







第5章:指令级并行--硬件方法
指令级并行 🌟🌟
指令级并行:指指令之间存在的一种并行性,利用它,计算机可以并行执行两条或两条以上的指令。(ILP:Instruction-Level Parallelism)
开发ILP的途径有两种:
- 资源重复,重复设置多个处理部件,让它们同时执行相邻或相近的多条指令;
- 采用流水线技术,使指令重叠并行执行。
本章研究:如何利用各种技术来开发更多的指令级并行(硬件的方法)
5.1指令级并行的概念
- 开发ILP的方法可以分为两大类
- 主要基于硬件的动态开发方法
- 基于软件的静态开发方法
- 流水线处理机的实际CPI
- 实际CPI等于理想流水线的CPI加上各类停顿的时钟周期数
- C P I 流水线 = C P I 理想 + 停 顿 结 构 冲 突 + 停 顿 数 据 冲 突 + 停 顿 控 制 冲 突 \mathrm{CPI}_{\text {流水线 }}=\mathrm{CPI}_{\text {理想 }}+停顿_{结构冲突}+ 停顿_{数据冲突}+ 停顿_{控制冲突} CPI流水线 =CPI理想 +停顿结构冲突+停顿数据冲突+停顿控制冲突
- 理想CPI是衡量流水线最高性能的一个指标。
- IPC:Instructions Per Cycle(每个时钟周期完成的指令条数)
-基本程序块 - 基本程序块:一串连续的代码除了入口和出口以外,没有其他的分支指令和转入点。
- 程序平均每4~7条指令就会有一个分支。
- 实际CPI等于理想流水线的CPI加上各类停顿的时钟周期数
- 循环级并行:使一个循环中的不同循环体并行执行。
- 开发循环的不同迭代之间存在的并行性
- 是指令级并行研究的重点之一
-

- 最基本的开发循环级并行的技术
- 循环展开(loop unrolling)技术
- 采用向量指令和向量数据表示
5.2相关与指令级并行
相关与流水线冲突
- 相关的类型有三种:
- 数据相关
- 名相关
- 控制相关
- 流水线冲突是指对于具体的流水线来说,由相关的存在,使得指令流中的下一条指令不能在指的时钟周期执行。
- 流水线冲突的类型有三种:
- 结构冲突
- 数据冲突
- 控制冲突
- 流水线冲突的类型有三种:
- 相关是程序固有的一种属性,它反映了程序中指令之间的相互依赖关系。
- 具体的一次相关是否会导致实际冲突的发生以及该冲突会带来多长的停顿,则是流水线的属性。
可以从两个方面来解决相关问题
- 保持相关,但避免发生冲突
- 指令调度(编译器或硬件)
- 通过代码调换,消除相关
- 只有在可能会导致错误的情况下,才保持程序顺序。
- 程序顺序(Program Order):由原来程序确定的在完全串行方式下指令的执行顺序。
- 控制相关并不是一个必须严格保持的关键属性。
- 对于正确地执行程序来说,必须保持的最关键的两个属性是:数据流和异常行为。
- 保持异常行为是指:无论怎么改变指令的执行顺序,都不能改变程序中异常的发生情况。此条件通常被弱化为:指令执行顺序的改变不能导致程序中发生新的异常。
- 数据流:指数据值从其产生者指令到其消费者指令的实际流动。
- 分支指令使得数据流具有动态性,因为一条指令有可能数据相关于多条先前的指令。
- 分支指令的执行结果决定了哪条指令真正是所需数据的产生者。
- 有时,不遵守控制相关既不影响异常行为,也不改变数据流。
- 可以大胆地进行指令调度,把失败分支中的指令调度到分支指令之前。
