






摘要 本报告就开源威胁情报信息抽取的工作进行汇报,参考了一些高引用量的文献、博客、论坛视频和项目,有助于深入了解威胁情报的全貌,尤其侧重于用于信息提取的大型语言模型。通过阅读本篇报告,可以了解到:
1.2015年以来非结构化威胁情报抽取的发展沿革和各时期的代表性工作
2.2023年使用LLM和PLM进行开源威胁情报信息抽取的最新工作
3.讨论LLM和SLM在网络安全领域落地的性能和成本比较
4.LLM现存的局限性和探索的解决方案
1.引言
网络威胁情报(CTI)的概念在2013年被Gartner提出[1],它是指收集、评估和应用的有关安全威胁、威胁行为者、漏洞利用、恶意软件、IOC的数据集,代表威胁的基于证据的知识。
开源威胁情报(OSCTI)是一种外部威胁情报,是指一些网络公开平台中分享的以文本报告形式呈现的情报。它的自动化识别和提取是网络安全领域的核心工作之一,可以帮助SOC人员更快了解有效信息。这一过程涉及将非结构化的OSCTI转换为标准化的格式,具体而言,包括从报告中抽取威胁行为者、漏洞利用、恶意软件、IOC的NER的任务;抽取不同实体之间关系的RE任务;以及从文档中提取安全事件的事件检测任务,最总将抽取出来的内容映射到OpenIOC、STIX等标准化开源威胁情报格式。
2.历来的工作
这一节,将介绍开源威胁情报信息抽取的三个时期的代表性工作,这三个时期是根据实现识别和抽取的技术方法的不同而划分的。分别是使用早期NLP、机器学习和关系模型构造技术的古早时代,预训练语言发展后的时代,以及如今身处的大模型时代。
2.1古早时代(2015-2020年)
非结构化CTI报告处理工作的历史并不长,网络上能找到的最早公开的非结构化威胁情报处理工具是Accenture Technology Labs在2015年Black Hat上展示的UTIP[2],现存资料只是一些吉光片羽,它使用了自然语言处理技术从非结构化文本源收集威胁情报映射到 STIX1.0。2017年的TTPDrill[3]建立在 UTIP 之上,通过基于增强BM25加权函数的TF-IDF方法度量候选项与本体中已知威胁行为之间的相似性,来实现将提取到的TTP映射到标准化框架,包括ATT&CK 和杀伤链模型,虽然作者说还想构建TTP图进一步分析并预测新的TTPs,但这个项目再没人维护过。转到2019年,微软防御研究部门的Soman在Black Hat上展示了他们的项目[4],演讲描述了构建网络实体提取器的过程,并且评估了序列标记任务常用的CRF和LSTM方法,他们展示了一个demo,能够根据上下文来识别技术和实体,如图1所示。另一个经典的工作是同年的Tram[5],它使用AI/ML模型将威胁报告在句子级别上映射到 MITRE ATT&CK 技术,他们的项目是MITRE Engenuity威胁防御中心2021年评选的13 个ATT&CK典型项目之一,项目是开源的且至今仍在维护。
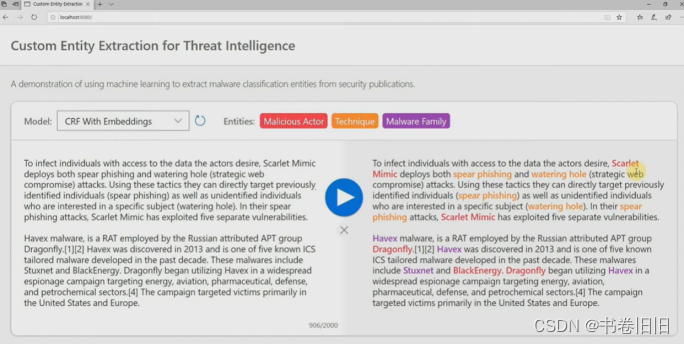
图 1 Soman在Black Hat上展示的demo
除了上述这些特别经典的项目之外,Cui等人[6]的综述,对这一时期做的工作进行了系统的调研梳理,这一时期的工作使用的方法并没有一个恰当的分类方法,通常是混合了多种技术,如图2中的部分所示。综述中指出之后的工作方向应当是融合机器学习技术与OSCTI,提升恶意软件和网络攻击的检测精度,并开发更多自动化工具来加快响应时间和提高效率。

图 2 cui等人文献中开源威胁情报识别提取相关文献分类总结对比(部分)
2.2后BERT时代(2020年-2023年)
