







还在羡慕别人的DeepSeek?手把手教你在GpuGeek搭建专属大模型

1. 为什么选择云平台搭建DeepSeek大模型

作为一名熟知AI各种性能参数的技术博主,实测发现GpuGeek在算力资源上具备显著优势,平台提供了RTX 4090、H100、A800等多种高性能GPU,能满足不同规模的模型训练与推理需求。例如RTX 4090搭载的16384个CUDA核心和24GB GDDR6X显存,在处理复杂的DeepSeek模型时,能大幅提升计算效率。
其弹性计费模式也十分灵活,支持按需付费,无论是短期的模型测试,还是长期的项目部署,都能精准匹配需求,避免资源浪费。以DeepSeek-R1-70B模型为例,使用GpuGeek平台的成本仅为传统云平台的1/10左右,性价比突出。
2. 搭建前的准备工作
2.1 账号注册
访问GpuGeek官网,使用手机号完成注册。新用户实名认证会后会赠送2张10元无门槛代金券,学生认证后还能获得150元专属优惠,对于初次尝试的开发者来说非常友好。
2.2 模型与镜像选择策略

GpuGeek镜像市场提供了丰富的DeepSeek模型镜像,包括了DeepSeek-R1的不同参数版本。对于新手,建议从7B版本开始体验,单卡RTX-A5000-24G即可运行,单小时费用仅0.88元。
选择镜像时,务必确认镜像是否经过官方认证,例如标注“DeepSeek-R1-70B-vLLM”的镜像,已预配置好vLLM推理框架和必要依赖,可省去手动安装的繁琐步骤。
3. 实战部署:从实例创建到服务启动
3.1 选择镜像

登录GpuGeek,点击“镜像市场”,我们可以看到,GPUGeek为我们部署好了非常多的镜像和模型,真正让我们做到了开箱即用,免去的从0部署大模型服务带来的额外开销和技术复杂度,这点非常赞,强烈点1000000000000个赞。