积层在进行卷积操作时保持输入数据的空间结构。这意味着无论输入数据中的特征出现在图像的哪个位置,卷积层都能够检测到它们。这种空间不变性使得卷积层在处理图像等具有平移不变性的数据时非常有效。
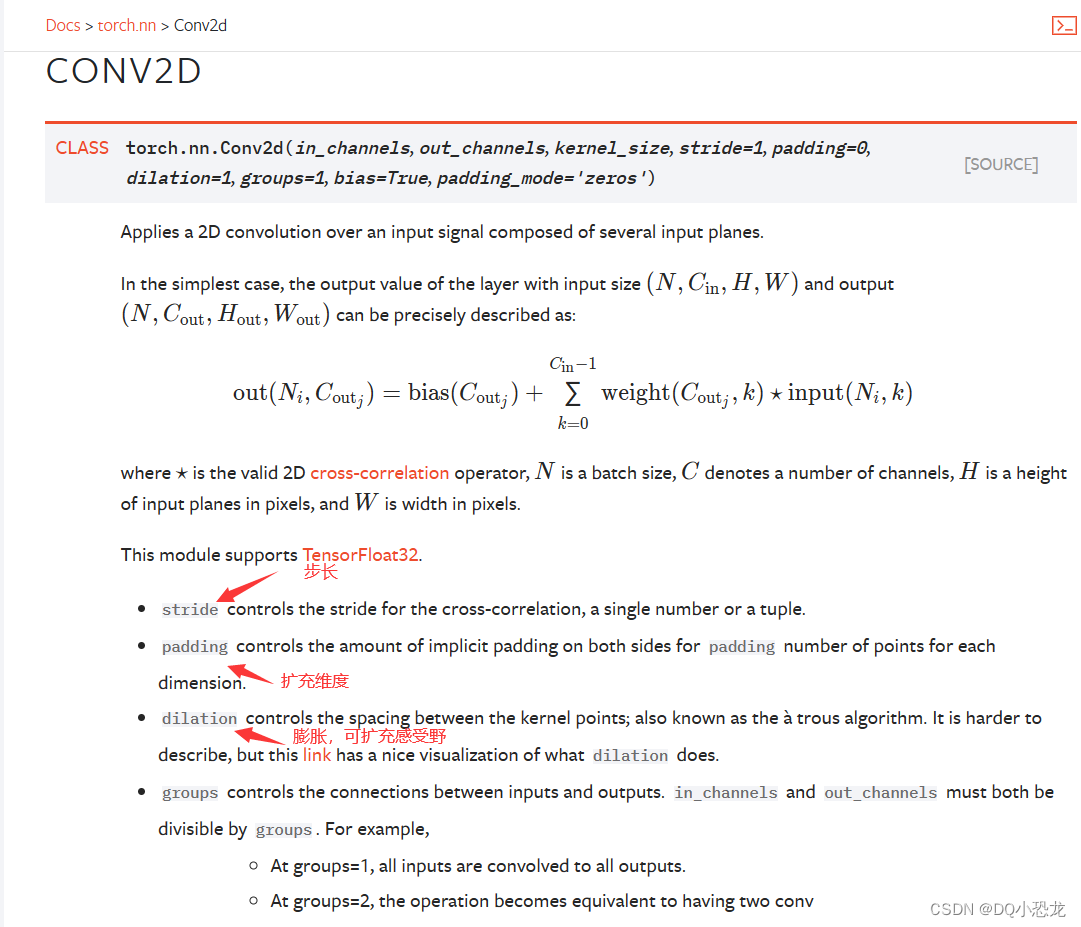
4.2官方文档