- 对于正确地执行程序来说,必须保持的最关键的两个属性是:数据流和异常行为。
- 只有在可能会导致错误的情况下,才保持程序顺序。
5.3指令的动态调度 🌟🌟
- 静态调度
- 依靠编译器对代码进行静态调度,以减少相关和冲突。
- 它不是在程序执行的过程中、而是在编译期间进行代码调度和优化。
- 通过把相关的指令拉开距离来减少可能产生的停顿。
- 动态调度 ⭐⭐
- 在程序的执行过程中,依靠专门硬件对代码进行调度,减少数据相关导致的停顿。
- 优点:
- 能够处理一些在编译时情况不明的相关(比如涉及到存储器访问的相关),并简化了编译器;
- 能够使本来是面向某一流水线优化编译的代码在其它的流水线(动态调度)上也能高效地执行。
- 以硬件复杂性的显著增加为代价
5.3.1 动态调度的基本思想
到目前为止我们所使用流水线的最大的局限性:指令是按序流出和按序执行的
//考虑下面一段代码:
DIV.D F4,F0,F2
ADD.D F10,F4,F6
SUB.D F12,F6,F14
//ADD.D指令与DIV.D指令关于F4相关,导致流水线停顿。
//SUB.D指令与流水线中的任何指令都没有关系,但也因此受阻。
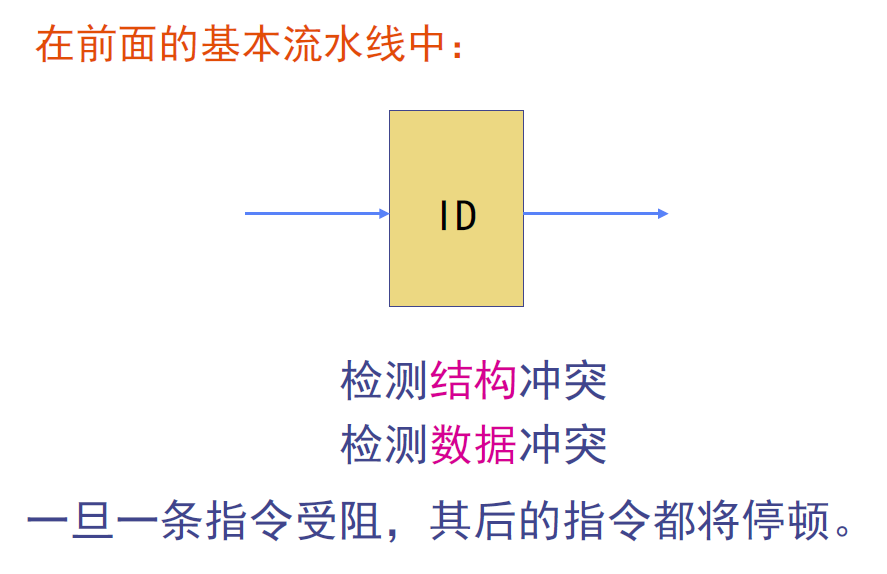
为了使上述指令序列中的SUB.D指令能继续执行下去,必须把指令流出的工作拆分为两步:
- 检测结构冲突
- 等待数据冲突消失
- 只要检测到没有结构冲突,就可以让指令流出。并且流出后的指令一旦其操作数就绪就可以立即执行。
修改后的流水线是乱序执行的
- 乱序执行
- 指令的执行顺序与程序顺序不相同
- 指令的完成也是乱序完成的
- 即指令的完成顺序与程序顺序不相同。
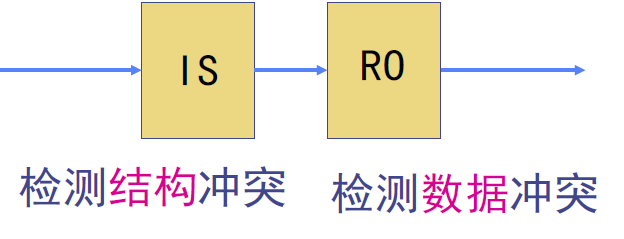
- 为了支持乱序执行,我们将5段流水线的译码阶段再分为两个阶段:
- 流出(Issue,IS):指令译码,检查是否存在结构冲突。(in-order issue)
- 读操作数(Read Operands,RO):等待数据冲突消失,然后读操作数(out of order execution)
-
- 在前述5段流水线中,是不会发生WAR冲突和WAW冲突的。但乱序执行就使得它们可能发生了。
- 动态调度的流水线支持多条指令同时处于执行当中。
- 要求:具有多个功能部件、或者功能部件流水化、或者兼而有之。
- 指令乱序完成带来的最大问题:异常处理比较复杂
- 动态调度的处理机要保持正确的异常行为:对于一条会产生异常的指令来说,只有当处理机确切地知道该指令将被执行时,才允许它产生异常。
- 即使保持了正确的异常行为,动态调度处理机仍可能发生不精确异常。
- 不精确异常:当执行指令i导致发生异常时,处理机的现场(状态)与严格按程序顺序执行时指令i的现场不同。
- 发生不精确异常的两个原因:因为当发生异常(设为指令i)时:
- 流水线可能已经执行完按程序顺序是位于指令i之后的指令;
- 流水线可能还没完成按程序顺序时指令i之前的指令。
- 不精确异常使得在异常处理后难以接着继续执行程序。
- 发生不精确异常的两个原因:因为当发生异常(设为指令i)时:
- 精确异常:如果发生异常时,处理机的现场跟严格按程序顺序执行时指令i的现场相同。
- 不精确异常:当执行指令i导致发生异常时,处理机的现场(状态)与严格按程序顺序执行时指令i的现场不同。
- 记分牌算法和Tomasulo算法是两种比较典型的动态调度算法。
5.3.2 记分牌动态调度算法
