







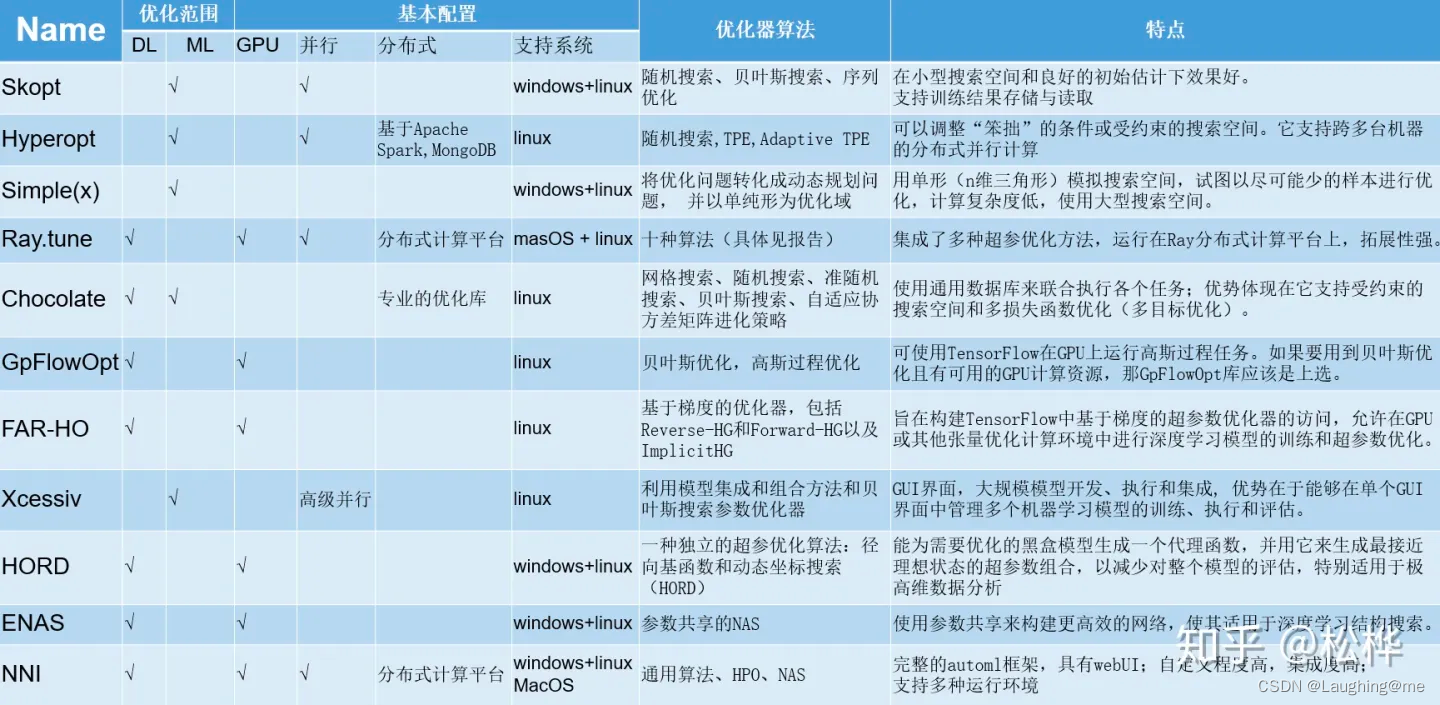
一、 介绍
支持深度学习调参,优化器算法支持全面,且支持分布式计算,本地可以有效利用多核计算,文档及维护更新较多,安装使用快捷方便。
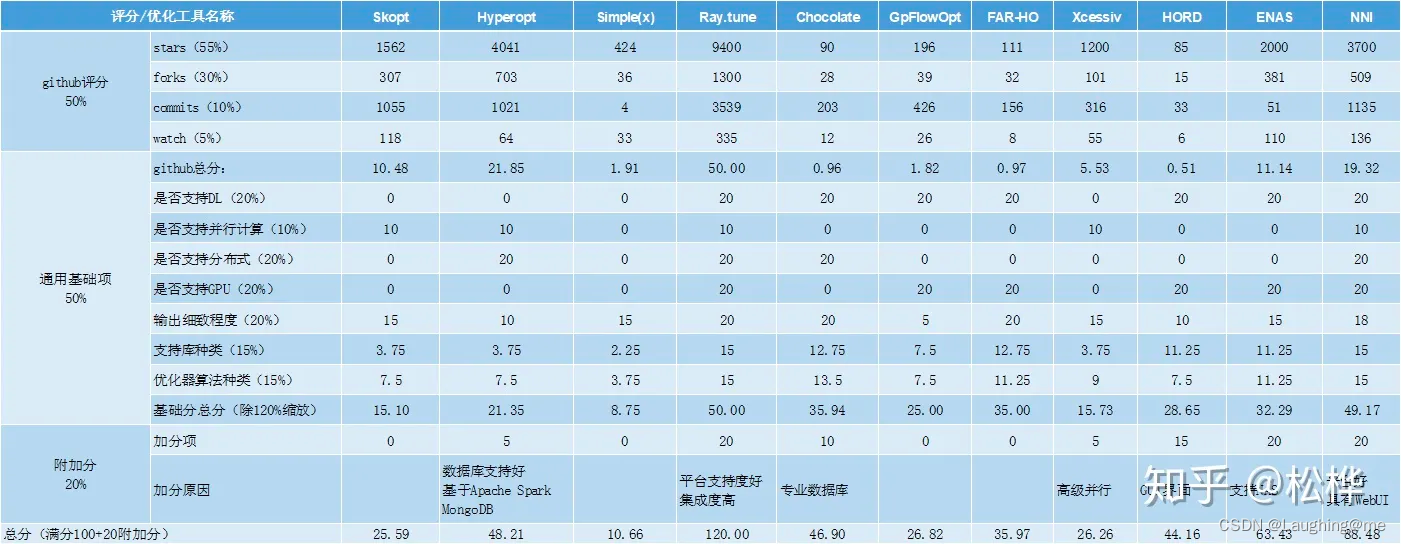
评分较好
安装:
pip install "ray[tune]" torch torchvision
二、相关用法示例
2.1 demo 示例
定义参数搜索空间 search_space
定义模型评分计算函数 objective
from ray import tune
# 1. Define an objective function.
def objective(config):
score = config["a"] ** 2 + config["b"]
return {"score": score}
# 2. Define a search space.
search_space = {
"a": tune.grid_search([0.001, 0.01, 0.1, 1.0]),
"b": tune.choice([1, 2, 3]),
}
# 3. Start a Tune run and print the best result.
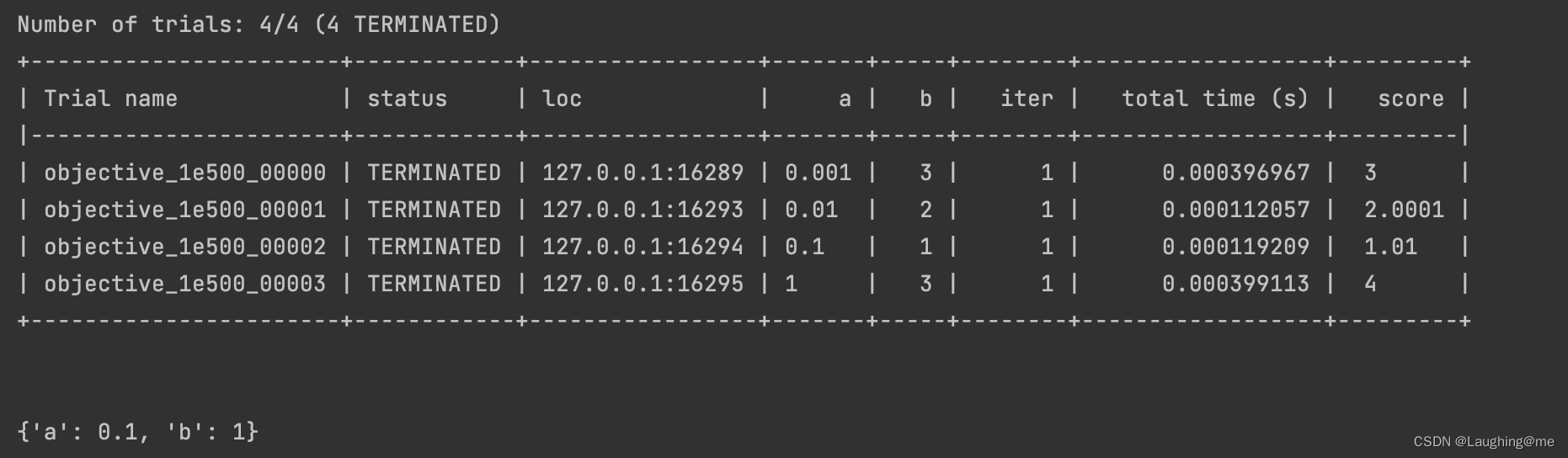
tuner = tune.Tuner(objective, param_space=search_space)
results = tuner.fit()
print(results.get_best_result(metric="score", mode="min").config)
结果:
三、资源参数示例
3.1 机器资源参数设定