4.3示例
代码:DQLD卷积层
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_set = torchvision.datasets.CIFAR10("../dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(test_set,batch_size=16,shuffle=True,num_workers=0)
writer = SummaryWriter("../DQLD_logs")
class DQLQ(nn.Module):
def __init__(self):
super(DQLQ,self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=1)
def forward(self,x):
x = self.conv1(x)
return x
dqlq = DQLQ()
step = 0
for data in dataloader:
imgs,targets = data
# print(imgs.shape)->torch.Size([16, 3, 32, 32])
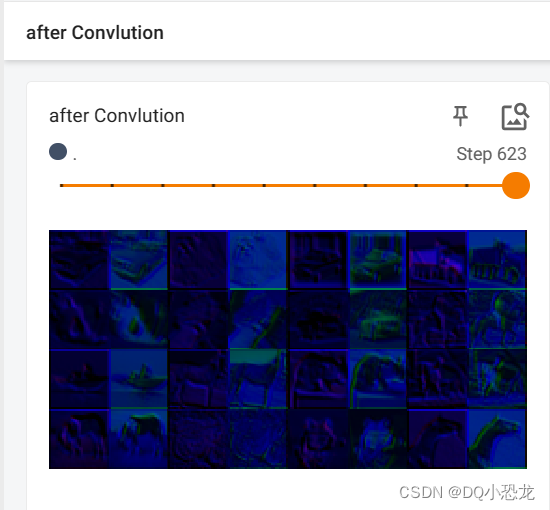
writer.add_images("befor Convlution",imgs,step)
imgs = dqlq(imgs)
# print(imgs.shape)->torch.Size([16, 6, 32, 32])
# print(imgs.shape)
#reshape()第一个参数为-1则batch_size则根据后面的参数进行计算得出
imgs = torch.reshape(imgs,(-1,3,32,32))
# print(imgs.shape)->torch.Size([32, 3, 32, 32])
writer.add_images("after Convlution",imgs,step)
step = step + 1
结果:

五、池化层
5.1简介
池化层(Pooling Layer)是卷积神经网络(CNN)中常用的一种层类型,用于减小特征图的空间尺寸并提取关键特征。池化层通常紧跟在卷积层之后,其主要作用包括以下几个方面:
-
降采样:池化层通过对输入特征图进行降采样,减小特征图的空间尺寸。这有助于减少模型的参数数量和计算量,同时可以提高模型的计算效率。
-
特征选择:池化层通过对输入特征图进行汇聚操作,选取最显著的特征。常用的汇聚操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。最大池化选取池化窗口中的最大值作为输出,而平均池化则计算池化窗口中值的平均值作为输出。这样可以保留重要的特征并减少冗余信息。
-
平移不变性:池化层具有一定的平移不变性,即无论特征出现在输入特征图的哪个位置,池化层都能够检测到它们。这种平移不变性使得模型对目标在图像中的具体位置不敏感,提高了模型的鲁棒性。
-
尺度不变性:池化层可以使模型对输入数据的尺度变化具有一定的不变性。通过对输入特征图进行降采样,池化层可以在一定程度上对输入数据的尺度变化进行适应。
需要注意的是,池化层没有可训练的参数,它主要通过设置池化窗口的大小和步幅来控制降采样的程度和特征选择的效果。
总结起来,池化层在卷积神经网络中用于降采样、特征选择和提高模型的平移不变性和尺度不变性。它通过对输入特征图进行汇聚操作来减小特征图的空间尺寸,并选取重要的特征。池化层没有可训练的参数,它的操作主要由池化窗口的大小和步幅决定。
说白了保留特征并且减少数据量
5.2官方文档


5.3示例
5.3.1一维数据示例
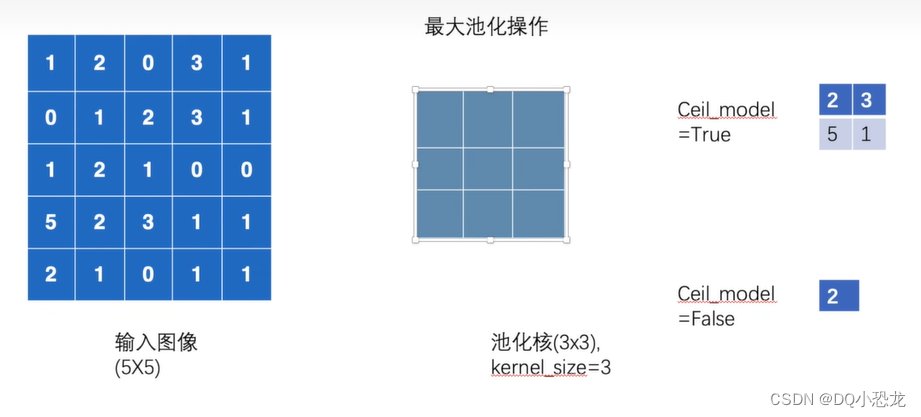
代码:
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]]],dtype=torch.float)
torch.reshape(input,(-1,1,5,5))
print(input.shape)
class DQLD(nn.Module):
def __init__(self):
super(DQLD,self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
dqld = DQLD()
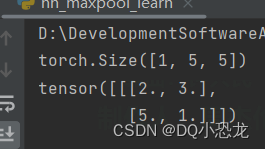
output = dqld(input)
print(output)结果:ceil_mode = True ceil_mode = False

