







Python+大数据技术框架和数仓基础(一)
- 分布式和集群的区别
分布式 :分布式的主要工作是分解任务,将职能拆解,多个人在一起做不同的事
集群:集群主要是将同一个业务,部署在多个服务器上 ,多个人在一起做同样的事
Hadoop介绍
Hadoop是Apache旗下的一个用Java语言实现开源软件框架,是一个存储和计算大规模数据的软件平台。
Hadoop是Apache Lucene创始人 Doug Cutting 创建的,最早起源一个Nutch项目。
Hadoop指Apache这款开源框架,它的核心组件有:
HDFS(分布式文件系统):解决海量数据存储
MAPREDUCE(分布式运算编程框架):解决海量数据计算
YARN(作业调度和集群资源管理的框架):解决资源任务调度
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
Yahoo的Hadoop应用主要包括以下几个方面:
广告系统支持
用户行为分析
Web搜索支持
反垃圾邮件系统
个性化推荐
Hadoop集群主要为电子商务网络平台提供底层的基础计算和存储服务,主要应用包括:
数据平台系统。
搜索支撑。
电子商务数据。
推荐引擎系统。
搜索排行榜。
Hadoop架构模块
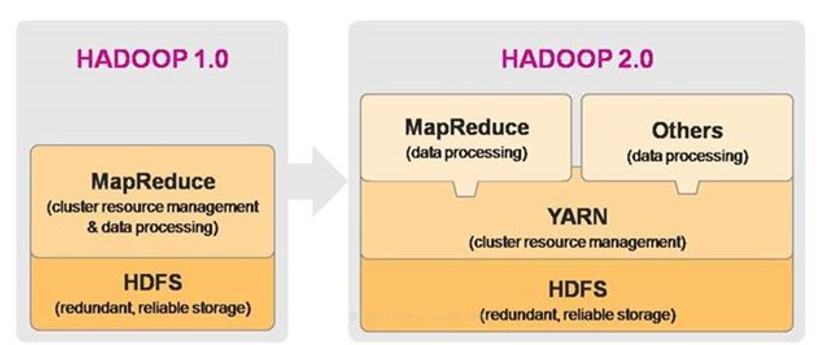
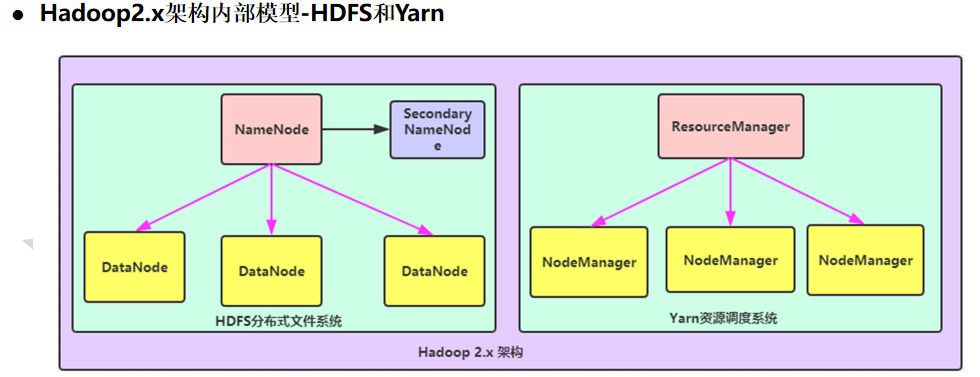
HDFS模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
SecondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配
NodeManager: 负责执行主节点分配的任务
Hadoop模块之间的关系
MapReduce计算需要的数据和产生的结果需要HDFS来进行存储
MapReduce的运行需要由Yarn集群来提供资源调度。
Hadoop集群搭建
Standalone mode(单机模式)
单机模式, 1个机器上运行HDFS的NameNode和DataNode、YARN的 ResourceManger和NodeManager,主要用于学习和调试。
Cluster mode(群集模式)
集群模式主要用于生产环境部署。会使用N台主机组成一个Hadoop集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
单机模式和集群模式都有 需要的私信我即可给链接
-
单机模式组件如下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S7ap0PJ0-1660450733587)(C:\Users\liuyikang\AppData\Roaming\Typora\typora-user-images\image-20220814120507277.png)]
-
集群组件模式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-chUVqNLG-1660450733589)(C:\Users\liuyikang\AppData\Roaming\Typora\typora-user-images\image-20220814120600914.png)]
Hadoop集群使用
一键启动
cd /export/onekey/
./start-all.sh
一键关闭
cd /export/onekey/
./stop-all.sh
web查看HDFS页面
http://192.168.88.100:50070/
HDFS介绍
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统.
分布式文件系统解决的问题就是大数据存储。它们是横跨在多台计算机上的存储系统。分布式文件系统在大数据时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力。
HDSF特点
1.HDFS文件系统可存储超大文件,时效性稍差。
2.HDFS具有硬件故障检测和自动快速恢复功能。
3.HDFS为数据存储提供很强的扩展能力。
4.HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改。
5.HDFS可在普通廉价的机器上运行。
HDFS的Shell命令
-ls 显示命令
hadoop fs -ls / #显示文件列表hadoop fs –ls -R / #递归显示文件列表
mkdir创建命令
作用 : 以<paths>中的URI作为参数,创建目录。使用-p参数可以递归创建目录
应用:
hadoop fs -mkdir /dir1
hadoop fs -mkdir -p /aaa/bbb/ccc
put上传命令
作用 :
将单个的源文件或者多个源文件srcs从本地文件系统上传到目标文件系统中。
应用:
hadoop fs -put /root/1.txt /dir1 #上传文件
hadoop fs –put /root/dir2 / #上传目录
get拷贝命令
作用:
将HDFS文件拷贝到本地文件系统。
应用:
hadoop fs -get /initial-setup-ks.cfg /op
mv移动命令
作用:
将hdfs上的文件从原路径src移动到目标路径dst,该命令不能夸文件系统
应用:
hadoop fs -mv /dir1/1.txt /dir2
rm删除命令
作用:
删除参数指定的文件和目录,参数可以有多个,删除目录需要加-r参数
如果指定-skipTrash选项,那么在回收站可用的情况下,该选项将跳过回收站而直接删除文件;
否则,在回收站可用时,在HDFS Shell 中执行此命令,会将文件暂时放到回收站中。
应用:
hadoop fs -rm /initial-setup-ks.cfg #删除文件
hadoop fs -rm -r /dir2 #删除目录
cp拷贝命令
作用:
将文件拷贝到目标路径中
应用:
hadoop fs -cp /dir1/1.txt /dir2
cat查看命令
作用:
将参数所指示的文件内容输出到控制台
应用:
hadoop fs -cat /dir1/1.txt















 1178
1178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