- 记分牌的目标:在没有结构冲突时,尽可能早地执行没有数据冲突的指令,实现每个时钟周期执行一条指令。
- 记分牌负责和管理指令的流出和执行,也包括检测所有的冲突。
- 要发挥指令乱序执行的好处,必须有多条指令同时处于执行阶段。
- 比如:

- 比如:
- 采用了记分牌的MIPS处理器的基本结构
- 每条指令都要经过记分牌
- 记分牌负责相关检测并控制指令的流出和执行。
指令在采用记分牌的流水线中的处理步骤
每条指令的执行过程分为4段(主要考虑浮点操作)
(记分牌主要用于浮点部件才有意义,因为其他部件的操作延迟都很小)
- 流出
- 如果当前流出指令所需的功能部件空闲,并且所有其他正在执行的指令的目的寄存器与该指令的不同,记分牌就向功能部件流出该指令,并修改记分牌内部的记录表。
- 解决了WAW冲突
- 读操作数
- 记分牌监测源操作数的可用性,如果数据可用,它就通知功能部件从寄存器中读出源操作数并开始执行。
- 动态地解决了RAW冲突,并导致指令可能乱序开始。
- 流出和读操作数段合起来完成了5段流水线的ID的功能。
- 执行
- 取到操作数后,功能部件开始执行。当产生出结果后,就通知记分牌它已经完成执行。
- 在浮点流水线中,这一段可能要占用多个时钟周期。
- 这步相当于5段流水线中的EX段
- 写结果
- 记分牌一旦知道执行部件完成了执行,就检测是否存在WAR冲突。如果不存在,或者原有的WAR冲突已消失,记分牌就通知功能部件把结果写入目的寄存器,并释放该指令使用的所有资源。
- 这步这步相当于5段流水线中的WB段
- 如果检测到WAR冲突,就不允许该指令将结果写到目的寄存器。这发生在以下情况:
- 前面的某条指令(按顺序流出)还没有读取操作数;
- 而且:其中某个源操作数寄存器与本指令的目的寄存器相同。
- 在这种情况下,记分牌必须等待,直到该冲突消失。
记分牌中记录信息的构成
- 指令状态表:记录正在执行的各条指令已经进入到了哪一段。
- 功能部件状态表:记录各个功能部件的状态。每个功能部件有一项,每一项由以下9个字段组成:
- Busy:忙标志,指出功能部件是否忙。初值为“no;
- Op:该功能部件正在执行或将要执行的操作;
- Fi:目的寄存器编号;
- Fj,Fk:源寄存器编号;
- Qj,Qk:指出向源寄存器Fj、Fk写数据的功能部件;
- Rj,Rk:标志位,为“yes”表示Fj,Fk中的操作数就绪且还未被取走。否则就被置为“no”。
- 结果寄存器状态表Result:每个寄存器在该表中有一项,用于指出哪个功能部件(编号)将把结果写入该寄存器。
- 如果当前正在运行的指令都不以它为目的寄存器,则其相应项置为“no”。
- Result各项的初值为“no”(全0)。
记分牌的性能受限于以下几个方面:
- 程序代码中可开发的并行性,即是否存在可以并行执行的不相关的指令。
- 记分牌的容量
- 记分牌的容量决定了流水线能在多大范围内寻找不相关指令。流水线中可以同时容纳的指令数量称为指令窗口。
- 功能部件的数目和种类
- 功能部件的总数决定了结构冲突的严重程度。
- 反相关和输出相关。
- 它们引起计分牌中WAR和WAW冲突。
5.3.3 Tomasulo算法
基本思想
- 记录和检测指令相关,操作数一旦就绪就立即执行,把发生RAW冲突的可能性减少到最小;
- 通过寄存器换名来消除WAR冲突和WAW冲突
基于Tomasulo算法的MIPS处理器浮点部件的基本结构
- 保留站(reservation station)