5.2.2图片示例
CIFAR10数据集为例
代码:
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_set = torchvision.datasets.CIFAR10("../dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(test_set,64,shuffle=True)
writer = SummaryWriter("../MaxPool_logs")
class DQLD(nn.Module):
def __init__(self):
super(DQLD,self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
dqld = DQLD()
step = 0
for data in dataloader:
imgs,targets = data
writer.add_images("Before MaxPool",imgs,step)
output = dqld(imgs)
writer.add_images("After MaxPool",output,step)
step = step + 1
结果:
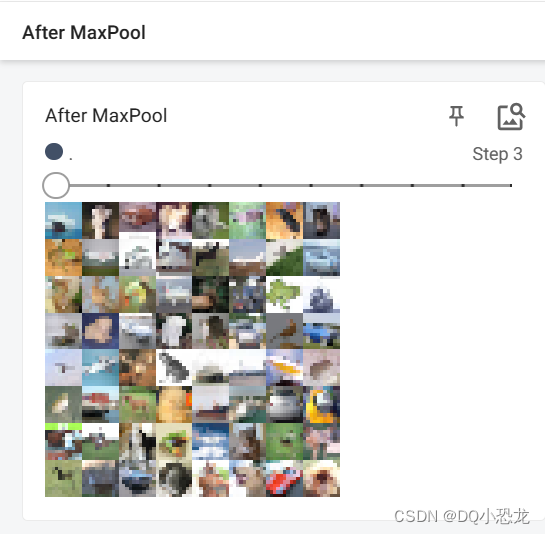
六、非线性激活
6.1简介
非线性激活函数是神经网络中常用的一种组件,用于引入非线性变换,增加模型的表达能力。在神经网络的每个神经元中,非线性激活函数将神经元的输入进行非线性变换,产生神经元的输出。
常见的非线性激活函数包括:
-
Sigmoid函数(Logistic函数):Sigmoid函数将输入值映射到0到1之间的连续范围。它的公式为 f(x) = 1 / (1 + exp(-x))。Sigmoid函数在早期的神经网络中广泛使用,但在一些情况下可能存在梯度消失的问题。
-
双曲正切函数(Tanh函数):Tanh函数将输入值映射到-1到1之间的连续范围。它的公式为 f(x) = (exp(x) - exp(-x)) / (exp(x) + exp(-x))。Tanh函数与Sigmoid函数类似,但输出范围更广,可以更好地处理负数输入。
-
ReLU函数(Rectified Linear Unit函数):ReLU函数将负数输入映射为0,而正数输入保持不变。它的公式为 f(x) = max(0, x)。ReLU函数在实践中被广泛使用,因为它简单且有效,可以缓解梯度消失的问题。
-
Leaky ReLU函数:Leaky ReLU函数是ReLU函数的变种,它在负数输入时引入一个小的斜率,以解决ReLU函数在负数区域的输出为0的问题。它的公式为 f(x) = max(0.01x, x)。
-
ELU函数(Exponential Linear Unit函数):ELU函数在负数输入时引入一个指数衰减的负值,以解决ReLU函数的一些问题。它的公式为 f(x) = x if x >= 0, alpha * (exp(x) - 1) if x < 0,其中alpha是一个小的正数。
这些非线性激活函数可以帮助神经网络学习复杂的非线性关系,并提高模型的表达能力。在实际应用中,选择适当的非线性激活函数通常取决于任务的性质和数据的特点。
6.2示例
6.2.1ReLu函数