我们在镜像市场中搜索DeepSeek,找到使用量最高的那个镜像(该镜像支持通过Ollama运行DeekSeek-R1 1.5B、DeekSeek-R1 7B、DeekSeek-R1 8B、DeekSeek-R1 14B、DeekSeek-R1 32B等模型进行推理,使用Lobe-Chat进行WebUI展示对话)。
3.2 创建实例
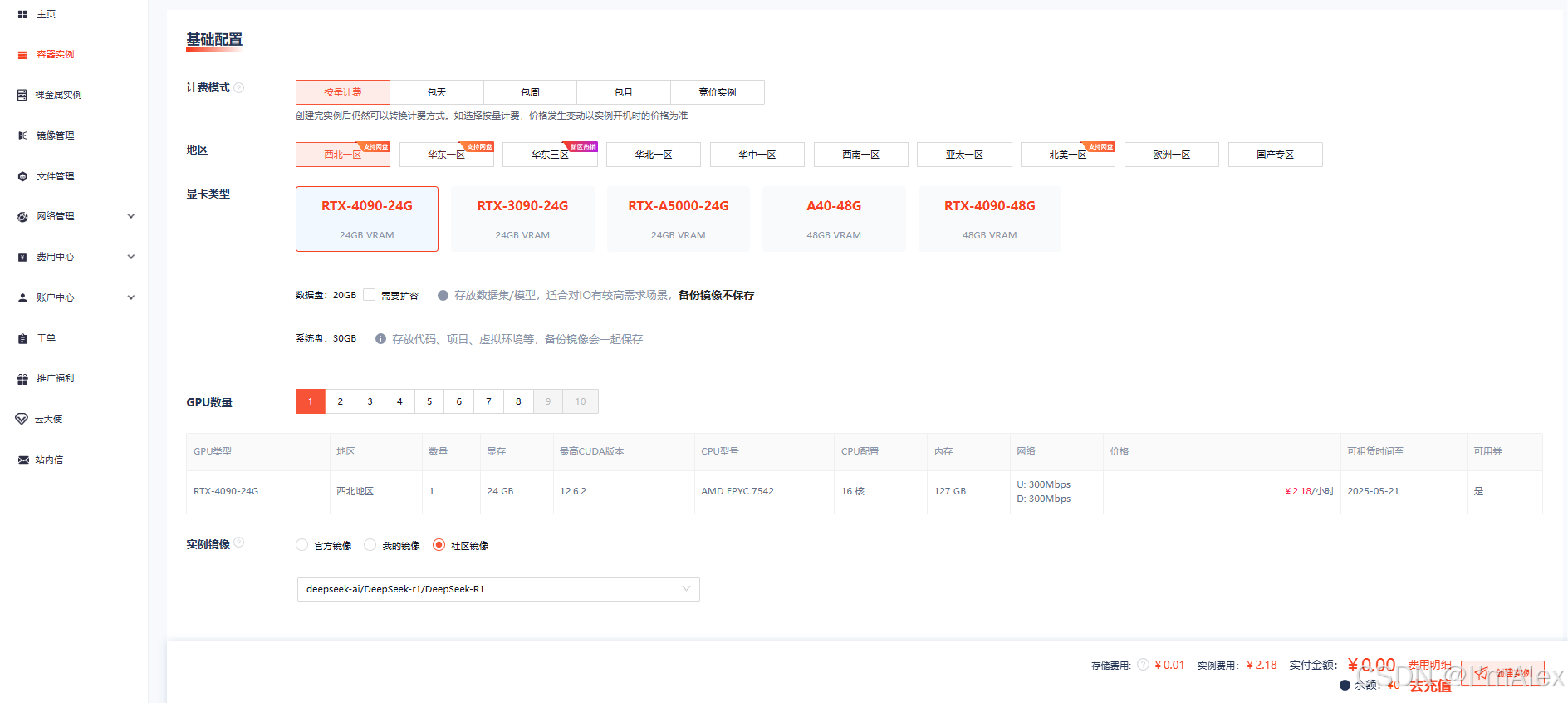
点击镜像右下角的创建实例按钮进入容器实例的配置页面,所有参数保持默认(默认选择的就是4090显卡,配置对我们选择的模型是够用的),点击右下角的创建实例按钮。
3.3 等待初始化
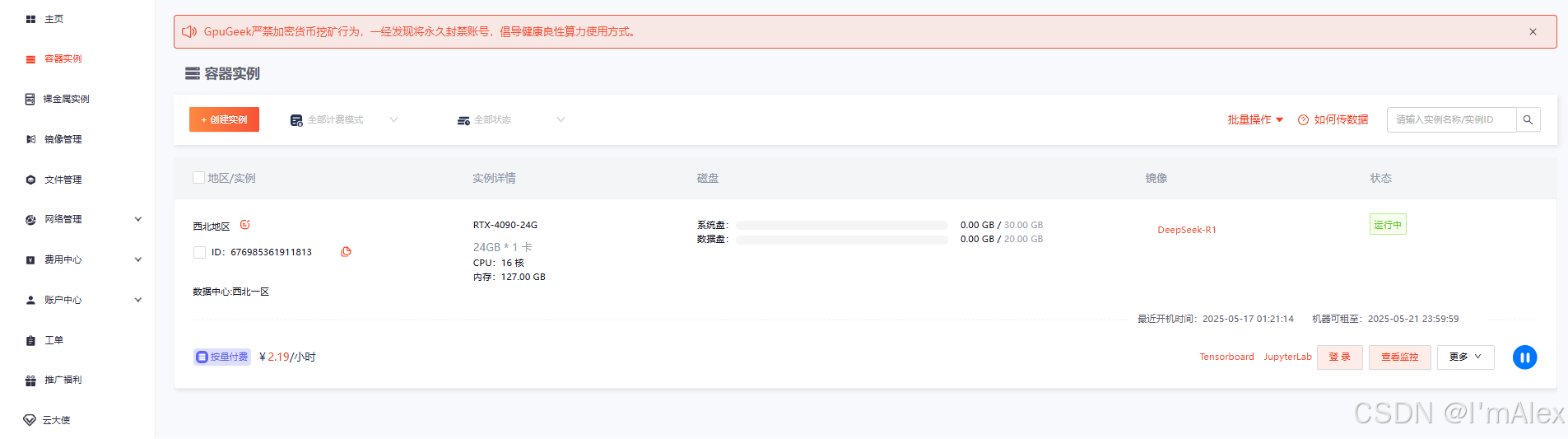
稍等片刻,实例就可以创建好,速度非常快。实例创建好之后,在容器实例页面,可以看到刚才初始化的云服务器。
3.4 获取服务器登录账号密码
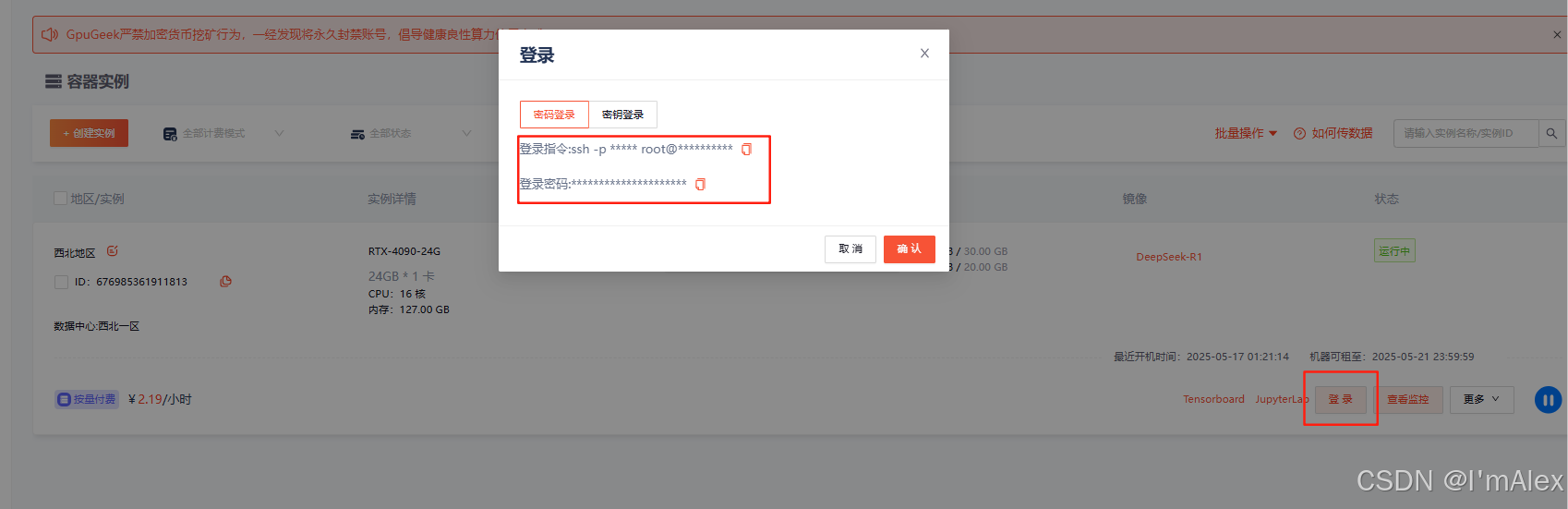
