






从原理出发利用python计算EEG信号的近似熵、样本熵和模糊熵。具体的原理我就不在这里说了,网上有很多讲解得很好的,一搜就有很多。我这里就给大家展示一下python的实现过程和结果,代码纯手敲,还没有对比工具箱的计算结果,不过应该可以帮助你更好的理解这几个熵的计算过程。因为我看原理公式的时候总是看不明白,通过代码感觉会更清晰。希望对你也是一样。若有错误,欢迎指出。

一、近似熵
def ApEn(x, m, r): # 2. m:模式维数, r:相似容限
N = len(x) # 1. 信号总长N
x = np.array(x)
if x.ndim != 1:
raise ValueError("x的维度不是一维")
if N < m + 1:
raise ValueError("len(x)小于m+1")
phi = []
for temp in range(2): # 7. 将窗 m 增长为 m+1: temp = 0:m ; temp = 1: m+1
# 3. 以m为窗,将时间序列分为k = n-m+1个序列
X = []
m = m+temp
for i in range(N + 1 - m):
X.append(x[i:i+m])
X = np.array(X)
# 4. 计算每个i与所有j之间的绝对值距离,获取统计个数:N_m(i)【count】
C = []
for index1, i in enumerate(X):
count = 0
for index2, j in enumerate(X):
if index1 != index2:
if np.max(np.abs(i-j)) <= r:
count += 1
# 5. 获取 C
C.append(count/(N-m+1))
# 处理C为0的值,替换为一个非零的很小的数,以防取对数时报错
C = np.array(C)
C = np.where(C == 0, 1e-10, C)
# 6. 对每个C取自然对数,获取 Φ
phi.append(np.sum(np.log(C))/(N-m+1))
# 8. 获取近似熵
apEn = phi[0] - phi[1]
return apEn
二、样本熵
def SampEn(x, m, r):
N = len(x) # 1. 信号总长N
x = np.array(x)
if x.ndim != 1:
raise ValueError("x的维度不是一维")
if N < m + 1:
raise ValueError("len(x)小于m+1")
AB = []
for temp in range(2): # 7. 将窗 m 增长为 m+1: temp = 0:m ; temp = 1: m+1
# 3. 以m为窗,将时间序列分为k = n-m+1个序列
X = []
m = m+temp