tune.with_resources(trainable, {“cpu”: 2})
示例:
# If you have 4 CPUs on your machine, this will run 2 concurrent trials at a time.
trainable_with_resources = tune.with_resources(trainable, {"cpu": 2})
tuner = tune.Tuner(
trainable_with_resources,
tune_config=tune.TuneConfig(num_samples=10)
)
results = tuner.fit()
# If you have 4 CPUs on your machine, this will run 1 trial at a time.
trainable_with_resources = tune.with_resources(trainable, {"cpu": 4})
tuner = tune.Tuner(
trainable_with_resources,
tune_config=tune.TuneConfig(num_samples=10)
)
results = tuner.fit()
# Fractional values are also supported, (i.e., {"cpu": 0.5}).
# If you have 4 CPUs on your machine, this will run 8 concurrent trials at a time.
trainable_with_resources = tune.with_resources(trainable, {"cpu": 0.5})
tuner = tune.Tuner(
trainable_with_resources,
tune_config=tune.TuneConfig(num_samples=10)
)
results = tuner.fit()
# Custom resource allocation via lambda functions are also supported.
# If you want to allocate gpu resources to trials based on a setting in your config
trainable_with_resources = tune.with_resources(trainable,
resources=lambda spec: {"gpu": 1} if spec.config.use_gpu else {"gpu": 0})
tuner = tune.Tuner(
trainable_with_resources,
tune_config=tune.TuneConfig(num_samples=10)
)
results = tuner.fit()
3.2 Search Spaces 参数定义
tuner = tune.Tuner(
trainable,
param_space={
"param1": tune.choice([True, False]),
"bar": tune.uniform(0, 10),
"y": tune.grid_search([a, b, c]),
"alpha": tune.sample_from(lambda _: np.random.uniform(100) ** 2),
"const": "hello" # It is also ok to specify constant values.