6.2.2ReLu激活函数数据示例

代码:
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[[1,-1],
[2,-3]]])
torch.reshape(input,(-1,1,2,2))
print(input.shape)
class DQLD(nn.Module):
def __init__(self):
super(DQLD,self).__init__()
# 此处ReLu(implace= True/False)若为True则会将连同原数据一同更改,False则不会更改原数据
self.relu1 = ReLU()
def forward(self,input):
output= self.relu1(input)
return output
dqld = DQLD()
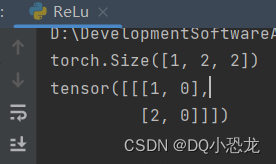
output = dqld(input)
print(output)
结果:
6.2.3图片示例-sigmoid函数
代码:
import torch
import torchvision
from torch import nn
from torch.nn import ReLU
from torch.nn import Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_set = torchvision.datasets.CIFAR10("../dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(test_set,64)
writer = SummaryWriter("../sigmoid_logs")
class DQLD(nn.Module):
def __init__(self):
super(DQLD,self).__init__()
# 此处ReLu(implace= True/False)若为True则会将连同原数据一同更改,False则不会更改原数据
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self,input):
output= self.sigmoid1(input)
return output
dqld = DQLD()
step = 0
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
output = dqld(imgs)
writer.add_images("output",output,step)
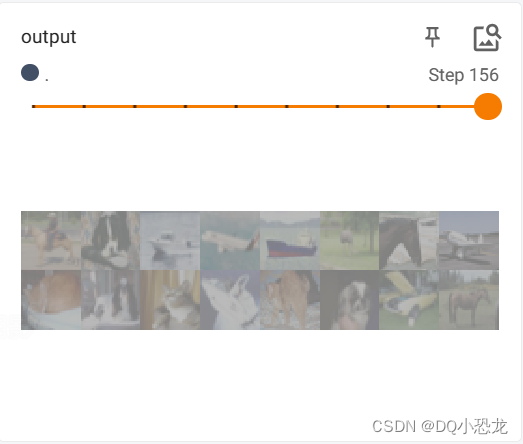
step = step + 1
writer.close()结果:引入非线性特征增加模型鲁棒性

七、线性层
7.1简介
在机器学习和深度学习中,线性层(Linear Layer)通常指的是全连接层(Fully Connected Layer),也称为密集层(Dense Layer)或仿射层(Affine Layer)。
线性层是神经网络中最常见的一种层类型之一,它将输入的每个特征与一组可学习的权重进行线性组合,并添加一个可学习的偏置项。线性层的输出是输入特征与权重的加权和,可以表示为:
output = input * weight^T + bias
其中,input是输入特征向量,weight是权重矩阵,bias是偏置向量,^T表示权重矩阵的转置。
线性层的作用是将输入特征映射到输出空间,通过学习适当的权重和偏置,使得网络能够学习输入特征之间的非线性关系。线性层通常紧跟在卷积层或池化层之后,用于将高维特征转换为更低维的表示,或将特征向量映射到特定的输出空间。
7.2示例
不是很理解其作用
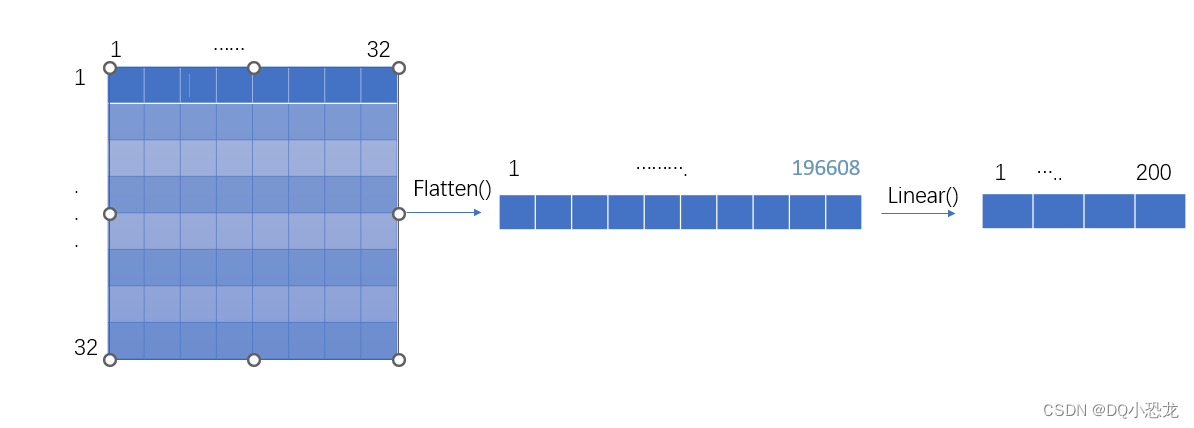
代码:
import torchvision
import torch
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torch import nn
from torch.nn import Linear
test_set = torchvision.datasets.CIFAR10("../dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(test_set,batch_size=64,shuffle=False)
writer = SummaryWriter("../liear_logs")
class DQ(nn.Module):
def __init__(self):
super(DQ,self).__init__()
self.linear1 = Linear(196608,200)
def forward(self,input):
output = self.linear1(input)
return output
dq = DQ()
step = 0
for data in dataloader:
imgs,targets = data
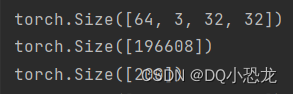
print(imgs.shape)
output = torch.flatten(imgs)
print(output.shape)
output = dq(output)
print(output.shape)
结果:
八、损失函数与反向传播
8.1简介
损失函数(Loss Function)是在机器学习和深度学习中使用的一种函数,用于衡量模型预测结果与真实标签之间的差异或误差。损失函数的选择取决于任务的性质和模型的输出类型。
在监督学习任务中,常见的损失函数包括:
-
均方误差(Mean Squared Error,MSE):用于回归问题,计算预测值与真实值之间的平方差的平均值。
-
交叉熵损失(Cross-Entropy Loss):用于分类问题,衡量预测类别和真实类别之间的差异。包括二分类交叉熵和多分类交叉熵。
-
对数损失(Log Loss):用于二分类问题,衡量预测概率与真实标签之间的差异。
-
感知损失(Perceptron Loss):用于感知机模型,当预测结果与真实标签不一致时给出固定的惩罚。
-
Hinge损失:用于支持向量机(SVM)模型,鼓励正确分类的边界足够远离决策边界。
此外,还有许多其他类型的损失函数,如平滑L1损失、Huber损失、Kullback-Leibler(KL)散度等,它们在特定的任务和模型中具有不同的应用。
选择合适的损失函数是模型训练的重要一环,它直接影响模型的学习能力和性能。在训练过程中,优化算法通过最小化损失函数来调整模型的参数,使预测结果与真实标签尽可能接近。
8.2示例