ELMo以来的预训练语言模型发展飞快,步入预训练语言的时代,BERT于2018年被提出。“预训练+下游任务改造”的NLP第三范式,快速席卷各个垂直领域的研究,这点从国内的NLP专利布局分布就能直观看到,从2018到2020年,几乎成指数高速增长[7]。预训练方法可以通过自监督学习从大规模数据中获得与具体任务无关的预训练模型,然后用训练好的预训练模型提高下游任务的性能。
最早使用预训练语言模型来完成CTI抽取任务的代表工作是2020年Taneeya等的CASIE框架[8],它用于提取来自文本的网络安全事件信息,框架在词嵌入层加入预训练的BERT模型,相比于Domain-Word2Vec和Transfer-Word2vec性能更好,作者指出这可能是由于BERT向量更大且对上下文更敏感。此后2021年国内的Guo等人[9]利用基于内容和基于上下文的提取机制从非结构化数据中提取敏感信息的方法,使用 BERT-BiLSTM-Attention 的方法,根据上下文特征来标记文本中的敏感信息实体,可以有效地从非结构化数据中提取敏感信息。到2023年9月,作者团队又在此基础上改进[10],继而提出威胁情报提取和融合的框架,从结构化和非结构化数据中提取、关联和统一网络安全实体关系三元组,使用预训练模型BERT联合提取来生成词向量,利用BERT-BiGRU-Attention的方法提取句子特征。
这段时期还有一些使用C-GCN[11]、PCNN[12]的方法,最新的一篇2023年12月的文章,Tang等人提出了STIOCS一种结合主动学习和半监督自我训练的 IOC 提取半监督框架,通过集成CNN和RNN从CTI文本中提取局部特征和序列特征,增加CRF层利用上下文有效识别IOC实体,但从文献调研的统计结果来看,这些不使用Pre-train的方法并非2019-2023年间的主流工作。
直到现在2023年,出于对于系统可行性、效果、部署成本、数据准备难度的考虑,主流的抽取方案仍然是各种预训练语言模型的使用或者微调,表1统计了一些使用预训练语言模型较新的工作。
表1 2023年预训练语言模型相关文献
| 参考 | 时间 | 抽取内容 | 模型方法 | 数据集 | 效果 |
|---|---|---|---|---|---|
| Kashan[13] | 2024.1 | 12类CTI实体和关系联合提取 | RoBERTa-BiGRU-CRF | 852个 APT 和勒索软件报告 | 比表现最好的RoBERTa-BiLSTM-CRF基线模型F1高出 7% |
| Xiang[14] | 2023.12 | APT事件提取 | BERT-BiGRU-CRF | 130个事件信息类型的数据集,作者进行了DuEE1.0标注 | 效果优于BiGRU-CRF和BERT,F1分别高出10%和4% |
| Tanvirul[15] | 2023.11 | MITRE ATT&CK攻击模式提取 | BERT和RoBERTa和XLM-RoBERTa | 包括36 种恶意软件相关的 CTI 报告,LADDER是目前最大的有BIO标注的开源数据集 | 实体提取XLM-RoBERTa-large性能最好,F1有78.98%;RE任务BERT-large性能最好,F1有92.62%;句子级别的攻击模式提取RoBERT-large性能最好,F1有89.62% |
| Moumita[16] | 攻击技术提取 | AllenNLP SRL | BERT为语义角色标记 | 1,000 条Twitter 推文 | 是首次在现实情况下提取技术表现的研究工作,实现了 88.59% 的精确率 |
| Guo[10] | 2023.9 | STIX 对象实体和关系联合提取 | BERT-BiGRU-attention | CyberMonitor的APT报告 | 实体与关系抽取上,联合提取比传统管道模式在F1上有显著提高 |