})
results = tuner.fit()
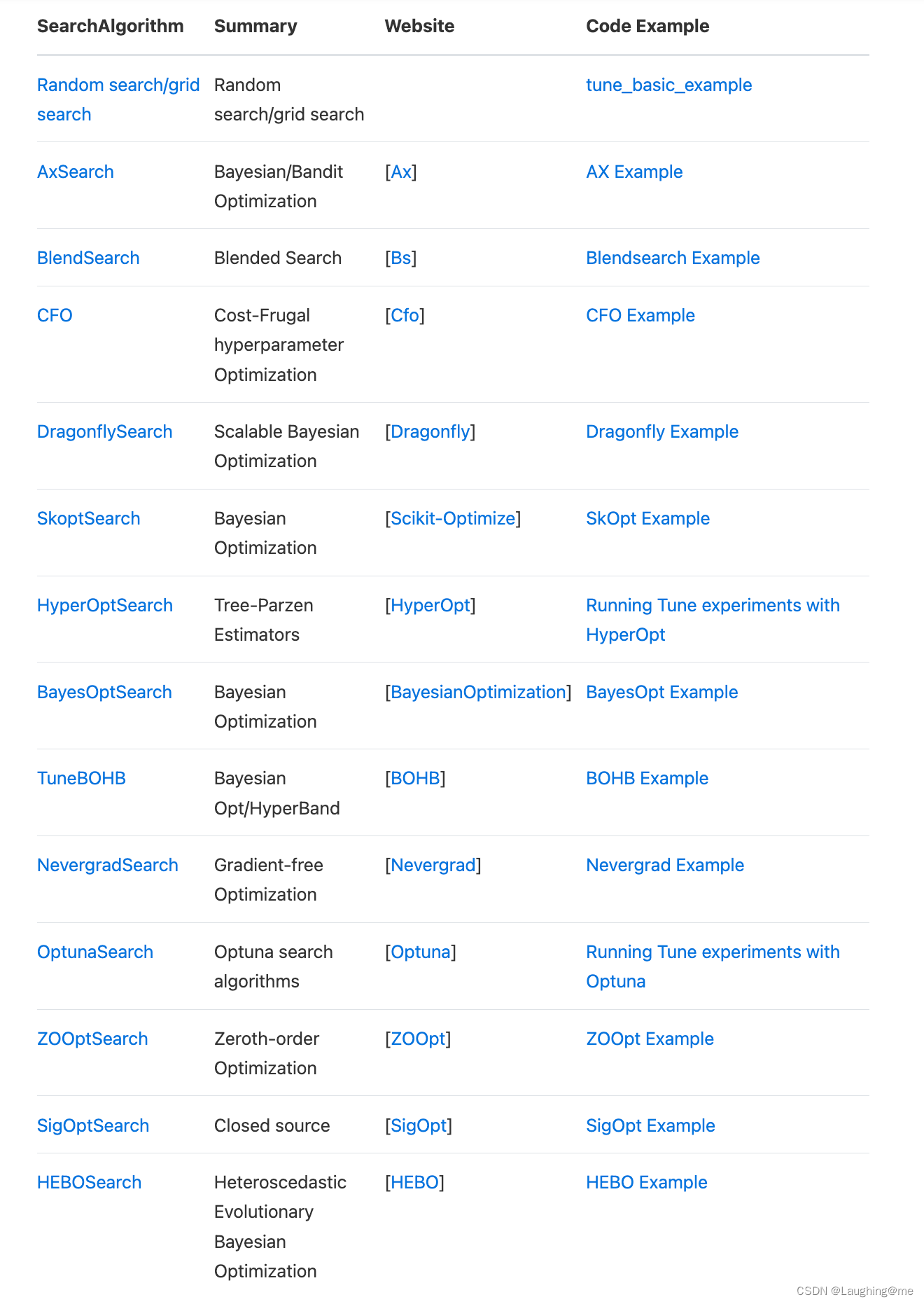
3.3 支持的寻找算法
3.4 结果
accuracy
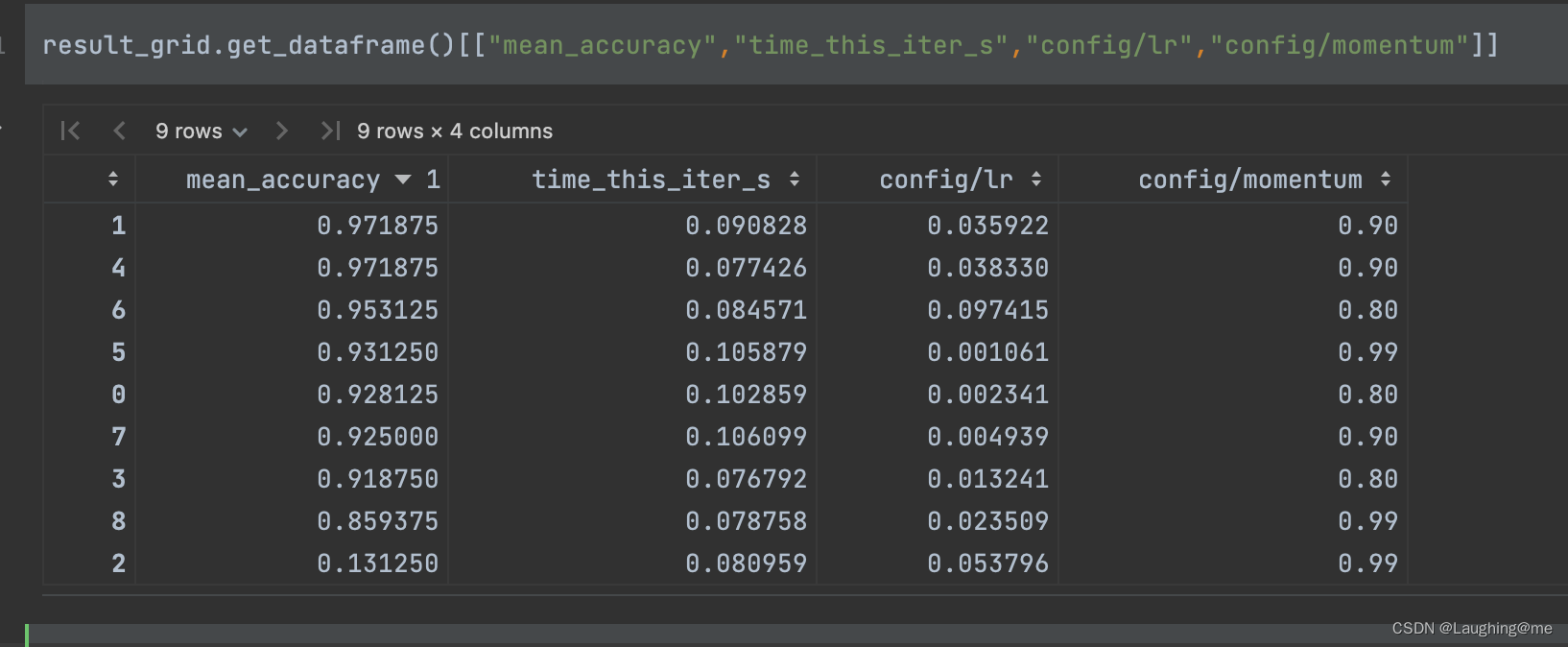
不同参数acc
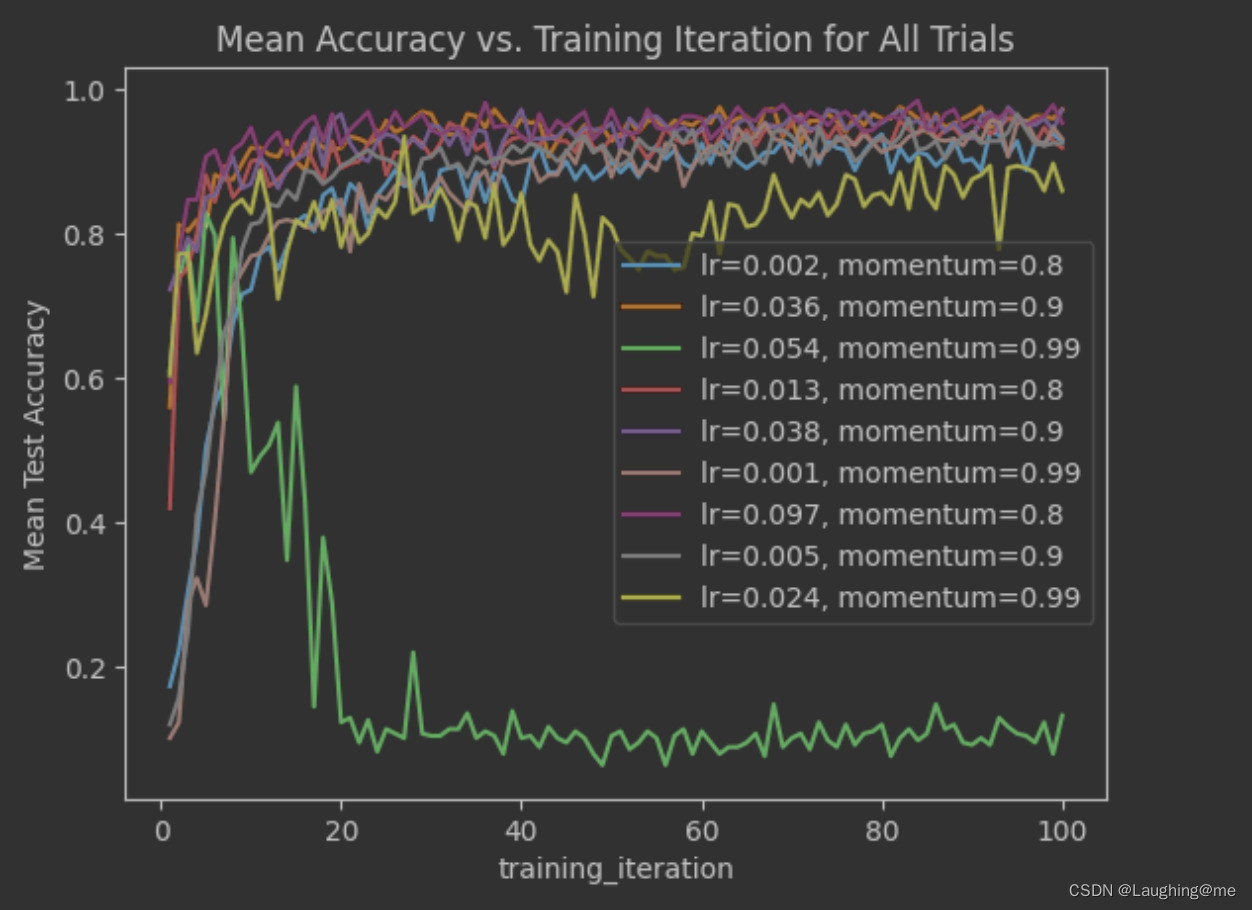
最佳acc
2.2 pytorch 示例及用法
import numpy as np
import torch
import torch.optim as optim
import torch.nn as nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.functional as F
from ray import air, tune
from ray.tune.schedulers import ASHAScheduler
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
# In this example, we don't change the model architecture
# due to simplicity.
self.conv1 = nn.Conv2d(1, 3, kernel_size=3)
self.fc = nn.Linear(192, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 3))
x = x.view(-1, 192)
x = self.fc(x)
return F.log_softmax(x, dim=1)
# Change these values if you want the training to run quicker or slower.
EPOCH_SIZE = 512
TEST_SIZE = 256
def train(model, optimizer, train_loader):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
# We set this just for the example to run quickly.
if batch_idx * len(data) > EPOCH_SIZE:
return
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
def test(model, data_loader):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(data_loader):