- 每个保留站中保存一条已经流出并等待到本功能部件执行的指令(相关信息)。
- 包括:操作码、操作数以及用于检测和解决冲突的信息。
- 在一条指令流出到保留站的时候,如果该指令的源操作数已经在寄存器中就绪,则将之取到该保留站中。
- 如果操作数还没有计算出来,则在该保留站中记录将产生这个操作数的保留站的标识。
- 浮点加法器有3个保留站:ADD1,ADD2,ADD3
- 浮点乘法器有两个保留站:MULT1,MULT2
- 每个保留站都有一个标识字段,唯一地标识了该保留站。
- 公共数据总线CDB - (一条重要的数据通路)
- 所有功能部件的计算结果都是送到CDB上,由它把这些结果直接送到(播送到)各个需要该结果的地方。
- 在具有多个执行部件且采用多流出(即每个时钟周期流出多条指令)的流水线中,需要采用多条CDB。
- load缓冲器和store缓冲器
- 存放读/写存储器的数据或地址
- load缓冲器的作用有3个:
- 存放用于计算有效地址的分量;
- 记录正在进行的load访存,等待存储器的响应;
- 保存已经完成了的load的结果(即从存储器取来的数据),等待CDB传输。
- store缓冲器的作用有3个:
- 存放用于计算有效地址的分量;
- 保存正在进行的store访存的目标地址,该store正在等待存储数据的到达;
- 保存该store的地址和数据,直到存储部件接收。
- 浮点寄存器FP
- 共有16个浮点寄存器:F0,F2,F4,…,F30。
- 它们通过一对总线连接到功能部件,并通过CDB连接到store缓冲器。
- 指令队列
- 指令部件送来的指令放入指令队列
- 指令队列中的指令按先进先出的顺序流出
- 运算部件
- 浮点加法器完成加法和减法操作
- 浮点乘法器完成乘法和除法操作
在Tomasulo算法中,寄存器换名是通过保留站和流出逻辑来共同完成的。
- 当指令流出时,如果其操作数还没有计算出来,则将该指令中相应的寄存器号换名为将产生这个操作数的保留站的标识。
- 指令流出到保留站后,其操作数寄存器号或者换成了数据本身(如果该数据已经就绪),或者换成了保留站的标识,不再与寄存器有关系。
算法特点
- 冲突检测和指令执行控制是分布的。
- 每个功能部件的保留站中的信息决定了什么时候指令可以在该功能部件开始执行。
- 计算结果通过CDB直接从产生它的保留站传送到所有需要它的功能部件,而不用经过寄存器。
指令执行的步骤
使用Tomasulo算法的流水线需3段:
- 流出:从指令队列的头部取一条指令。
- 如果该指令的操作所要求的保留站有空闲的,就把该指令送到该保留站(设为r)。
- 如果其操作数在寄存器中已经就绪,就将这些操作数送入保留站r。
- 如果其操作数还没有就绪,就把将产生该操作数的保留站的标识送入保留站r。
- 一旦被记录的保留站完成计算,它将直接把数据送给保留站r。
- (寄存器换名和对操作数进行缓冲,消除WAR冲突)
- 完成对目标寄存器的预约工作
- (消除了WAW冲突)
- 如果没有空闲的保留站,指令就不能流出。
- (发生了结构冲突)
- 如果该指令的操作所要求的保留站有空闲的,就把该指令送到该保留站(设为r)。
- 执行
- 当两个操作数都就绪后,本保留站就用相应的功能部件开始执行指令规定的操作。
- load和store指令的执行需要两个步骤:
- 计算有效地址(要等到基地址寄存器就绪)
- 把有效地址放入load或store缓冲器
- 写结果
