






1.Selenium常用命令
主要使用的工具包是Selenium。Selenium是一个用于Web应用程序测试的工具,就像真实的用户在操作浏览器一样,可以直接在浏览器中运行。
安装:
pip install selenium
元素定位:
find_element_by_id()
find_element_by_name()
find_element_by_class_name()
find_element_by_tag_name()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_xpath()
find_element_by_css_selector()
xpath
通过元素的ID定位元素:findElement(By.id(“ele”));
通过元素的名称定位元素:findElement(By.name(“ele”));
通过元素的html中的位置定位元素:findElement(By.xpath(“ele”));
通过元素的标签名称定位元素:findElement(By.tagName(“ele”));
通过元素的链接名称定位元素:findElement(By.LinkText(“ele”));
通过元素的类名定位元素:findElement(By.className(“ele”));
通过元素的css定位元素:findElement(By.cssSelector(“ele”);
通过元素的部分链接名称定位元素:findElement(By.pareialLinkText(“ele”));
对ID为ele的元素进行点击操作:driver.findElement(By.id(ele));
dr = webdriver.Firefox()
dr.get()获取打开url网页
dr.set_windows_size()设置浏览器窗口大小
dr.find_element_by_id(‘kw’).clear()#清除内容
dr.find_element_by_id(‘su’).click()#点击
dr.find_element_by_id(‘kw’).send_keys(‘测试’) #发送文字内容
dr.current_url 当前浏览器的url连接
dr.title #网页标题
dr.find_element_by_id(‘kw’).text #元素文本
dr.find_element_by_id(‘kw’).content #元素原网页文本
dr.refresh #刷新
dr.save_screenshot(‘d://a.png’) #屏幕截图
dr.current_window_handle#当前窗体
dr.window_handles #所有窗体
element.submit() #提交
close()关闭单个窗体
quit()关闭所有的窗体
2.下载驱动
注意:
- 根据自己的chrome浏览器的版本选择下载
查看方式:浏览器三点->设置->关于

下载对应版本的驱动,解压之后,把exe文件复制到python的安装目录下。
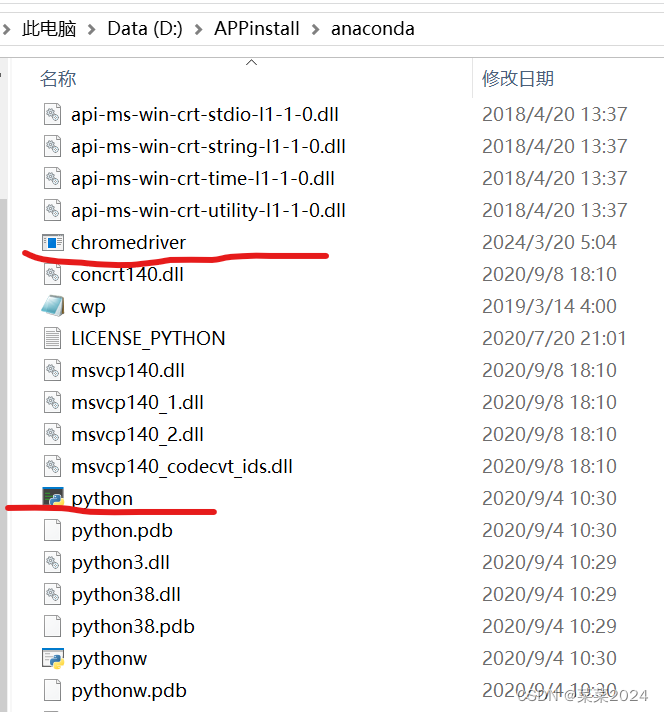
测试一下是否可用:
from selenium import webdriver
driver = webdriver.Chrome()
# driver = webdriver.Edge()
# 打开百度网页
driver.get("http://www.baidu.com")
3.简单百度一下
使用python脚本模拟用户打开浏览器并进行搜索,返回第一个搜索结果
# -*-coding:utf-8-*-
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
# 找到搜索输入接口
input = driver.find_element_by_id("kw")
# 输入搜索值
input.send_keys("python教程")
# 找到搜索接口按钮
searchButton = driver.find_element_by_id("su")
# 模拟点击
searchButton.click()
results = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div.result h3 a"))
)
# 如果有结果,点击第一个链接
if results:
first_result_link = results[0]
# 输出第一个链接
print(first_result_link.get_attribute("href"))
# 点击第一个链接,会打开一个新的窗口
first_result_link.click()
time.sleep(3)
# 关闭浏览器
driver.close()
上述代码执行完成之后,在原始的页面上再打开一个新的页面,3秒之后执行driver.close(),关闭的是第一个搜索页面,新打开的页面并不会关闭。如果我们想要关闭新页面,保留搜索的页面,需要进行页面句柄的转换,如下:
# 报存当前页面句柄
base_window = driver.current_window_handle
# 获取所有页面
all_handles = driver.window_handles
# 遍历页面,如果不予base_window相同,就切换过去
for handle in all_handles:
if handle != base_window :
# 切换到新的页面
driver.switch_to.window(handle)
time.sleep(3)
# 关闭当前页面
driver.close()
要查看网页上搜索按钮对应的ID,你可以使用浏览器的开发者工具(Developer Tools)。以下是在几种常见浏览器中打开开发者工具并查找元素ID的步骤:
Google Chrome
- 打开Google Chrome浏览器。
- 访问你想要查看的网页(比如百度网页)。
- 右键点击你想要查看ID的元素(在这里是搜索按钮)。
- 在弹出的上下文菜单中选择“检查”(Inspect)或使用快捷键Ctrl + Shift + I(Windows/Linux)或Cmd + Option + I(Mac)。
- 这将打开开发者工具,并高亮显示你点击的元素在HTML结构中的位置。
- 在HTML代码中,查找带有id属性的标签。这个id属性的值就是该元素的ID。















 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