| Marchiori[17] | 2023.9 | STIX 对象实体和关系提取 | Sentence BERT | 作者创建的开源句子数据集,包含不存在的实体和编造的名称,用于对其进行评估 | 实体提取F1有91.6%和关系提取F1有72.4%,和SOTA相当,recall也不低 |
| Zhou[18] | 实体提取 | 四种典型的基于 BERT 的 NER 模型 | 100个CTI报告、2598个威胁句子和2562个知识对象关系. | 实体提取BERT+BiLSTM+GRU+CRF模型深度更深,提取的特征更深,从而导致预测更准确;基于BERT的关系提取模型优于基于CNN、RNN、GCN |
2.3大模型时代的探索(2023年下半年)
大语言模型(LLM)是当前AI最活跃的领域,开源/闭源的模型不断更新,新的研究论文层出不穷。得益于特定领域或任务上的出色表现,LLM在最先在医学领域落地应用,随后又在法律、生物等与医学有许多相似之处的领域里应用问答和信息提取,并且发展相当迅速,短短数月已经有基准评估数据集[19]。有很多评估证明LLM信息提取能力的工作,Somin等人[20]发布在ACL上的文章评估了LLM在标准 RE 任务上的表现,评估结果表明GPT-3 的少样本提示实现了接近 SOTA 的性能。作者还指出Flan-T5 在少样本学习的能力不强,但通过 GPT-3 生成思想链的解释对其进行监督和微调,可以产生 SOTA 的结果,并将这个模型作为 RE 任务的新基线。
垂直领域定制任务的大模型,或者仅仅只是调用大模型接口的提示工程成为了当今的研究热点。在网络空间安全领域,加拿大国防研究与发展部的Madeena等人[21]回顾了近两年利用LLM和PLM进行领域下游任务的工作。他们根据任务的复杂性将其分为了两个级别。一组是静态任务,包括各种各样的 NLP 任务,如命名实体识别 (NER)、阅读理解 (RC)、关系提取 (RE)、上下文问答 (QA)、知识 QA、信息检索 (IR)、推理、因果关系、分类、文本生成、摘要、代码生成、机器翻译等;另一组是动态任务,例如执行网络渗透测试或取证调查。作者认为前者是劳动密集型的防御任务,当前面临的首要问题是,网络空间安全领域还缺乏基准评估的数据集,但LLM从 CTI 数据和报告中提取相关的、基于证据的情报是十分有潜力的。
所以一些项目给之前的工作打上了大模型“补丁”。正如上节提到的情报映射到ATT&CK 技术的那个经典项目Tram[5],他们也在今年8月更新了内容[22],使用微调过的LLM进行模型训练和预测,用于提高TTP映射的速度和准确性。在开发团队的博客中可以看到更细节的内容[23],他们尝试了 BERT 和 GPT-2 等模型以适应文本分类和网络威胁情报微调,并最终选择了Allenai的SciBERT[24],比原型系统的F1提高了7%。其实SciBERT不是新的模型,在现在看来模型也并不很大,但这项工作仍然被证明是更有效的,这个项目三年以来一直都有在更新,说不定之后下一轮更新就是真正落地大模型呢,可以观望一下。上节提到的Moumita等人[16]的工作是基于LLM的人工智能流行期间在做的,所以他们也将原型系统和GPT3做了对比,在识别带有网络威胁信息的推文的评估实验里,通过用 GPT-3.5-turbo嵌入模型 (text-embedding-ada-002) 等LLM替换词嵌入模型,可以获得更好的结果。而原型系统提取的错误分类,绝大多数又恰好是由于未能识别推文中与安全相关的短语造成的。作者团队的工作发在了10月的ISI会议,数据集和工作是开源的(但是目前看不到详细信息)。

图 3 Google Colab 上的 TRAM SciBERT 模型[23]
3.大模型还是小模型?