- 功能部件计算完毕后,就将计算结果放到CDB上,所有等待该计算结果的寄存器和保留站(包括store缓冲器)都同时从CDB上获得所需要的数据。
5.4动态分支预测技术
所开发的ILP越多,控制相关的制约就越大,分支预测就要有更高的准确度。
本节中介绍的方法对于每个时钟周期流出多条指令(若为n条,就称为n流出)的处理机来说非常重要。
- 在n-流出的处理机中,遇到分支指令的可能性增加了n倍。
- 要给处理器连续提供指令,就需要准确地预测分支。
动态分支预测:在程序运行时,根据分支指令过去的表现来预测其将来的行为。
- 如果分支行为发生了变化,预测结果也跟着改变。
- 相比静态预测,有更好的预测准确度和适应性。
分支预测的有效性取决于:
- 预测的准确性
- 预测正确和不正确两种情况下的分支开销
- 决定分支开销的因素:
- 流水线的结构
- 预测的方法
- 预测错误时的恢复策略等
- 决定分支开销的因素:
采用动态分支预测技术的目的
- 预测分支是否成功
- 尽快找到分支目标地址(或指令)
- (避免控制相关造成流水线停顿)
需要解决的关键问题:
- 如何记录分支的历史信息,要记录哪些信息
- 如何根据这些信息来预测分支的去向,甚至提前
取出分支目标处的指令
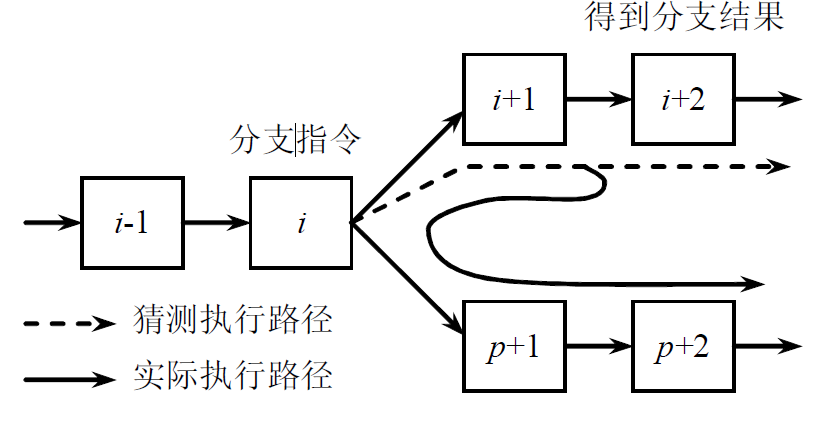
在预测错误时,要作废已经预取和分析的指令,恢复现场,并从另一条分支路径重新取指令。
采用分支历史表BHT
分支历史表BHT(Branch History Table)
- 最简单的动态分支预测方法
- 用BHT来记录分支指令最近一次或几次的执行情况(成功还是失败),并据此进行预测
分类
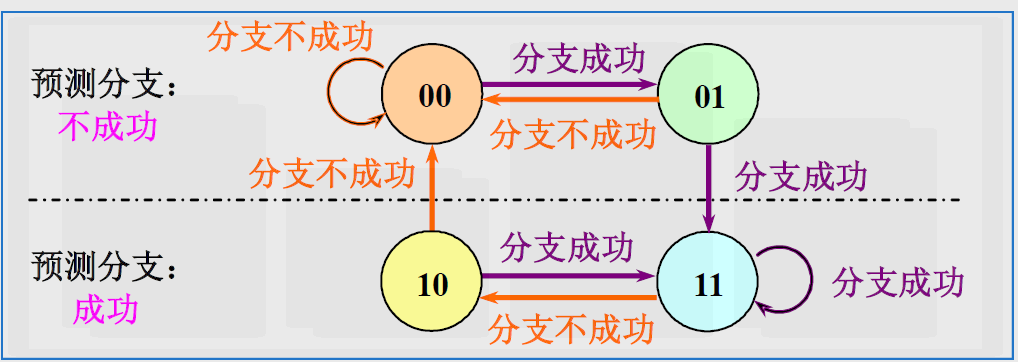
- 只有1个预测位的分支预测
- 记录分支指令最近一次的历史,BHT中只需要1位二进制位。
- 采用两位二进制位来记录历史
- 提高预测的准确度
- 研究结果表明:两位分支预测的性能与n位(n>2)分支预测的性能差不多。
- 两位分支预测的状态转换如下所示:
- 步骤:
- 分支预测
- 当分支指令到达译码段(ID)时,根据从BHT读出的信息进行分支预测
- 若预测正确,就继续处理后续的指令,流水线没有断流。否则,就要作废已经预取和分析的指令,恢复现场,并从另一条分支路径重新取指令
- 状态修改
- 分支预测
BHT方法
- BHT方法中,只对分支是否成功进行预测,对分支目标地址没有提供支持
- 适用于:在判定分支是否成功所需的时间大于确定分支目标地址所需的时间。
- 研究结果表明:对于SPEC89测试程序来说,具有大小为4KB的BHT的预测准确率为82%~99%。
- 一般来说,采用4KB的BHT就可以了。
- BHT可以跟分支指令一起存放在指令Cache中,也可以用一块专门的硬件来实现。
采用分支目标缓冲器BTB
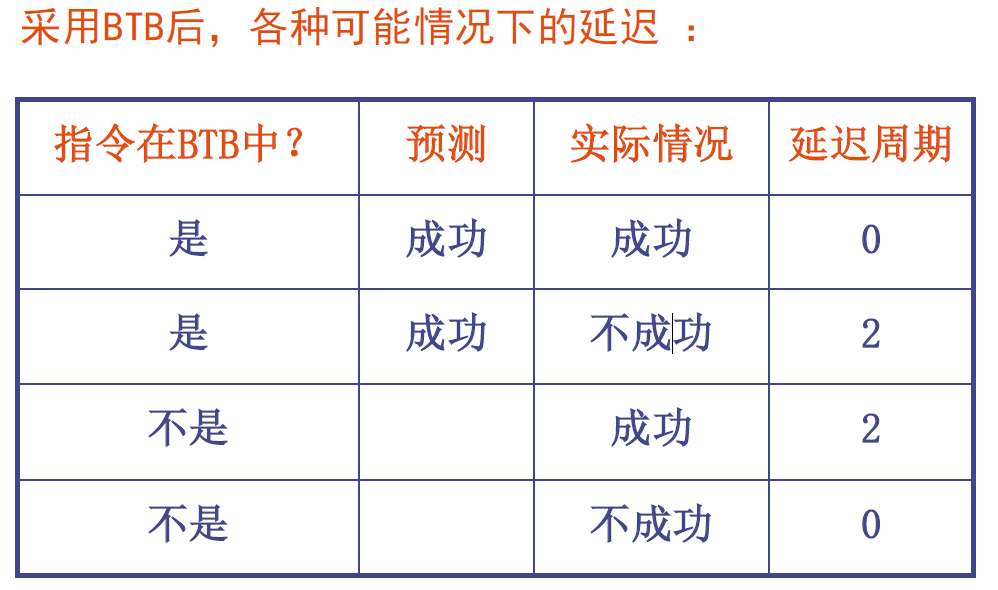
目标:将分支的开销降为0
方法:分支目标缓冲
- 将分支成功的分支指令的地址和它的分支目标地址都放到一个缓冲区中保存起来,缓冲区以分支指令的地址作为标识。
- 这个缓冲区就是分支目标缓冲器(Branch-Target Buffer,简记为BTB,或者分支目标Cache(Branch-Target Cache)。
BTB的结构
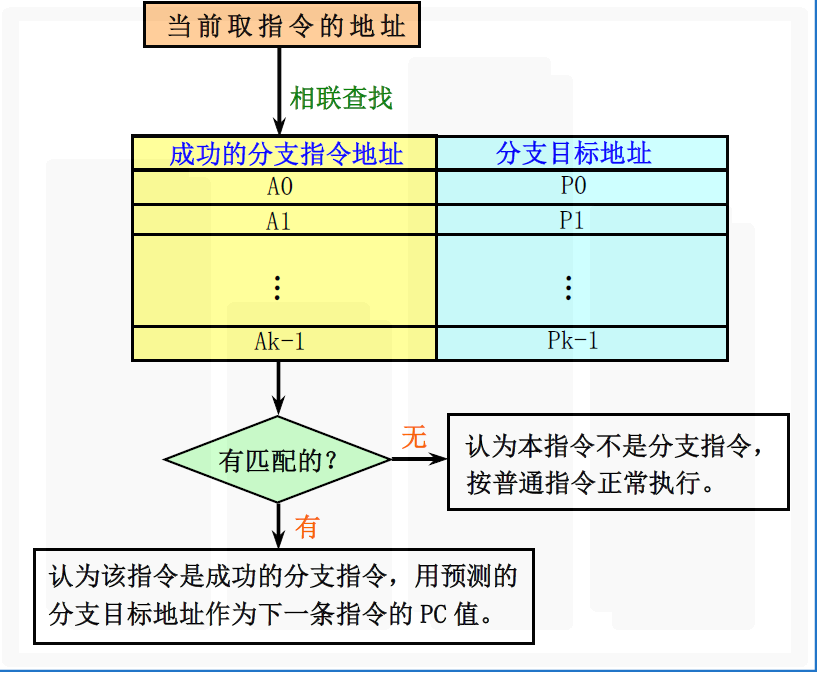
- 看成是用专门的硬件实现的一张表格