for i in range(N + 1 - m):
X.append(x[i:i+m])
X = np.array(X)
# 4. 计算每个i与所有j之间的绝对值距离,统计距离d小于r的个数:N_m(i)【count】
C = []
for index1, i in enumerate(X):
count = 0
for index2, j in enumerate(X):
if index1 != index2:
if np.max(np.abs(i-j)) <= r:
count += 1
# 5. 获取每个i的 C
C.append(count/(N-m+1))
# 处理C为0的值,替换为一个非零的很小的数,以防取对数时报错
C = np.array(C)
C = np.where(C == 0, 1e-10, C)
# 6. 求所有i得平均值
AB.append(np.sum(C)/(N-m+1))
# 8. 获取样本熵
SE = np.log(AB[0]) - np.log(AB[1])
return SE
三、模糊熵
def FuzzyEntopy(x, m, r, n=2):
x = np.array(x)
if x.ndim != 1:
raise ValueError("x的维度不是一维")
if len(x) < m + 1:
raise ValueError("len(x)小于m+1")
entropy = 0
for temp in range(2): # 5. 将窗 m 增长为 m+1: temp = 0:m ; temp = 1: m+1
# 2. 以m为窗,将时间序列分为k = n-m+1个序列
X = []
for i in range(len(x) + 1 - (m + temp)):
X.append(x[i:i+m+temp])
X = np.array(X)
D_value = []
# 3. 计算绝对距离
for index1, i in enumerate(X):
d = []
for index2, j in enumerate(X):
if index1 != index2:
d.append(np.max(np.abs(i-j)))
D_value.append(d)
# 4. 计算模糊隶属度D
D = np.exp(-np.power(D_value, n)/r)
Lm = np.average(D.ravel())
# 6. 计算模糊熵
entropy = np.abs(entropy) - np.log(Lm)
return entropy
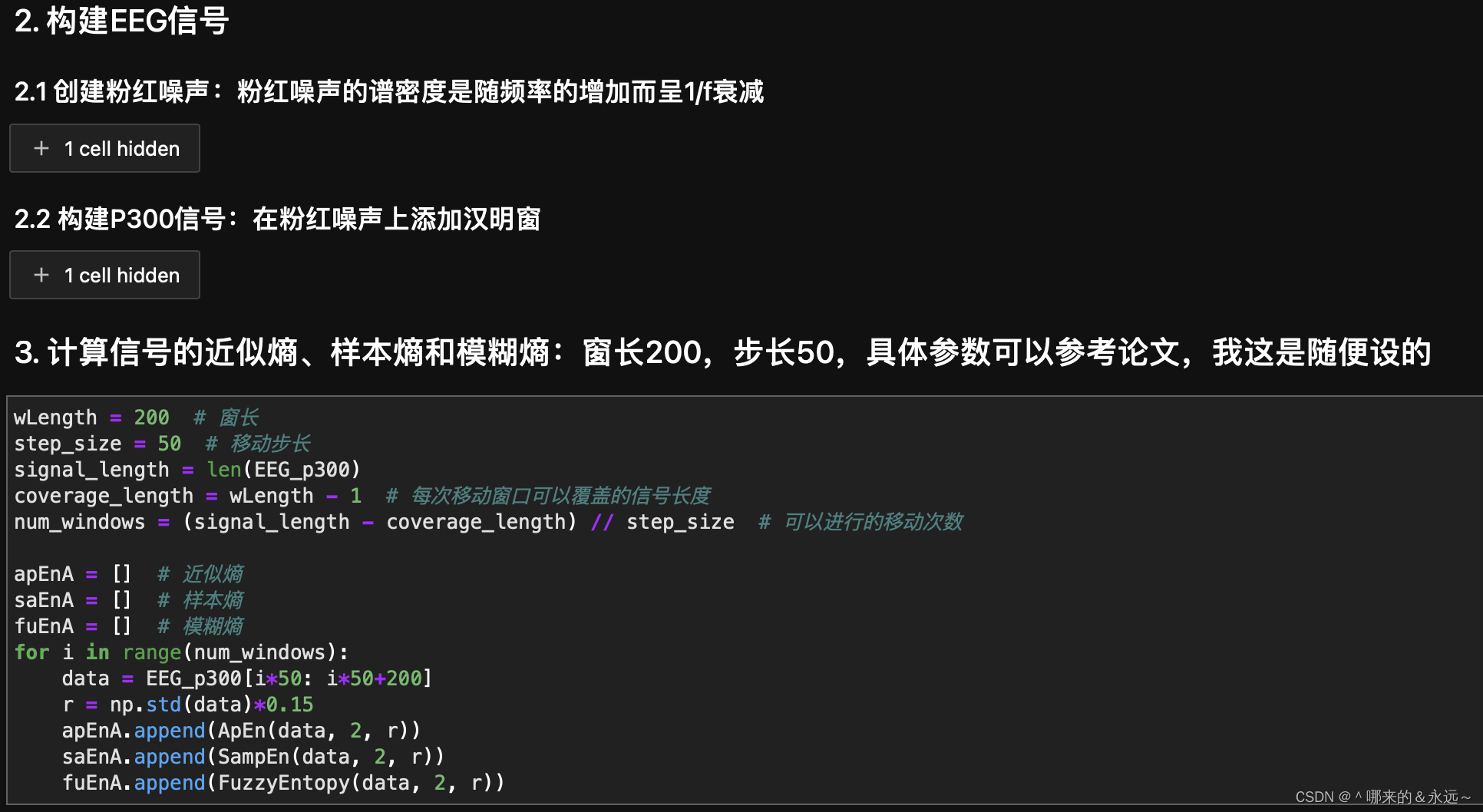
四、结果















 1568
1568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