为什么一定得是大模型呢?直接参考以往在BERT、reBERTa等PLM的工作和现在的LLM工作去做比较是不恰当的,因为前者,即使是一些引用量很高的,又或者是很新的文章,仍然在进行句子级的工作,几乎都是在句子级别上评估NER任务[25,10,18,15],会造成评价指标的严重高估。以当前事件抽取的趋势,无论在任何领域,都是由句子级转向篇章级的。在一篇APT报告中一个事件跨越多个句子,又或者是多个句子中交叉出现了多个事件是很普遍的事情。如果只关注句子级别的工作势必会有很多局限性。少有工作关注篇章级的提取,Ning等人[26]在2021年的工作是我能找到最早的关注篇章级的工作,但在当时使用的方法是将事件提取任务形式化为没有触发词的序列标记任务,用到k 窗口大小的 BiLSTM 来捕获句子中的上下文信息,没有涉及到PLM。为了更好的说明这些问题,我试图找了一些比较新的篇章级别的工作,在网络安全领域能够客观评价的文献。
3.1性能的讨论
就连垂直领域的工业界[27–29]都对大模型趋之若鹜是很反直觉的,特定领域的小模型总是比通用的大模型更容易构建,定制任务的大模型是一件成本很高的事情呀。“特定领域的小模型总是比通用的大模型更好?”是一个很多人关注的问题。众所周知在机器学习领域有一个十分有名的“没有免费午餐”原理[30],这个原理原本是说,不存在一个算法在所有问题上的表现都优于其他算法,在脱离实际意义情况下空泛地谈论哪种模型更好是毫无意义的。这个理论貌似给了这个问题一种解,那就是存在一个小模型,在特定领域给定场景下比力大飞砖的大模型性能更好[31]。
Reza等人[32]的研究正在回答“特定领域的小模型总是比通用的大模型更好?”这个问题,似乎给这个问题肯定的回答。他们探索了如何利用大型语言模型(LLM)来提取篇章级别的网络攻击描述TTP,并将其映射到 ATT&CK 战术。他们的研究涉及4种模型,第一种是直接使用大模型接口然后提示工程(GPT-3.5 和 Bard),第二种是小模型微调 (BERT和SecureBERT)。在大模型之间的比较中,GPT-3.5优于Bard,在所有ATT&CK描述中达到了67%的F1值;而在小模型的5折交叉的验证比较中SecureBERT-SFT优于BERT。最后作者又单独比较了SecureBERT-SFT和GPT- 3.5的对所有ATT&CK描述的总体性能,微调过的SecureBERT完胜,而且不仅仅是对于ATT&CK描述而言,作者还讨论了映射到CAPEC描述的情况,结果依旧。作者给出的解释是,造成这种差异的原因是SecureBERT-SFT更精确但不灵活,而GPT-3.5 则倾向于在描述中产生更多的重叠,广泛但不精确,这是由于TTP固有的模糊性造成的,当使用GPT-3.5 时,TTP 描述固有的歧义和重叠会加剧。如图4所示。然而文章还指出当技术与结果之间有隐含联系的情况下,SecureBERT-SFT 和 GPT-3.5 都不能解释描述,还需要一个更强大、更专业的网络安全LLM来更好地理解描述中的模糊性。除了对大小模型本身的探究之外,作者还表示,在过去ATT&CK添加了许多技术、子技术和过程,每个映射通常又包含多种策略,这就导致了描述之间的重叠和模糊,这个问题不仅仅是建设一个更全面的LLM需要面临的,对于人类安全分析师亦然,所以作者期望在不久的将来下一版本的ATT&CK框架不要这么过于复杂和模糊。(好的,作者的工作在2023年6月,2023年11月ATT&CK更新了v14,目前有很多解读,但我还没有找到从这个角度去解释ATT&CK框架v14的清晰度的。)Liu等人[33]使用GPT进行CWE和ATT&CK技术映射,结果也表明漏洞映射到CWE效果较好,而映射到ATT&CK技术效果较差。(所以这到底是LLM的局限性还是ATT&CK的局限性呢?)