- 表格中的每一项至少有两个字段:
- 执行过的成功分支指令的地址(作为该表的匹配标识)
- 预测的分支目标地址。
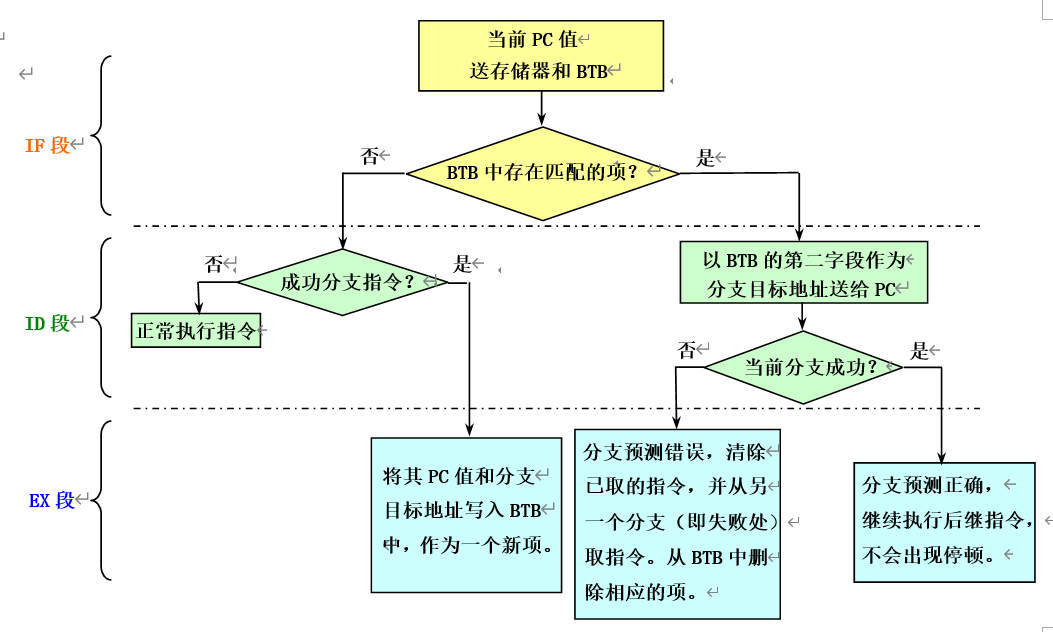
采用BTB后,在流水线各个阶段所进行的相关操作:
BTB的另一种形式
在分支目标缓冲器中增设一个至少是两位的“分支历史表”字段
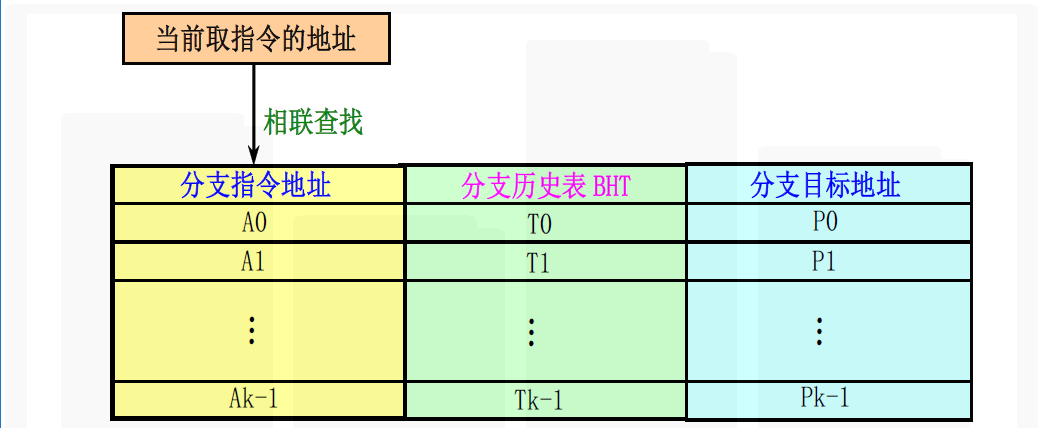
- 分支历史表是用来预测转移方向
- 这种方法是BTB和BHT的结合
另一种形式
更进一步,在表中对于每条分支指令都存放若干条分支目标处的指令,就形成了分支目标指令缓冲器。
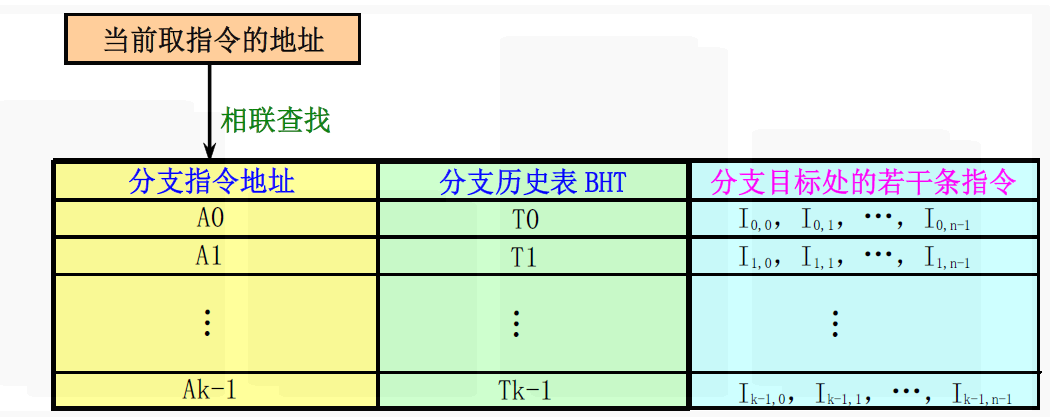
基于硬件的前瞻执行
前瞻执行(speculation)的基本思想:对分支指令的结果进行猜测,并假设这个猜测总是对的,然后按这个猜测结果继续取、流出和执行后续的指令。
只是执行指令的结果不是写回到寄存器或存储器,而是写入一个称为**再定序缓冲器ROB(ReOrder Buffer)**中。
等到相应的指令得到“确认”(commit)(即确实是应该执行的)之后,才将结果写入寄存器或存储器。
基于硬件的前瞻执行结合了3种思想
- 动态分支预测。用来选择后续执行的指令。
- 在控制相关的结果尚未出来之前,前瞻地执行后续指令。
- 用动态调度对基本块的各种组合进行跨基本块的调度。
对Tomasulo算法加以扩充,就可以支持前瞻执行
把Tomasulo算法的写结果和指令完成加以区分,分成两个不同的段:
- 写结果段
- 把前瞻执行的结果写到ROB中;
- 通过CDB在指令之间传送结果,供需要用到这些结果的指令使用。
- 指令确认段
- 在分支指令的结果出来后,对相应指令的前瞻执行给予确认。
- 如果前面所做的猜测是对的,把在ROB中的结果写到寄存器或存储器。
- 如果发现前面对分支结果的猜测是错误的,那就不予以确认,并从那条分支指令的另一条路径开始重新执行。
实现前瞻的关键思想:
允许指令乱序执行,但必须顺序确认。
在指令被确认之前,不允许它进行不可恢复的操作。
ROB中每一项的组成字段
- 指令类型
- 指出该指令是分支指令、store指令或寄存器操作指令。
- 目标地址
- 给出指令执行结果应写入的目标寄存器号(如果是load和ALU指令)或存储器单元的地址(如果是store指令)。
- 数据值字段
- 用来保存指令前瞻执行的结果,直到指令得到确认。
- 就绪字段
- 指出指令是否已经完成执行并且数据已就绪。
Tomasulo算法中保留站的换名功能是由ROB来完成的。
采用前瞻执行机制后,指令的执行步骤:
(在Tomasulo算法的基础上改造的)
- 流出
- 从浮点指令队列的头部取一条指令。
- 如果有空闲的保留站(设为r)且有空闲的ROB项(设为b),就流出该指令,并把相应的信息放入保留站r和ROB项b。
- 如果保留站或ROB全满,便停止流出指令,直到它们都有空闲的项。
- 执行
- 如果有操作数尚未就绪,就等待,并不断地监测CDB。(检测RAW冲突)
- 当两个操作数都已在保留站中就绪后,就可以执行该指令的操作。
- load指令操作分两步:有效地址计算,读取数据
- store指令进行有效地址计算
- 写结果
- 当结果产生后,将该结果连同本指令在流出段所分配到的ROB项的编号放到CDB上,经CDB写到ROB以及所有等待该结果的保留站。
- 释放产生该结果的保留站。
