







1.前缀树
何为前缀树?如何生成前缀树?

经典的前缀树字符是放在路上的,下面有一个不空的节点(节点上没有数据),说明这条路存在。已经存在的路径可以复用,不存在的需要新建。实际使用时,点上有数据:pass:这个节点通过多少次,当前节点及以上作为前缀的次数;end:这个节点作为多少字符串的结尾节点,已当前路径为字符串的数量;nexts:存储当前节点的子节点,不为空则说明该子节点存在。根节点的pass:加入了多少字符串,有多少字符串以空串作为前缀。
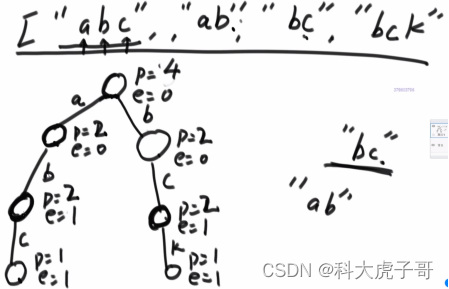
(1)在前缀树中添加一个字符串:insert
(2)查询word之前加入过的次数:search
(3)所有加入的字符串中,有多少是以pre作为前缀的:prefixNumber
代码实现:
(4)删除word:delete。需要先检查word是否加入过,加入过再删除
C++注意析构问题
代码实现:
class TrieNode {
public:
int pass;
int end;
//如果字符数量过多可以用unordered_map<char,TrieNode>nexts表示路
//map<char,TrieNode>nexts
vector<TrieNode*>nexts;
TrieNode() {
this->pass = 0;
this->end = 0;
//nexts[0]==nullptr:没有走向'a'的路
//nexts[0]!=nullptr:有走向'a'的路
//...
//nexts[25]!=nullptr:有走向'z'的路
this->nexts = vector<TrieNode*>(26,nullptr);
}
};
class Trie {
private:
TrieNode* root;
public:
Trie() {
this->root = new TrieNode;
}
//在前缀树中添加一个字符串
void insert(string word) {
if (word.length() == 0) {
return;
}
TrieNode* node = root;
node->pass++;
for (char c : word) {
if (node->nexts[c - 'a'] == nullptr) {
node->nexts[c - 'a'] = new TrieNode;
}
node = node->nexts[c - 'a'];
node->pass++;
}
node->end++;
}
//查询word之前加入过的次数
int search(string word) {
if (word.length() == 0) {
return 0;
}
TrieNode* node = root;
for (char c : word) {
if (node->nexts[c - 'a'] == nullptr) {
return 0;
}
node = node->nexts[c - 'a'];
}
return node->end;
}
//所有加入的字符串中,有多少是以pre作为前缀的
int prefixNumber(string pre) {
if (pre.length() == 0) {
return 0;
}
TrieNode* node = root;
for (char c : pre) {
if (node->nexts[c - 'a'] == nullptr) {
return 0;
}
node = node->nexts[c - 'a'];
}
return node->pass;
}
//删除word
void deleteWord(string word) {
if (search(word) != 0) {//需要先检查word是否加入过,加入过再删除
TrieNode* node = root;
node->pass--;
int index = -1;//记录pass为0的字符在字符串中的位置
TrieNode* pre = nullptr;//记录最后一个pass不为0的节点,目的是找到pass为0的节点,将其置空
stack<TrieNode*>sk;//记录需要析构的节点
for (int i = 0; i < word.length(); i++) {
node->nexts[word[i] - 'a']->pass--;
if (node->nexts[word[i] - 'a']->pass == 0) {//当某个节点的pass减减之后为0了,说明后续节点(delete)都要删掉
pre = pre == nullptr ? node : pre;
index = index == -1 ? i : index;
sk.push(node->nexts[word[i] - 'a']);
}
node = node->nexts[word[i] - 'a'];
}
node->end--;
pre->nexts[word[index] - 'a'] = nullptr;
while (!sk.empty()) {
delete sk.top();
sk.pop();
}
}
}
};
2.贪心算法

贪心算法的在笔试时的解题套路

堆和排序是贪心算法最常用的两个技巧。
例:
(1)会议室场次问题

按照会议结束时间早为贪心策略。
代码实现:
bool cmp(vector<int>& arr1, vector<int>& arr2) {
return arr1[1] < arr2[1];//<:从小到大;>:从大到小
}
int bestArrange(vector<vector<int>>program, int timePoint) {
sort(program.begin(),program.end(),cmp);
int res = 0;
for (int i = 0; i < program.size(); i++) {
if (program[i][0] >= timePoint) {
res++;
timePoint = program[i][1];
}
}
return res;
}
(2)字典序:

直观上就是字符串在字典中的顺序。严格定义是将字符串看成一个26进制的数,比较大小,小的在前面,对于长度不一样的字符串需要在短字符串后面补0,使得长度一样
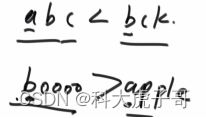
错误的贪心策略:按照字符串各自的字典序排序,小的放前面,大的放后面。错误距离:

正确的贪心策略:

首先证明比较策略是有效的:不能形成环,排序后是唯一的,具有传递性


证明有最小的字典序:
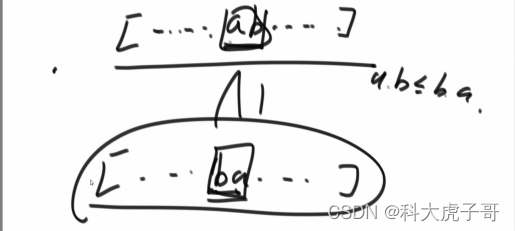
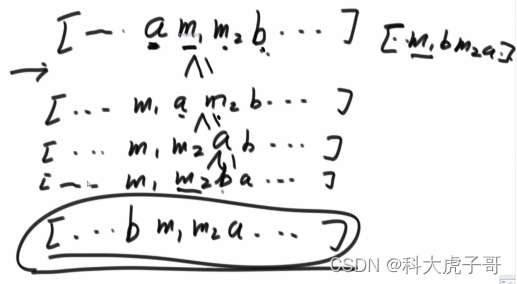
代码实现:
bool cmp(string s1, string s2) {
string s12 = s1 + s2;
string s21 = s2 + s1;
return s12.compare(s21) < 0 ? true : false;
}
string lowestString(vector<string>strs) {
sort(strs.begin(), strs.end(), cmp);
string res ="";
for (int i = 0; i < strs.size(); i++) {
res += strs[i];
}
return res;
}
(3)金条切割花费
 哈夫曼编码问题:将所有数放入小根堆中,每次取出两个数,结合后再放入小根堆。
哈夫曼编码问题:将所有数放入小根堆中,每次取出两个数,结合后再放入小根堆。
笔试会出,一般是一题;面试很少,因为贪心算法的coding很简单,没有区分度。
代码实现:
int lessMoneySplitGold(vector<int>arr) {
priority_queue<int, vector<int>, greater<int>>p;
for (int i = 0; i < arr.size(); i++) {
p.push(arr[i]);
}
int res = 0;
while (p.size()>1) {
int sum = p.top();
p.pop();
sum += p.top();
p.pop();
res += sum;
p.push(sum);
}
return res;
}
(4)项目收益

首先按照花费排序将所有项目放入一个小根堆中;然后从小根堆中弹出项目花费小于等于当前资金的项目放入按照利润排序的大根堆中;从大根堆中弹出一个项目,做该项目,更新资金;然后在从小根堆中弹出项目花费小于等于当前资金的项目放入按照利润排序的大根堆中,周而复始,直到项目大根堆为空/做完k个项目
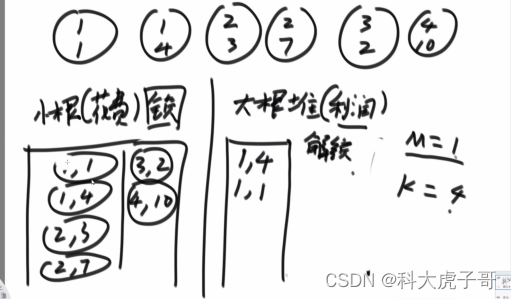
代码实现:
int maxCapital(int k, int w, vector<vector<int>>costsAndProfits) {
priority_queue<vector<int>, vector<vector<int>>, cmp1>minCost;
priority_queue<vector<int>, vector<vector<int>>, cmp2>maxProf;
for (int i = 0; i < costsAndProfits.size(); i++) {
minCost.push(costsAndProfits[i]);
}
while (k > 0 && (!maxProf.empty() || (!minCost.empty() && minCost.top()[0] <= w))) {
while (!minCost.empty()&&minCost.top()[0] <= w) {
maxProf.push(minCost.top());
minCost.pop();
}
w += maxProf.top()[1];
maxProf.pop();
k--;
}
return w;
}
(5)一个数据流中,随时可以取得中位数
准备一个大根堆、一个小根堆:1 第一个数字直接入大根堆;2 cur<=大根堆的堆顶,入大根堆,否则入小根堆;3 比较两个堆的大小,两者差大于1,size大的那个堆弹出一个元素进size小的那个堆。这样做的效果是:较小的N/2个数在大根堆中,较大的N/2个数在小根堆中
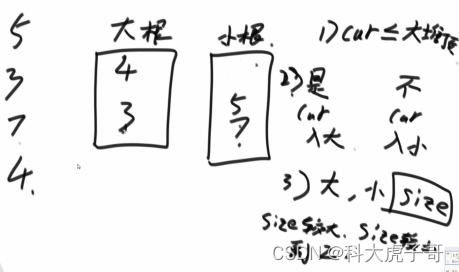
代码实习:
int getMedian(vector<int>&arr) {
priority_queue<int, vector<int>, greater<int>>minp;
priority_queue<int, vector<int>, less<int>>maxp;
maxp.push(arr[0]);
for (int i = 1; i < arr.size(); i++) {
if (arr[i] > maxp.top()) {
minp.push(arr[i]);
}
else {
maxp.push(arr[i]);
}
if (abs((int)minp.size() - (int)maxp.size())>1) {
if (minp.size() > maxp.size()) {
maxp.push(minp.top());
minp.pop();
}
else {
minp.push(maxp.top());
maxp.pop();
}
}
}
if (minp.size() == maxp.size()) {
return (minp.top() + maxp.top()) / 2;
}
if (minp.size() > maxp.size()) {
return minp.top();
}
return maxp.top();
}















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









