







python在爬虫方面的应用
.整体设计目标
通过本程序爬取网易云歌曲的歌词并输出展现给用户,为了让其显得更加人性化,设计了由用户输入想爬取歌词歌曲的id,而且有是否将歌词保存到文本文件、是否用歌词生成词云选项。
代码总体框架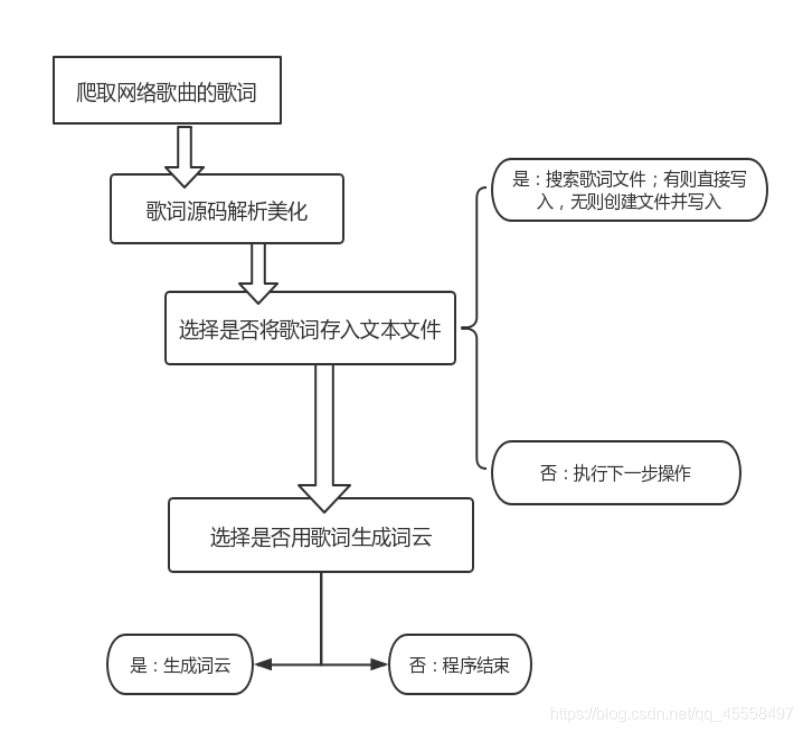
- 效果预览
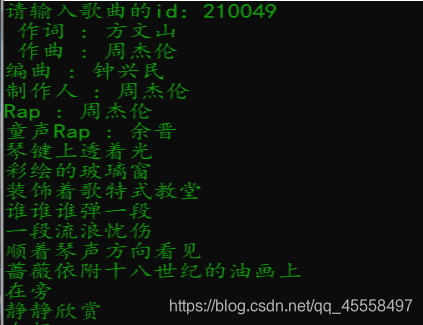
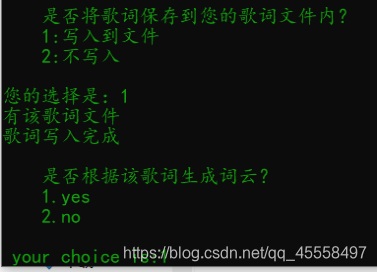


本爬虫程序用到以下几个第三方库,需要自己去下载安装:
requests、json、re、os、jieba、wordcloud、PIL.Image、numpy库。
首先要去网易云爬取歌词(此片代码是借鉴一位前辈的,我又稍加修改让歌词展现的更加简洁一点):
import requests
import json
import re
music_id = input("请输入歌曲的id:")
#我们这里以周杰伦的“布拉格广场”为例,id=210049
headers={
"User-Agent" : "Mozilla/5.0(Windows NT 10.0; WOW64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36 ",
"Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language" : "zh-CN,zh;q=0.9",
"Connection" : "keep-alive",
"Accept-Charset" : "GB2312,utf-8;q=0.7,*;q=0.7"}
url = 'http://music.163.com/api/song/lyric?'+ 'id=' + music_id + '&lv=1&kv=1&tv=-1'
r = requests.get(url,headers=headers,allow_redirects=False)
#allow_redirects设置为重定向的参数
#headers=headers添加请求头的参数,冒充请求头
#用js将获取的歌词源码进行解析
json_obj = r.text#.text返回的是unicode 型的数据,需要解析
j = json.loads(json_obj)#进行json解析
words = j['lrc']['lyric'] #将解析后的歌词存在words变量中
#解析后的歌词发现每行歌词前面有时间节点,将它进行美化一下:
pattern = '\\(.*?\\)|\\{.*?}|\\[.*?]'
text1 = re.sub(pattern, "", words)#用正则表达式将时间剔除
print(text1)#text1是歌词
再写个选择项是否写入文件:
创建菜单选项
def select(writefile):
print ( '''
是否将歌词保存到您的歌词文件内?
1:写入到文件
2:不写入
''' )
while True:
choice = input( "您的选择是:" )
if choice == '1':
write_into_file()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 831
831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