8.2.1均值损失函数

代码:
import torch
from torch.nn import L1Loss
from torch.nn import MSELoss
input = torch.tensor([2,3,4],dtype=torch.float32)
input = torch.reshape(input,(1,1,1,3))
output = torch.tensor([2,3,7],dtype=torch.float32)
output = torch.reshape(output,(1,1,1,3))
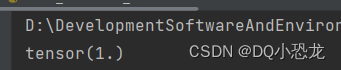
loss_mean = L1Loss()
#就是求均值(2-2 + 3-3 + 7-4)/ 3.0 = 1.
result_mean = loss_mean(input,output)
print(result_mean)
结果:
8.2.2均方误差(Mean Squared Error,MSE)

代码:
import torch
from torch.nn import L1Loss
from torch.nn import MSELoss
input = torch.tensor([2,3,4],dtype=torch.float32)
input = torch.reshape(input,(1,1,1,3))
output = torch.tensor([2,3,7],dtype=torch.float32)
output = torch.reshape(output,(1,1,1,3))
loss_mse = MSELoss()
#差值平方再取平均((2-2)^2 + (3-3)^2 + (7-4)^2)/ 3.0 = 3.
result_mse = loss_mse(input,output)
print(result_mse)结果:

8.2.3交叉熵损失函数(多用于分类)
?

示例采用的是第二个上图第二个计算公式无权重
代码:
import torch
from torch.nn import L1Loss
from torch.nn import MSELoss
from torch.nn import CrossEntropyLoss
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3))
loss_cross = CrossEntropyLoss()
result_cross = loss_cross(x,y)
print(result_cross)
结果:

计算损失函数时将会为反向传播提供每个节点的梯度。

8.3示例-利用反向传播减小损失函数
代码:
import torch
import torch.nn as nn
import torchvision
from torch.nn import Conv2d
from torch.nn import MaxPool2d
from torch.nn import Linear
from torch.nn import Flatten
from torch.nn import Sequential
from torch.nn import CrossEntropyLoss
from torch.nn import Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,1)
class DQLD(nn.Module):
def __init__(self):
super(DQLD,self).__init__()
self.module1 = Sequential(
Conv2d(3,32,5,stride=1,padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, stride=1, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, stride=1, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,input):
output = self.module1(input)
return output
dqld = DQLD()
# 优化器-SGD梯度下降算法
optimizer = torch.optim.SGD(dqld.parameters(),lr=0.01)
loss_cross = CrossEntropyLoss()
for i in range(20):
result_running = 0.0
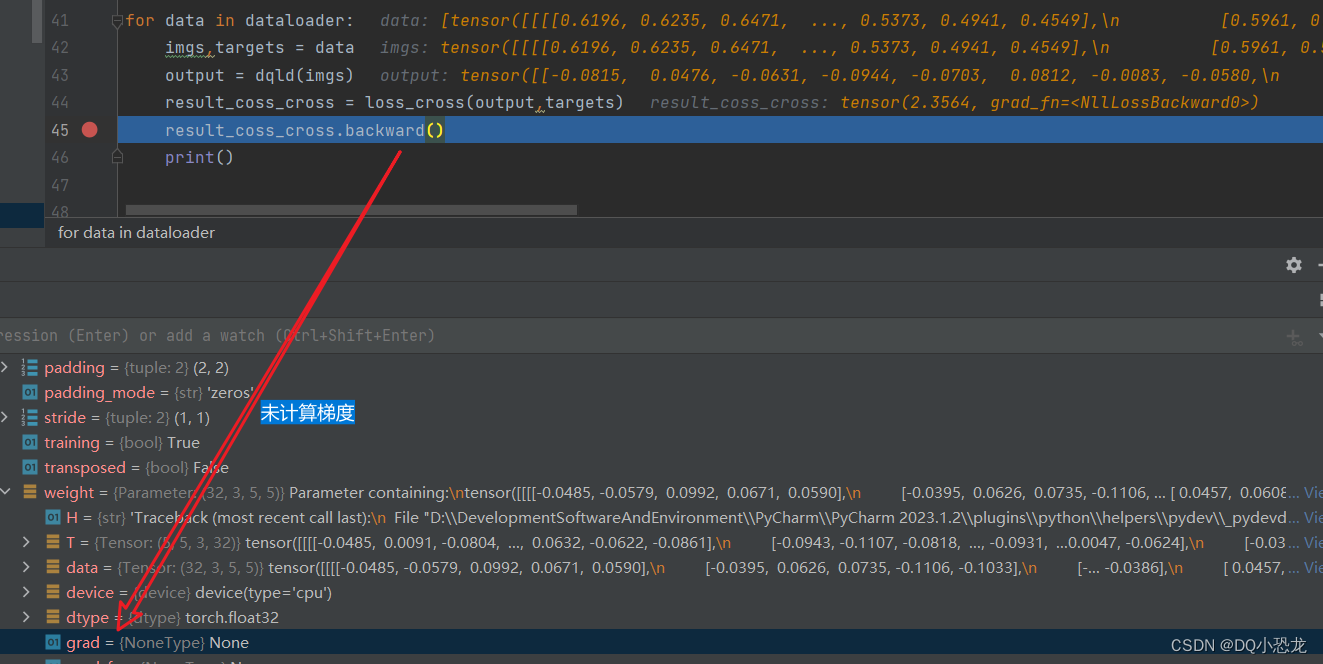
for data in dataloader:
#重置梯度
optimizer.zero_grad()
imgs,targets = data
output = dqld(imgs)
result_loss_cross = loss_cross(output,targets)
#计算梯度
result_loss_cross.backward()
#调节参数使得损失函数值减小
optimizer.step()
result_running = result_running + result_loss_cross
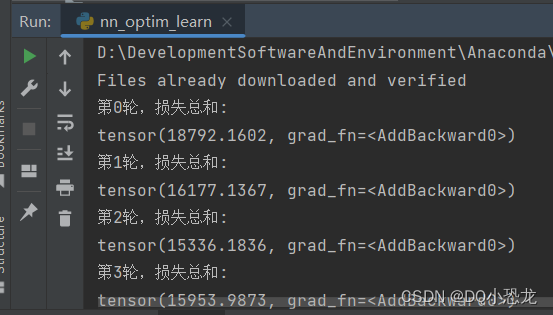
print("第" + str(i) + "轮,损失总和:")
print(result_running)
结果:
九、其他层
9.1Normalization Layer
归一化层(Normalization Layer)是深度学习中常用的一种层类型,用于对输入数据进行归一化处理。归一化的目的是将输入数据的分布调整为均值为0、方差为1(或其他目标值)的形式,以便更好地进行训练和优化。
归一化层可用于不同层之间或同一层内的特征归一化。常见的归一化层包括批量归一化层(Batch Normalization)、层归一化层(Layer Normalization)、实例归一化层(Instance Normalization)等。
这些归一化层的具体实现方式有所不同,但它们的共同目标是通过对输入数据进行归一化处理,提供更好的训练稳定性、加速收敛速度以及提高模型的泛化能力。
。。。。

















 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