LLM能够执行零样本任务是其能够成为生成式人工智能的工具很重要的优势,如果是作为真实可用CTI抽取工具,必须能够抽取出不断更新的威胁攻击者、恶意软件等。Wang等人[34]重点探讨了BERT 系列在零样本学习中的潜力,作者认为是较小的预训练数据量阻碍了现有BERT家族的零样本学习能力。为此作者提出自生成提示和多空提示的策略策略来提高零样本性能和鲁棒性,将经过调整的BERT家族与大模型的比较,在广泛数据集种做了评估,得出了355M BERT 系列模型可以实现比 137B LaMDA-PT 和 175B GPT-3 更好的性能。然而Souvick等人[34]的研究称,虽然 GPT-3 在零样本问答任务上稍微落后于当前最先进的微调模型,但GPT-3 Text-DaVinci-003 模型在软件工程领域中 NER 任务实现了 98.85% 的 F1-Score 显着性能。

图 4 ATT&CK描述的两两策略重叠
3.2成本的讨论
上节有提到,如今应用大模型就是两种方法,一种是垂直领域定制任务的大模型,这种模型一般都不太大,小于10B,可能会涉及到构建知识图谱等技术加成;另一种就是使用商业大模型的api在做提示工程,这种方法用到的模型一般都大于10B。出于成本的考虑,无论是当前发布的研究[35],还是集成到已有框架的工作[36,37],几乎都是都没有微调而是采用后者的方法。ChatGPT问世不久,2月份就有卡巴斯基事件响应团队的研究员用API 进行了IoC 检测的实验[38],经过step by step的提示工程后(这将在之后被成为AIagent),结果显示ChatGPT 成功识别可疑服务安装,可以检测到混淆技术,在当时这还不是一项经济的工作,但时隔近一年现在调用API的费用已经远远小于当时了。
而使用微调的方法,小模型的代表工作是2022年的SecureBERT[39],它的基模型是RoBERTa,使用定制分词器策略和权重调整来进行微调,训练数据集的来源是在线安全文本,它能捕获网络安全文本中的上下文关系和语义,评估研究表明优于SciBERT。他们在8 个 Tesla V100 GPU 上以 Batch_size = 18(V100 GPU 最大的mini-batch大小)运行 250,000 个训练步骤 100 小时,针对掩码语言建模 (MLM)进行了动态屏蔽训练。CyBERT[40]也是通过这种MLM微调基本 BERT 模型,以识别专门的网络安全实体。而对于大模型,常用的微调方法现有的工作似乎都是在做Lora模型上的微调,在一个已经预训练好的模型基础上,使用特定任务的数据进行进一步的调整[41],这是一种简单有效的方案来达成轻量微调的目的,但成本依旧远超微调小模型。
此外还有一些研究使用小模型+大模型数据增强的方法,Markus等人[42]结合三种不同的低数据机制技术:迁移学习、数据增强和少量学习。使用 Twitter 作为数据源收集广泛的漏洞信息,包括50,000 条推文,创建 CTI 分类器,基模型是BERT,采用多层级微调的方式,并且使用基于 GPT-3 文本生成的数据增强策略。
4.LLM的局限性和当下的一些探索
NEC实验室的工作提出了ACTion框架,使用LLM(gpt-3.5-turbo api)进行在野非结构化网络威胁情报的自动分析,包括完整的抽取和映射到STIX。研究[43]宣称采用类似于AI-agent的提示工程解决了生成式大模型的两个主要问题:幻觉和短上下文窗口,虽然在某种程度上可以解决幻觉问题,还需要大量人工审查。AI Agent是大模型时代重要落地的方向,而对于幻觉问题,有很多结合知识图谱的工作。
4.1AI-agent
检测和响应能力的自动化是离不开AI Agents架构的,文章[44]揭示了相对于模仿和强化学习方法,AI Agents在LLM任务上的潜力。
在AI Agents概念流行的时期,langchain作为一个AI应用开发的主流框架,贡献了很多真实可用的项目,比如langchain-Chatchat[45],可以通过外挂知识库,匹配出的文本作为上下文和问题一起添加到prompt,提升LLM进行QA任务的准确性,减少幻觉。简单的使用该框架进行标记和提取效果也不错[46]。
