






1.需求背景
在上一篇Python网络爬虫4-实战爬取pdf中,以松下品牌说明书为例说明了网页爬取PDF的分析流程。在实际的应用中,具体代码需要根据不同的网址情况和需求进行更改。
明确要求:
此次,想要爬取苏泊尔品牌下的说明书pdf,同时我们希望每个pdf都有相应的型号说明,并将对应关系存储在excel表格中。
网站分析:
苏泊尔产品说明书官网链接
这里以智能电炖锅为例
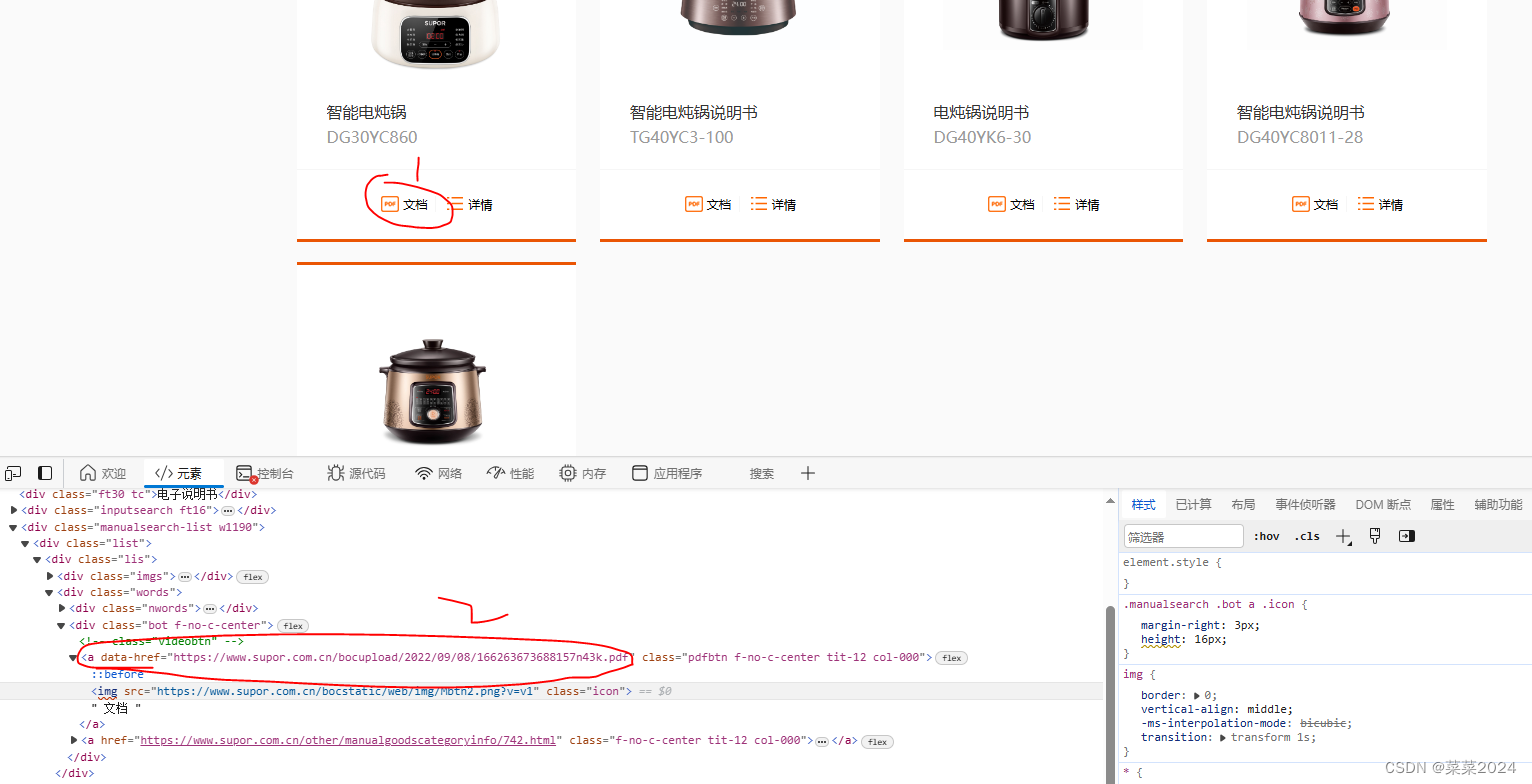
非常幸运,这个网站的pdf链接直接暴露在开发者模式中,没有进行封装,所以我们可以直接使用BeautifulSoup和requests直接获取data-href属性的<a>标签就可以得到pdf链接。
第二个需求,保存pdf对应的产品型号,我们看到网站每个型号是有对应的文字说明的,所以我们要获取其中的文字。
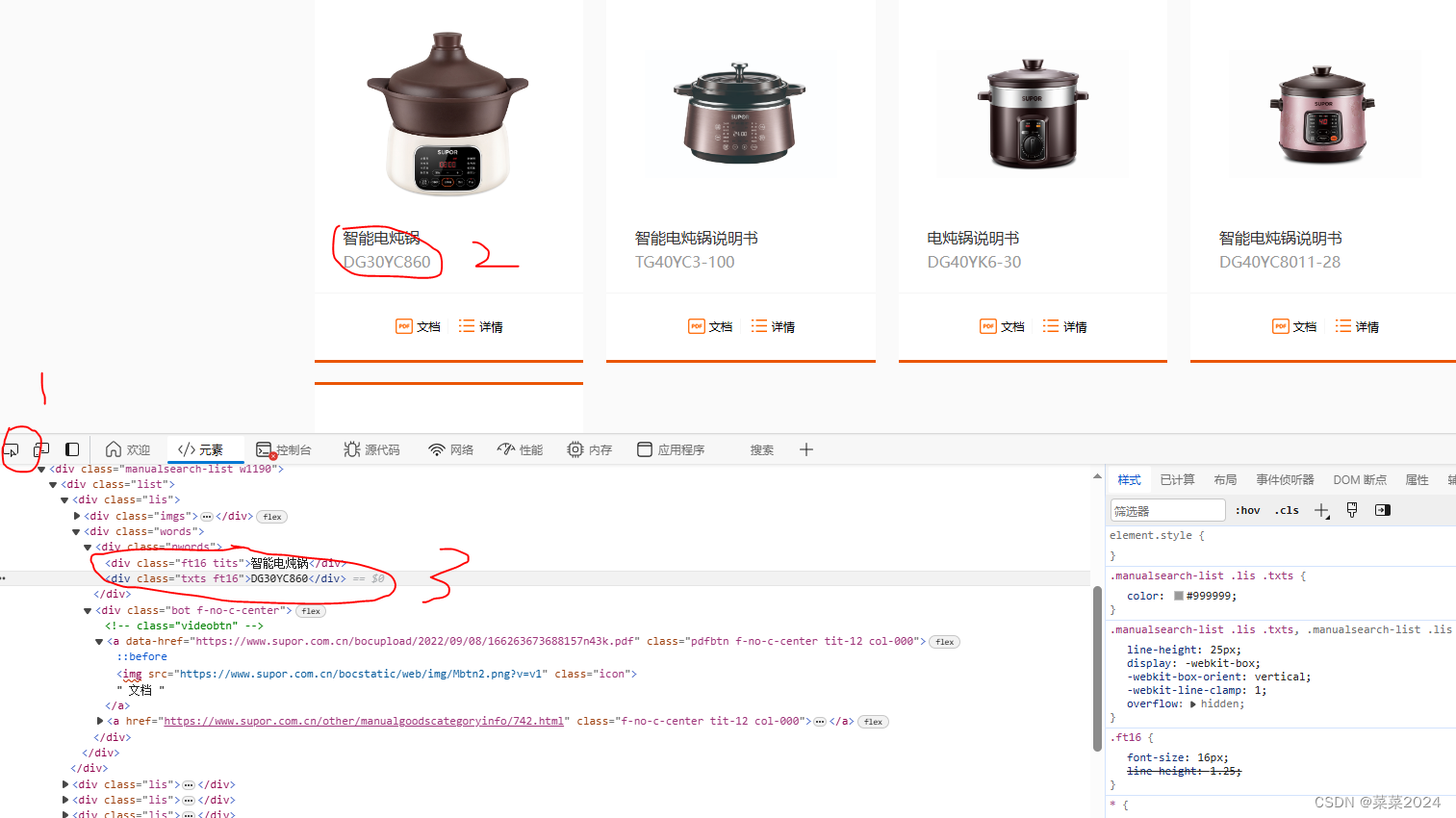
如图所示,点击1,然后点击文字,就可以在下方定位出文字。可以看到,文字和链接都在一个bin中,<div class="words">
所以可以先找到所有的class=words的div标签,再定位文字和链接。
第三:电炖锅只有一页,如果多页如何实现,以及如何直接爬取所有类别。
电饭煲为例,观察网站的规律
https://www.supor.com.cn/other/manualgoodscategorysearch?ctype=2443---->第一页
https://www.supor.com.cn/other/manualgoodscategorysearch/2.html?ctype=2443—>第二页
https://www.supor.com.cn/other/manualgoodscategorysearch/17.html?ctype=2443—>第十七页
for循环,页用变量代替
不同类别又该如何统一实现:
也是观察网站规律,不同类别是有对应ctype的。
ctype=2443—>电饭煲
ctype= 2441–>智能电炖锅
(小白一个,这种办法对我来说是最高效的,如果模拟用户点击,获取每一个大类如电饭煲,获取完之后,切换窗口,再去点击第二个大类电炖锅,对我来说更为复杂,出错率也更高,欢迎大家尝试此种方法,可以在评论区告诉我哦~)
2.代码具体实现
首先实现某一页pdf和文本说明的功能,为了存储所有的文字信息,定义一个类或者全局变量
class Subo():
def __init__(self):
self.res=[]
def get_suboer_pdf(self,url,output_dir):
# print(url)
# # 发送HTTP请求获取页面内容
response = requests.get(url)