点击登录按钮,复制登录指令和登录密码。
3.5 远程登录云服务器测试
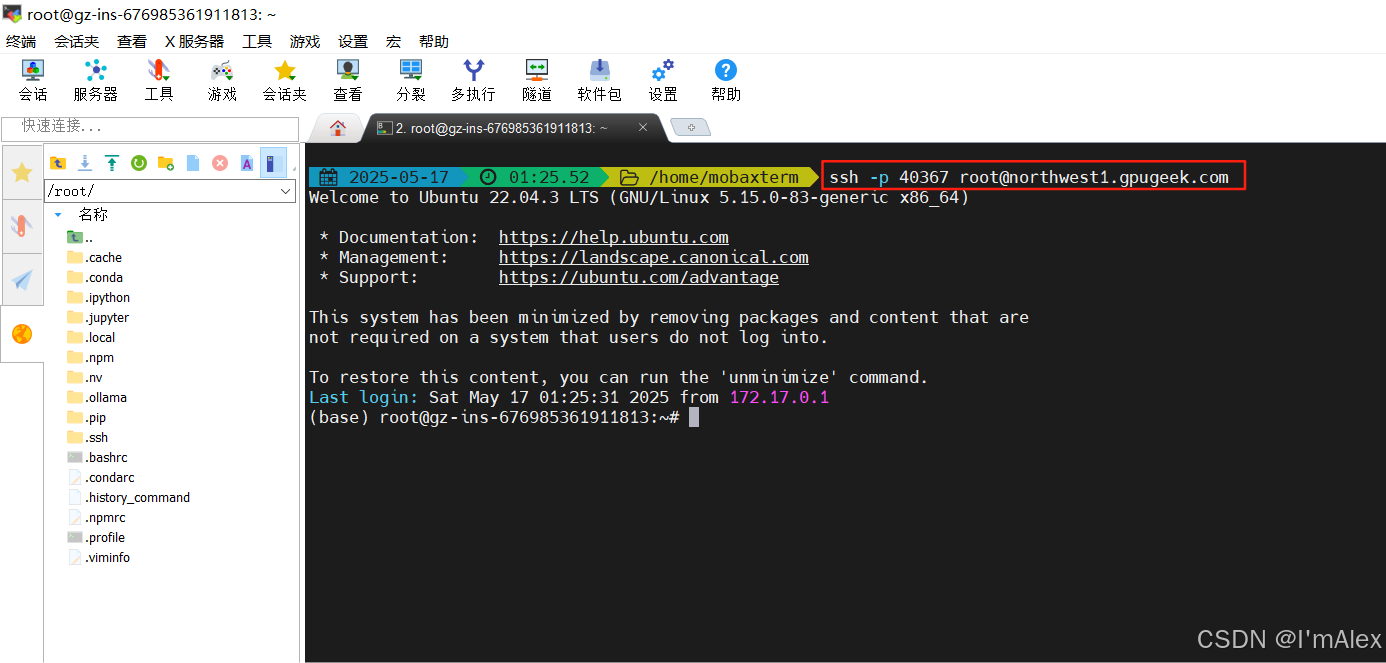
使用你熟悉的终端工具,登录到服务器上即可。
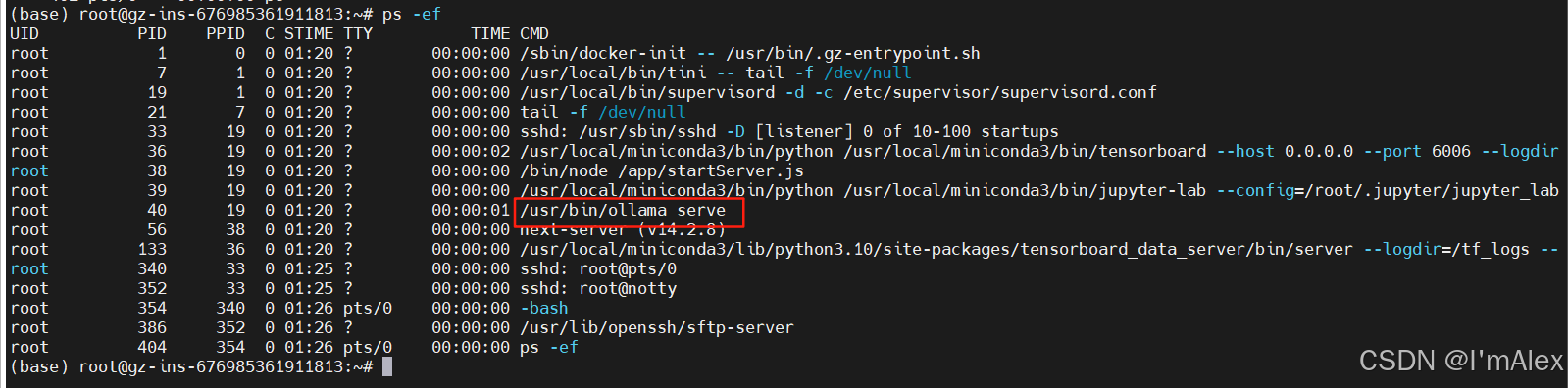
通过ps命令可以看到,该镜像已经将ollama服务器开机启动了,我们接下来就可以直接启动大模型使用了。
4. 模型选择和使用
4.1 建立ssh隧道
由于GpuGeek云主机并没有提供独立的公网ip,所以(对于)我们(个人开发者)来说,需要通过建立SSH隧道的方式,将云主机上的服务端口映射到我们本机电脑,以实现直接访问。


如上图所示,分别启动2个新的终端,分别执行如下命令:
ssh -p 40367 root@northwest1.gpugeek.com -CNg -L 3210:127.0.0.1:3210