11月OpenAI发布会上的Gpts给出了一种在日常网络安全实践中利用LLM更便捷的方法[47],这种方法在恶意软件检测、网络钓鱼预防、日志分析等方面,相比于传统方法的有效性都有所提高。SOCRadar的博客[48]探讨人工智能如何以自定义Gpts为主导,应用于网络安全领域,积极应对安全威胁,进行漏洞管理。
4.2知识图谱
大模型的幻觉问题是导致它无法真正在垂直领域落地的一个最重要的原因。在更广阔的整个NLP的视野,用知识图谱的技术来解决这一问题似乎正在发展成一个新的方向。
起初是今年5月Pan等人[49]的研究,给出了LLMs+KGs的三个框架:KG增强的LLMs利用KGs增强LLMs的知识学习、推理和解释性;LLM增强的KGs利用LLMs提升KGs在embedding、补全、构建、问答等tasks的表现;LLM与KG协同,将LLMs和KGs整合为统一框架,实现知识表达和推理的相互增强。而后在11月Garima等人[50]系统地对KG增强LLM的框架方法进行调研,旨在回答“KG能帮助减少LLM幻觉吗”的问题,但截至作者的调研,还都是应用在一些预训练语言模型,structGPT是唯一开源可用的,但是也8个月没有更新维护了,它采用了三种结构化数据源:知识图谱、数据表和结构化数据库。利用结构化查询提取信息,并将其串联成长句子,然后输入给LLM以提供最相关的候选关系。传统的检索增强+有监督微调存在一定局限性,为了避免“误用”到对结果无意义的知识,提升生成回答的质量,浙江大学的等人提出了一个LLM的知识偏好对齐框架KnowPAT,如图5所示。基于输入的问题从知识图谱中检索出相关无监督的三元组,包装成prompt并输入模型,随后再进行知识偏好集的构建还有模型的微调和对齐。这里还有一个仓库在更新LLMs+KGs前沿文献库,也是浙江大学陈华钧老师的团队在更新维护。[51]

图 5 KnowPAT框架
5.结语
本篇报告总结了开源威胁情报信息抽取在不同时期的代表性工作,并且系统地探讨了在网络安全领域应用大型语言模型(LLM)的优势、性能、成本以及局限性等方面的问题。特别对大型模型和小型模型的选择进行了性能和成本的讨论,涉及到一些高引用量的文献、博客和项目。此外,还就LLM的局限性进行了深入研究,提出了使用AI Agent架构以及知识图谱等方法来解决现存的问题是未来的发展方向。
参考文献
[1] Definition: Threat Intelligence[EB/OL]. [2023-12-13]. https://www.gartner.com/en/documents/2487216.
[2] us-15-Hovor-UTIP-Unstructured-Threat-Intelligence-Processing.pdf[Z/OL]. [2023-12-18]. https://www.blackhat.com/docs/us-15/materials/us-15-Hovor-UTIP-Unstructured-Threat-Intelligence-Processing.pdf.
[3] TTPDrill | Proceedings of the 33rd Annual Computer Security Applications Conference[EB/OL]. [2023-12-19]. https://dl.acm.org/doi/10.1145/3134600.3134646.
[4] BLACK HAT. Death to the IOC: What’s Next in Threat Intelligence[Z/OL]. (2020-01-15)[2023-12-18]. https://www.youtube.com/watch?v=MJHSUsS9K7s.
[5] MITRE ATT&CKcon 2.0: ATT&CK Updates – TRAM - YouTube[EB/OL]. [2023-12-19]. https://www.youtube.com/watch?v=jVkMd9mAE-U.
[6] 崔琳, 杨黎斌, 何清林, 等. 基于开源信息平台的威胁情报挖掘综述[J/OL]. 信息安全学报, 20220228, 7(1): 1-26. DOI:10.19363/J.cnki.cn10-1380/tn.2022.01.01.