# 如果请求失败,则抛出HTTPError异常
response.raise_for_status()
# # 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
try:
# 首先找到某一个类别,包括href和文字信息,class=word
shang_pins = soup.find_all('div', {'class': 'words'})
# 对每一个类别进行提取文字和对应的href链接
for shang_pin in shang_pins:
one_mes = [] # 存储信息
# 查找class为"ft16 tits"的div元素的文本内容
tits = shang_pin.find('div', {'class': 'ft16 tits'}).get_text(strip=True)
# 查找class为"txts ft16"的div元素的文本内容
txt = shang_pin.find('div', {'class': 'txts ft16'}).get_text(strip=True)
con=tits+txt
one_mes.append(con)
# pdf在data-href。查找所有带有data-href属性的<a>标签
file_link = shang_pin.find('a', attrs={'data-href': True})['data-href']
one_mes.append(file_link)
filename = con+".pdf"
# 将文件保存到本地
response = requests.get(file_link, stream=True)
response.raise_for_status()
with open(os.path.join(output_dir, filename), 'wb') as f:
for chunk in response.iter_content(1024):
f.write(chunk)
print(f'Downloaded: {filename}')
one_mes.append(filename)
self.res.append(one_mes)
except:
pass
因为采用了上述说明的方法,所以前期信息准备比较多,需要获取你要爬取的电器类别的网址(ctype)和页数。这里采用字典进行存储,如下形式:
if __name__=="__main__":
mapping = {
2441: {'name': '智能电炖锅', 'page': 1},
2442: {'name': '电压力锅', 'page': 12},
2443: {'name': '电饭煲', 'page': 17},
}
suboer=Subo()
out_path = './suboer'