# We set this just for the example to run quickly.
if batch_idx * len(data) > TEST_SIZE:
break
data, target = data.to(device), target.to(device)
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
return correct / total
def train_mnist(config):
# Data Setup
mnist_transforms = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
train_loader = DataLoader(
datasets.MNIST("~/data", train=True, download=True, transform=mnist_transforms),
batch_size=64,
shuffle=True)
test_loader = DataLoader(
datasets.MNIST("~/data", train=False, transform=mnist_transforms),
batch_size=64,
shuffle=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = ConvNet()
model.to(device)
optimizer = optim.SGD(
model.parameters(), lr=config["lr"], momentum=config["momentum"])
for i in range(10):
train(model, optimizer, train_loader)
acc = test(model, test_loader)
# Send the current training result back to Tune
tune.report(mean_accuracy=acc)
if i % 5 == 0:
# This saves the model to the trial directory
torch.save(model.state_dict(), "./model.pth")
search_space = {
"lr": tune.sample_from(lambda spec: 10 ** (-10 * np.random.rand())),
"momentum": tune.uniform(0.1, 0.9),
}
# Uncomment this to enable distributed execution
# `ray.init(address="auto")`
# Download the dataset first
datasets.MNIST("~/data", train=True, download=True)
tuner = tune.Tuner(
train_mnist,
param_space=search_space,
tune_config=tune.TuneConfig(
num_samples=20,
scheduler=ASHAScheduler(metric="mean_accuracy", mode="max"),
)
)
results = tuner.fit()
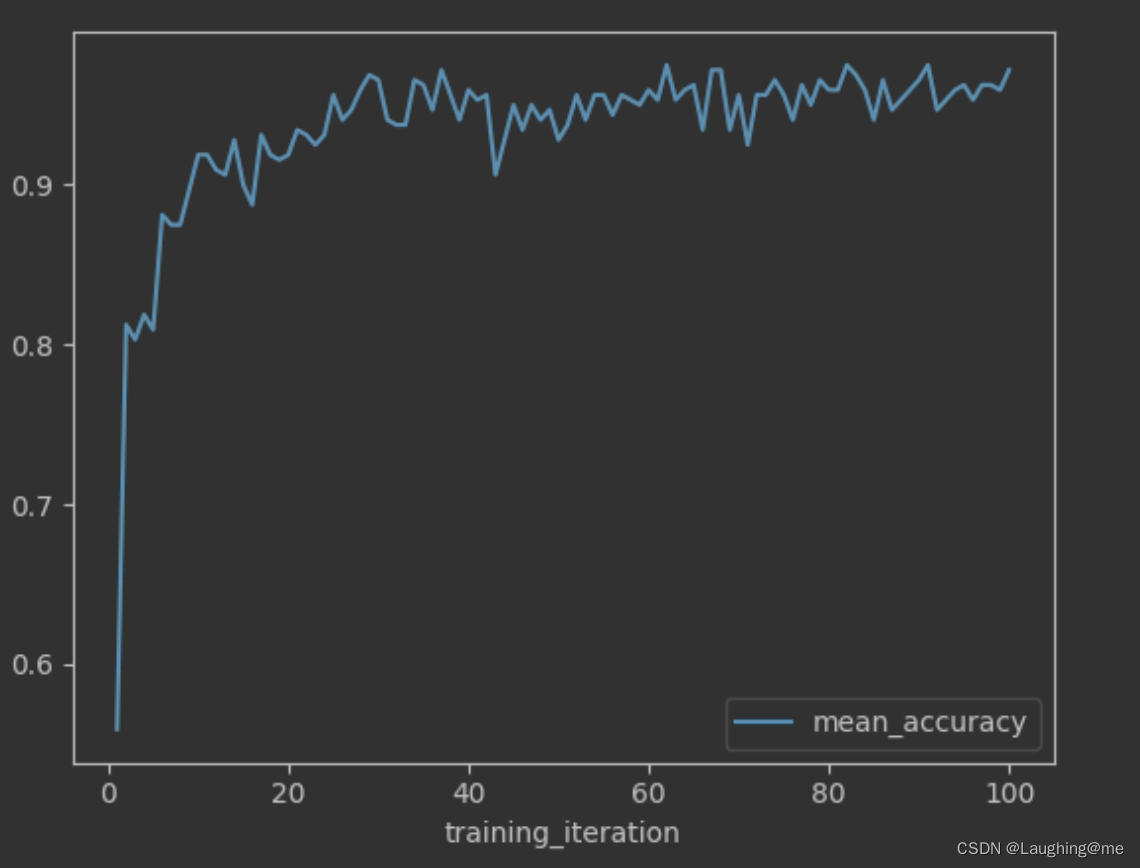
dfs = {result.log_dir: result.metrics_dataframe for result in results}
[d.mean_accuracy.plot() for d in dfs.values()]
df = results.get_dataframe().sort_values("mean_accuracy", ascending=False)
print("df result is :", df)
auto 训练结果示例:
















 846
846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