- store指令在本阶段完成,其操作为:
- 如果要写入存储器的数据已经就绪,就把该数据写入分配给该store指令的ROB项。
- 否则,就监测CDB,直到那个数据在CDB上播送出来,才将之写入分配给该store指令的ROB项。
- 确认
- 对分支指令、store指令以及其它指令的处理不同:
- 其它指令(除分支指令和store指令)
- 当该指令到达ROB队列的头部而且其结果已经就绪时,就把该结果写入该指令的目的寄存器,并从ROB中删除该指令。
- store指令
- 处理与上面的类似,只是它把结果写入存储器。
- 分支指令
- 当预测错误的分支指令到达ROB队列的头部时,清空ROB,并从分支指令的另一个分支重新开始执行。
- (错误的前瞻执行)
- 当预测正确的分支指令到达ROB队列的头部时,该指令执行完毕。
- 当预测错误的分支指令到达ROB队列的头部时,清空ROB,并从分支指令的另一个分支重新开始执行。
前瞻执行
- 通过ROB实现了指令的顺序完成。
- 能够实现精确异常。
- 很容易地推广到整数寄存器和整数功能单元上。
- 主要缺点:所需的硬件太复杂。
5.5多指令流出技术
在每个时钟周期内流出多条指令,CPI<1。
单流出和多流出处理机执行指令的时空图对比
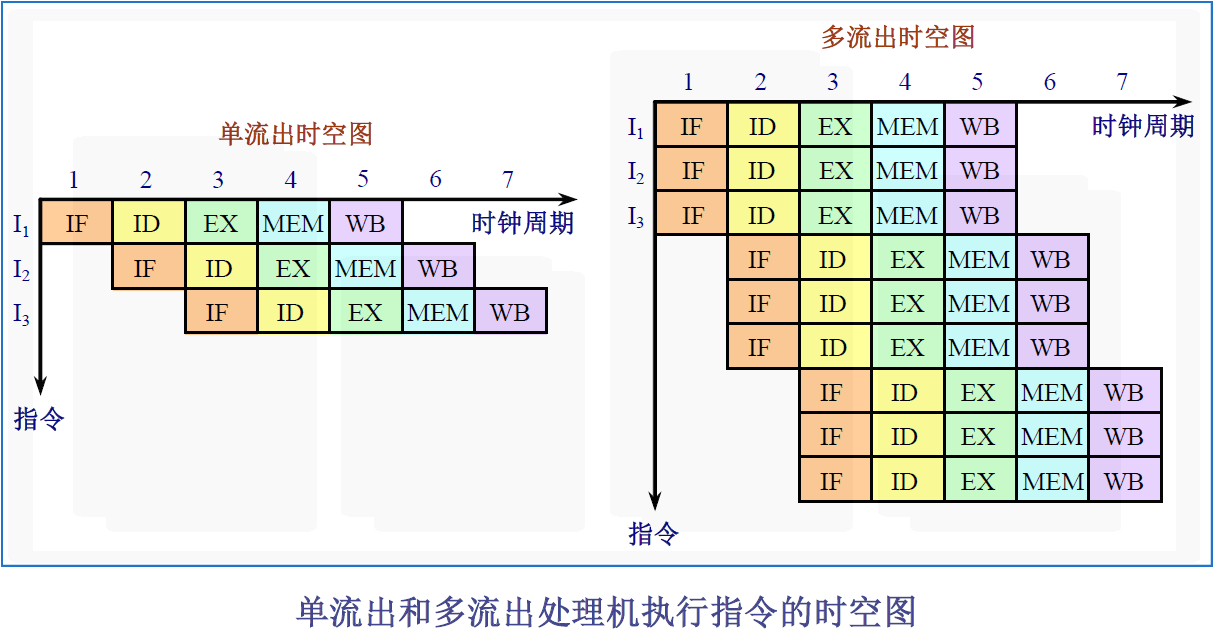
多流出处理机有两种基本风格
- 超标量
- 在每个时钟周期流出的指令条数不固定,依代码的具体情况而定。(有上限)
- 设这个上限为n,就称该处理机为n-流出。
- 可以通过编译器进行静态调度,也可以基于Tomasulo算法进行动态调度。
- 超长指令字VLIM
- 在每个时钟周期流出的指令条数是固定的,这些指令构成一条长指令或者一个指令包。
- 指令包中,指令之间的并行性是通过指令显式地表示出来的。
- 指令调度是由编译器静态完成的。
超标量处理机与VLIW处理机相比有两个优点:
-
超标量结构对程序员是透明的,处理机能自己检测下一条指令能否流出,不需要由编译器或专门的变换程序对程序中的指令进行重新排列;
-
即使是没有经过编译器针对超标量结构进行调度优化的代码或是旧的编译器生成的代码也可以运行,当然运行的效果不会很好。
基于静态调度的多流出技术
- 在典型的超标量处理器中,每个时钟周期可流出1到8条指令。
- 指令按序流出,在流出时进行冲突检测。
- 由硬件检测当前流出的指令之间是否存在冲突以及当
前流出的指令与正在执行的指令是否有冲突。
- 由硬件检测当前流出的指令之间是否存在冲突以及当
举例:一个4-流出的静态调度超标量处理机
- 在取指令阶段,流水线将从取指令部件收到1~4条指令(称为流出包)。
- 在一个时钟周期内,这些指令有可能是全部都能流出,也可能是只有一部分能流出。
- 流出部件检测结构冲突或者数据冲突。
- 一般分两阶段实现:
- 第一段:进行流出包内的冲突检测,选出初步判定可以流出的指令;
- 第二段:检测所选出的指令与正在执行的指令是否有冲突。
MIPS处理机实现超标量
假设:每个时钟周期流出两条指令:
1 条 整 数 型 指 令 + 1 条 浮 点 操 作 指 令 1条整数型指令+1条浮点操作指令 1条整数型指令+1条浮点操作指令
其中:把load指令、store指令、分支指令归类为整数型指令。
- 要求:
- 同时取两条指令(64位),译码两条指令(64位)
- 对指令的处理包括以下步骤:
- 从Cache中取两条指令;