save_folder = './suboer.xlsx'
for idx in mapping.keys():
name = mapping[idx]['name']
page = mapping[idx]['page']
print('{}-{}-{}'.format(idx, name, page))
# 不同类别分别进行存储到不同文件夹
output_dir = os.path.join(out_path, name)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for i in range(1, page+1):
# 第一页和之后的格式不一样,这是一页
if i==1:
url = 'https://www.supor.com.cn/other/manualgoodscategorysearch?ctype={}'.format(idx)
one_mes=suboer.get_suboer_pdf(url, output_dir)
print("finish page {}".format(i))
else:
url = 'https://www.supor.com.cn/other/manualgoodscategorysearch/{}.html?ctype={}'.format(i, idx)
one_mes=suboer.get_suboer_pdf(url, output_dir)
print("finish page {}".format(i))
print("--------------------{}结束-------------------------".format(name))
data=suboer.res
df = pd.DataFrame(data, columns=['电器类别', '说明书链接', '文件名称'])
df.to_excel(save_folder, index=False, sheet_name='匹配结果')
print("------------------保存完成------------------")
程序运行结果:
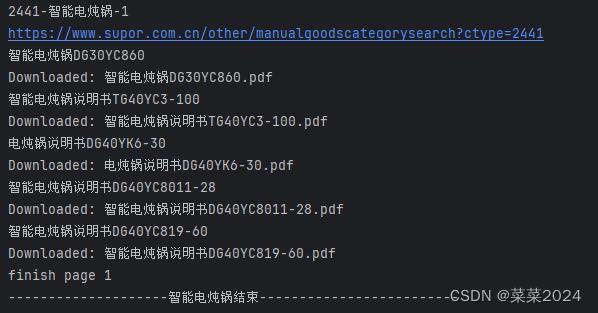
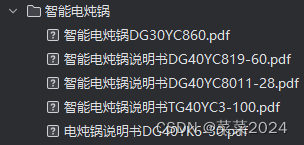

3.总结
网站比较友好,直接暴露pdf链接,不需要模拟用户点击。同时也利用网址特点进行爬取,具体情况需要具体分析。学习到了提取更多信息文字,对应存储到excel中。存储链接之后,可以直接利用链接进行下载。















 2736
2736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