ssh -p 40367 root@northwest1.gpugeek.com -CNg -L 11434:127.0.0.1:11434
其中,
ssh -p 40367 root@northwest1.gpugeek.com就是我们前面在3.4节中获取到的登录指令。3210:127.0.0.1:3210是指将实例内的3210端口映射到本机的3210端口。
经过上述的配置,就顺利打通了本机到云主机的一条直连通道。当我们访问本机的3210端口时本质上就会自动将请求转发到云主机的3210端口,通过这种SSH隧道的方式就实现了本机到实例内服务的直连。
注意:打开两个终端分别执行这两条ssh命令,命令执行输入密码之后是没有任何日志回显的。上图中因为我的终端软件已经为该登录地址保存了密码,所以终端软件自动帮我填充了,没有提示输入密码。
4.2 启动LobeChat
本地浏览器直接打开http://127.0.0.1:3210,就可以看到我们书得想BloeChat页面了。
点击立即开始按钮,点击右上角的会话设置按钮。
4.3 配置Ollama服务
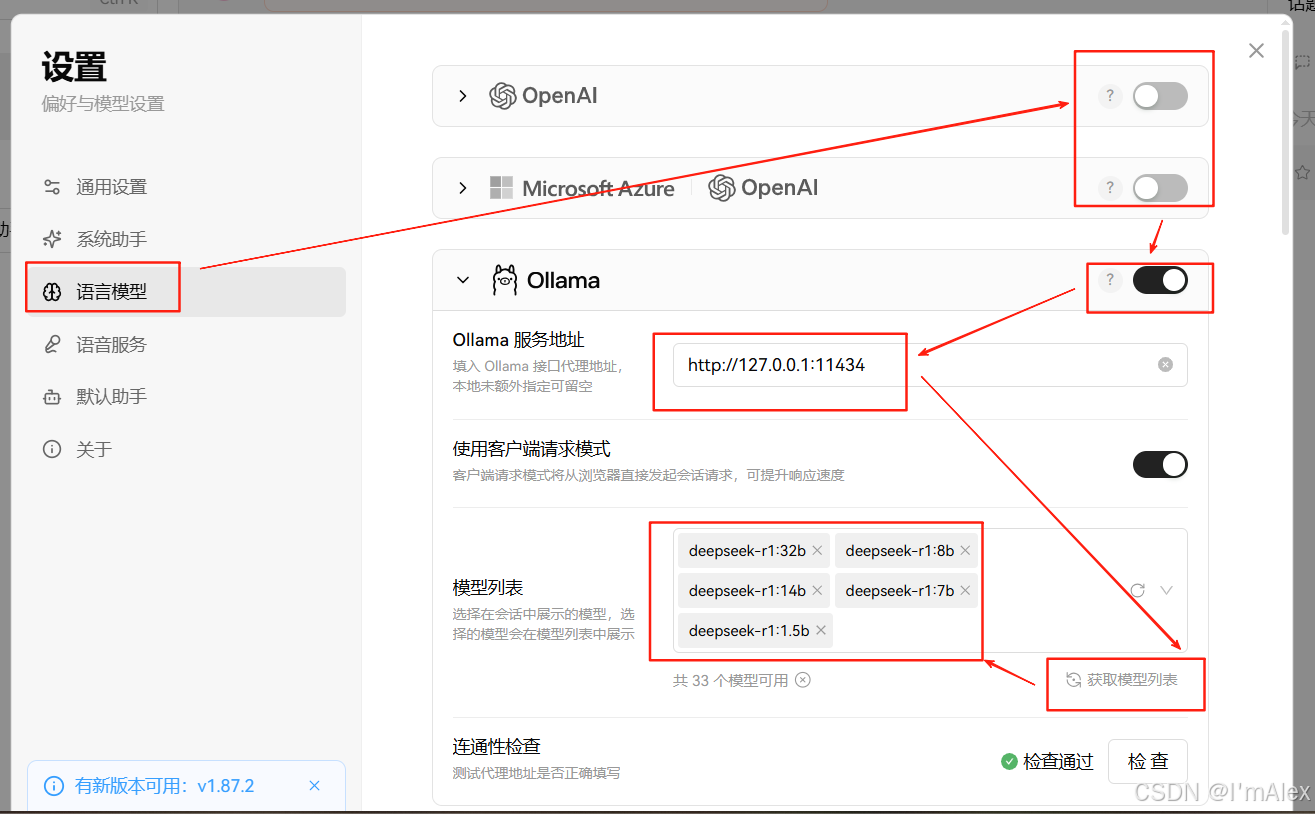
如上图所示,按照箭头指示顺序,进行配置。选择语言模型,关闭除Ollama外的其他所有模型服务,然后配置Ollama服务地址为http://127.0.0.1:11434,然后点击模型列表区域右下角的获取模型列表按钮,将从1.5b到32b的所有DeepSeek-r1模型选择即可。
4.4 选择DeepSeek模型
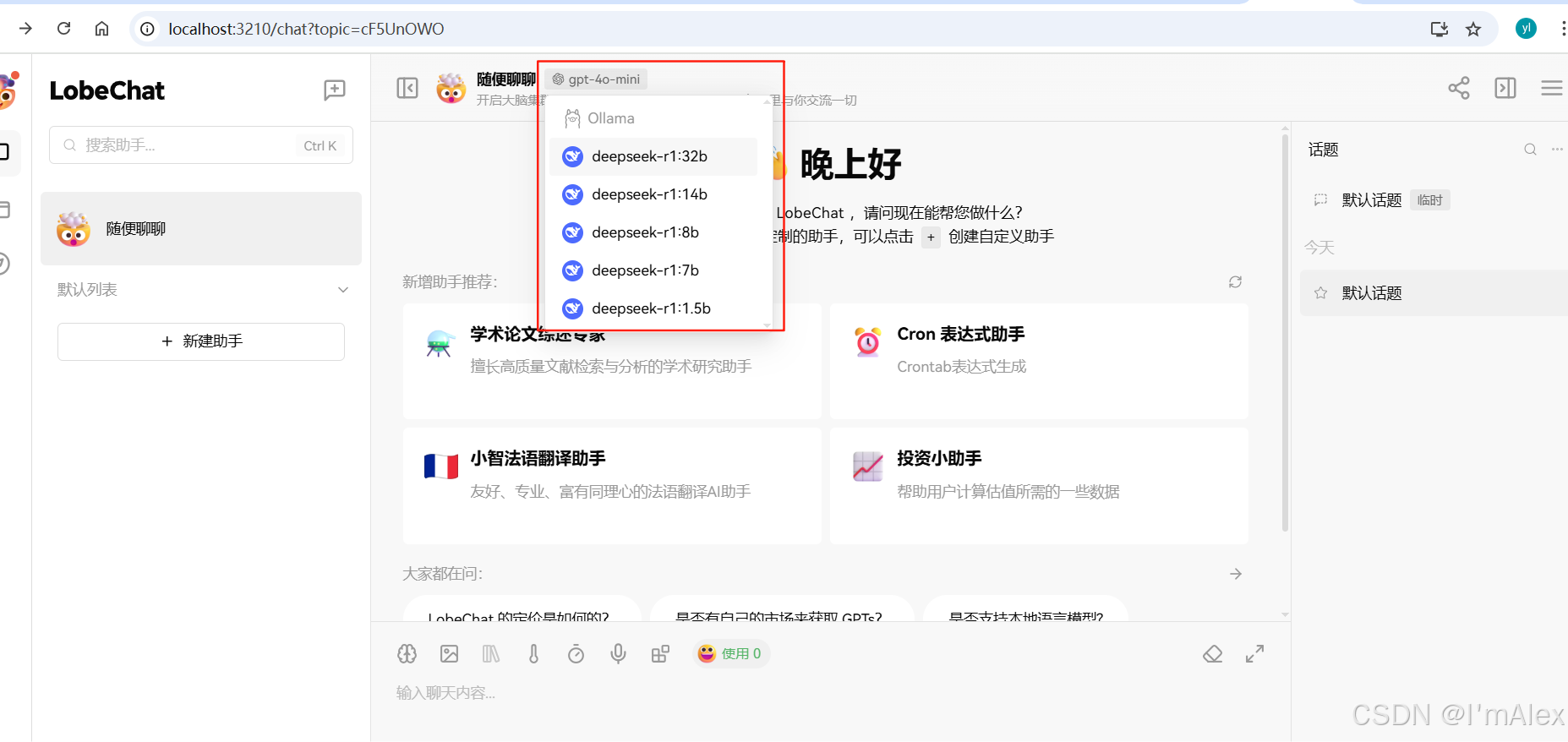
回到LobeChat对话页之后。在网页顶部切换使用deepseek-r1-32b。
4.5 畅游DeepSeek
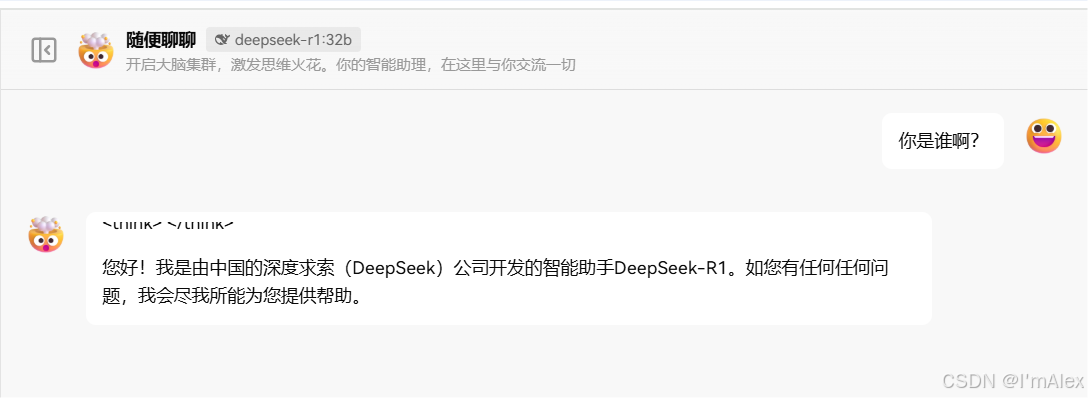
如上图所示,我们问下:你是谁啊?,大模型回复说:您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。。到这里的,基本的配置流程就完成了。接下来,你就可以畅享大模型带来的技术革新了。
6. 总结:GpuGeek+DeepSeek打造高效AI开发闭环
通过在GpuGeek平台搭建DeepSeek大模型服务,开发者能充分利用前者的高性能算力和便捷部署能力,结合后者的强大推理与生成优势,快速构建各类AI应用。从环境准备到实战部署,整个流程清晰可控,且成本效益突出,尤其适合中小团队和个人开发者。
无论是智能客服、代码辅助,还是科研数据分析,GpuGeek与DeepSeek的组合都能提供稳定高效的解决方案。建议开发者从基础模型开始尝试,逐步探索模型微调、多模态融合等进阶功能,释放大模型的更多潜力。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