- 确定哪几条指令可以流出(0~2条指令)
- 把它们发送到相应的功能部件
- 双流出超标量流水线中指令执行的时空图
- 假设:所有的浮点指令都是加法指令,其执行时间为两个时钟周期
- 为简单起见,图中总是把整数指令放在浮点指令的前面
-
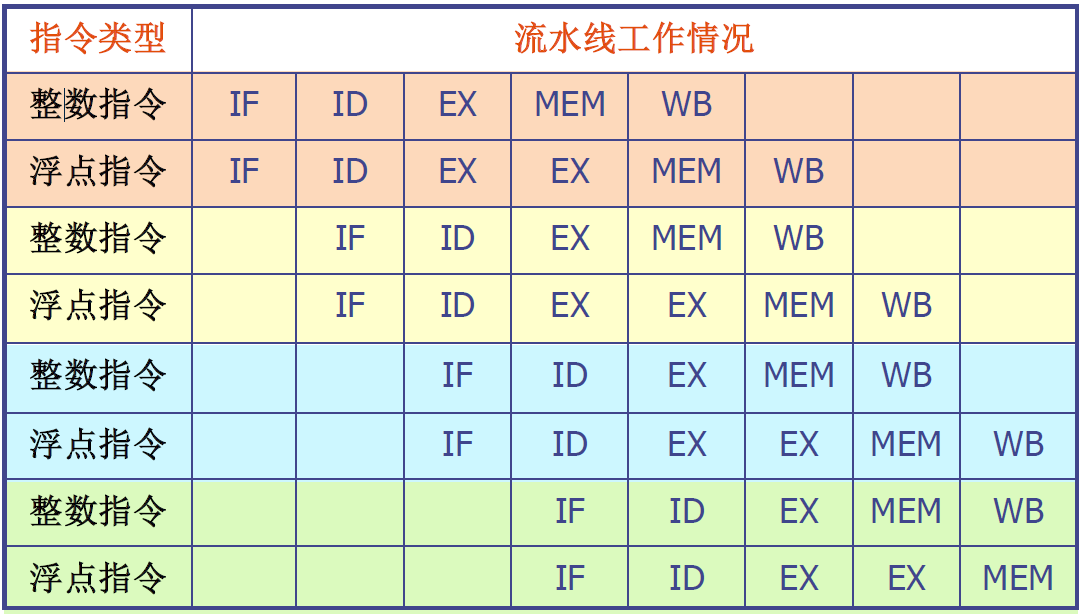
双流出超标量处理机特点
- 采用“1条整数型指令+1条浮点指令”并行流出的方式,需要增加的硬件很少。
- 浮点load或浮点store指令将使用整数部件,会增加对浮点寄存器的访问冲突。
- 增设一个浮点寄存器的读/写端口。
- 由于流水线中的指令多了一倍,定向路径也要增加。
5.5.3 超长指令字流水技术
- 把能并行执行的多条指令组装成一条很长的指令(100多位到几百位)
- 设置多个功能部件;
- 指令字被分割成一些字段,每个字段称为一个操作槽,直接独立地控制一个功能部件;
- 在超长指令字处理机中,在指令流出时不需要进行复杂的冲突检测,而是依靠编译器全部安排好了。
存在的问题:
- 程序代码长度增加了
- 提高并行性而进行的大量的循环展开;
- 指令字中的操作槽并非总能填满
- 解决:采用指令共享立即数字段的方法,或者采用指令压缩存储、调入Cache或译码时展开的方法。
- 采用了锁步机制
- 任何一个操作部件出现停顿时,整个处理机都要停顿。
- 可以设置适当的硬件动态检测机制,允许指令流出后非同步执行。
- 机器代码的不兼容性
- 可以采用机器代码翻译或仿真的方法。
5.5.4 多流出处理器收到的限制
- 程序所固有的指令级并行性
- 硬件实现上的困难
- 超标量和超长指令字处理器固有的技术限制
5.5.5 超流水线处理机
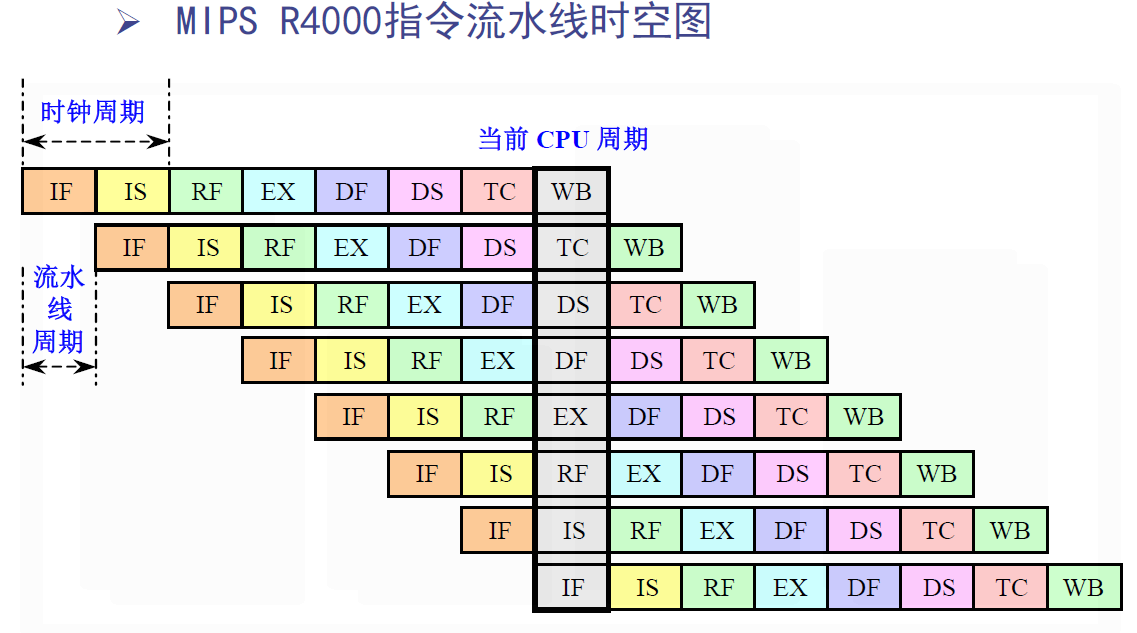
将每个流水段进一步细分,这样在一个时钟周期内能够分时流出多条指令。这种处理机称为超流水线处理机。
对于一台每个时钟周期能流出n条指令的超流水线计算机来说,这n条指令不是同时流出的,而是每隔1/n个时钟周期流出一条指令。
- 实际上该超流水线计算机的流水线周期为1/n个时钟周期。
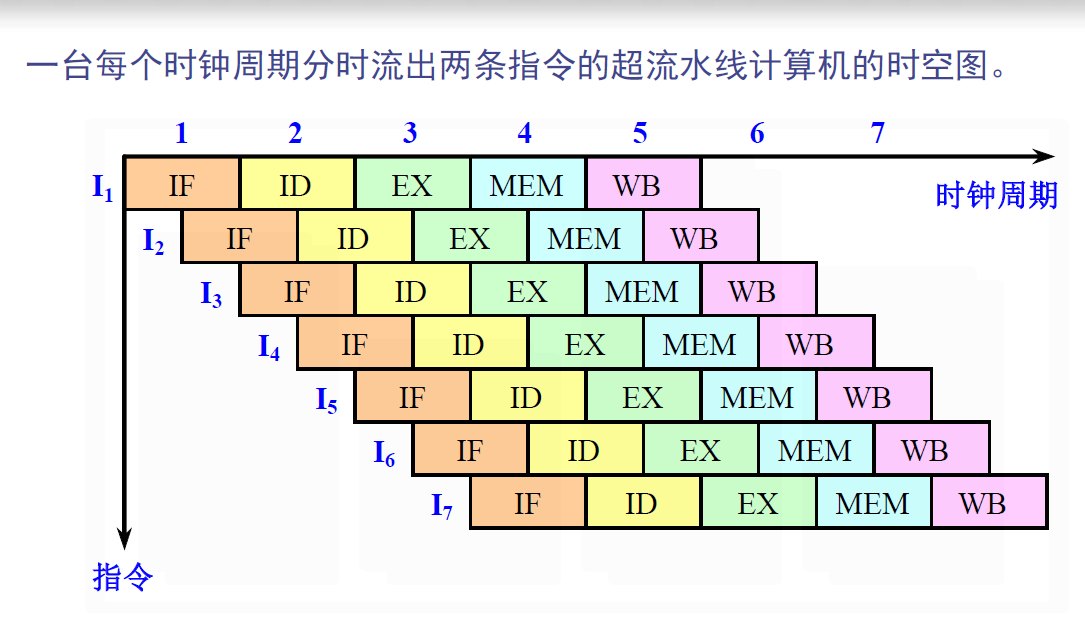
在有的资料上,把指令流水线级数为8或8以上的流水线处理机称为超流水线处理机。
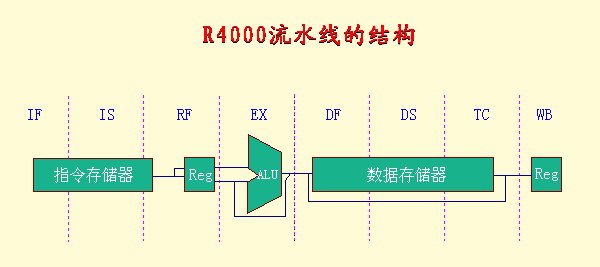
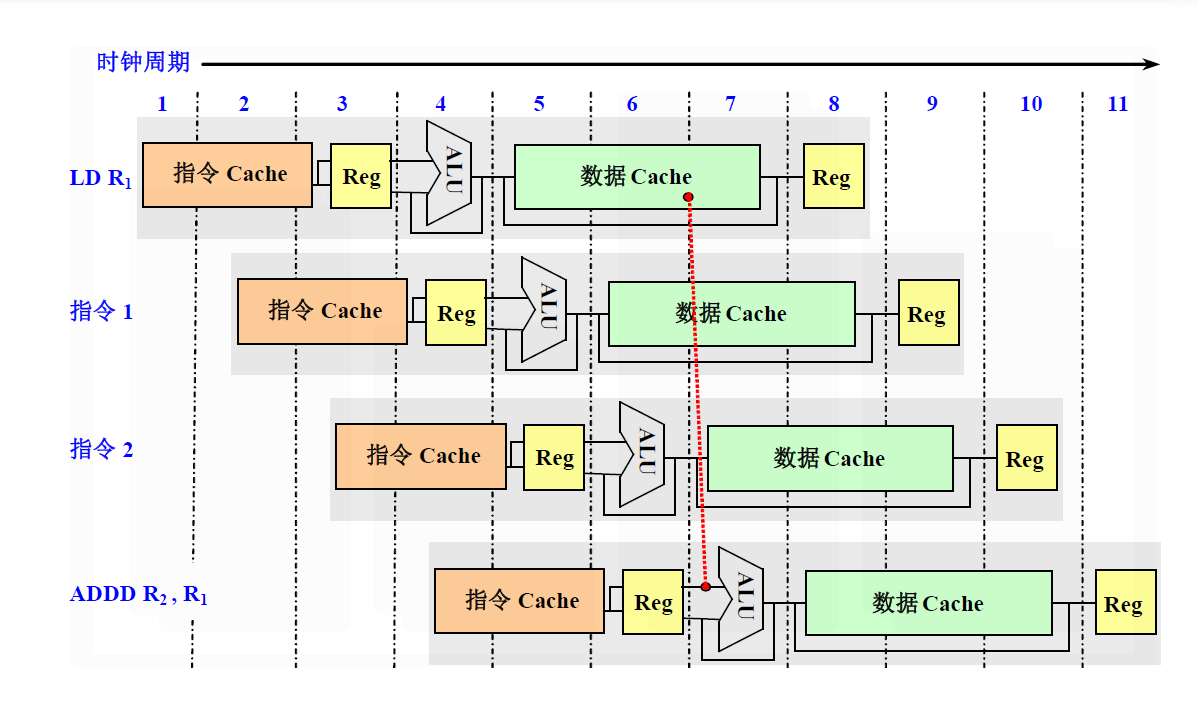
典型的超流水线处理器:SGI公司的MIPS系列R4000
- R4000微处理器芯片内有2个Cache:
- 指令Cache和数据Cache
- 容量都是8KB
- 每个Cache的数据宽度为64位
- R4000的核心处理部件:整数部件
- 一个32×32位的通用寄存器组
- 一个算术逻辑部件(ALU)
- 一个专用的乘法/除法部件
- 浮点部件
- 一个执行部件 --它们可以并行工作
- 浮点乘法部件
- 浮点除法部件
- 浮点加法/转换/求平方根部件
- 一个16×64位的浮点通用寄存器组。浮点通用寄存器组也可以设置成32个32位的浮点寄存器
- 一个执行部件 --它们可以并行工作
- R4000的指令流水线有8级
-

















 1019
1019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