[7] 人工智能产业中不可忽略的技术领域之NLP - 知乎[EB/OL]. [2023-12-19]. https://zhuanlan.zhihu.com/p/417319914.
[8] SATYAPANICH T, FERRARO F, FININ T. CASIE: Extracting Cybersecurity Event Information from Text[J/OL]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(05): 8749-8757. DOI:10.1609/aaai.v34i05.6401.
[9] GUO Y. Exsense: Extract sensitive information from unstructured data[J]. 2021.
[10] GUO Y, LIU Z, HUANG C, 等. A framework for threat intelligence extraction and fusion[J/OL]. Computers & Security, 2023, 132: 103371. DOI:10.1016/j.cose.2023.103371.
[11] WANG X, XIONG M, LUO Y, 等. Joint Learning for Document-Level Threat Intelligence Relation Extraction and Coreference Resolution Based on GCN[C/OL]//2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom). 2020: 584-591[2023-12-18]. https://ieeexplore.ieee.org/abstract/document/9343057. DOI:10.1109/TrustCom50675.2020.00083.
[12] Joint Entity Linking and Relation Extraction with Neural Networks for Knowledge Base Population | IEEE Conference Publication | IEEE Xplore[EB/OL]. [2023-12-18]. https://ieeexplore.ieee.org/abstract/document/9207021.
[13] AHMED K, KHURSHID S K, HINA S. CyberEntRel: Joint extraction of cyber entities and relations using deep learning[J/OL]. Computers & Security, 2024, 136: 103579. DOI:10.1016/j.cose.2023.103579.
[14] Electronics | Free Full-Text | An APT Event Extraction Method Based on BERT-BiGRU-CRF for APT Attack Detection[EB/OL]. [2023-12-19]. https://www.mdpi.com/2079-9292/12/15/3349.
[15] Looking Beyond IoCs: Automatically Extracting Attack Patterns from External CTI | Proceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses[EB/OL]. [2023-12-19]. https://dl.acm.org/doi/10.1145/3607199.3607208.
[16] PURBA M D, CHU B. Extracting Actionable Cyber Threat Intelligence from Twitter Stream[C/OL]//2023 IEEE International Conference on Intelligence and Security Informatics (ISI). 2023: 1-6[2023-12-20]. https://ieeexplore.ieee.org/document/10297205. DOI:10.1109/ISI58743.2023.10297205.
[17] STIXnet: A Novel and Modular Solution for Extracting All STIX Objects in CTI Reports | Proceedings of the 18th International Conference on Availability, Reliability and Security[EB/OL]. [2023-12-19]. https://dl.acm.org/doi/abs/10.1145/3600160.3600182.
[18] CDTier: A Chinese Dataset of Threat Intelligence Entity Relationships | IEEE Journals & Magazine | IEEE Xplore[EB/OL]. [2023-12-19]. https://ieeexplore.ieee.org/document/10029930.
[19] [2110.00976] LexGLUE: A Benchmark Dataset for Legal Language Understanding in English[EB/OL]. [2023-12-20]. https://arxiv.org/abs/2110.00976.
[20] WADHWA S, AMIR S, WALLACE B. Revisiting Relation Extraction in the era of Large Language Models[C/OL]//ROGERS A, BOYD-GRABER J, OKAZAKI N. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Toronto, Canada: Association for Computational Linguistics, 2023: 15566-15589[2023-12-21]. https://aclanthology.org/2023.acl-long.868. DOI:10.18653/v1/2023.acl-long.868.
[21] SULTANA M, TAYLOR A, LI L, 等. Towards Evaluation and Understanding of Large Language Models for Cyber Operation Automation[C/OL]//2023 IEEE Conference on Communications and Network Security (CNS). 2023: 1-6[2023-12-21]. https://ieeexplore.ieee.org/document/10288677. DOI:10.1109/CNS59707.2023.10288677.
[22] THREAT REPORT ATT&CK MAPPER (TRAM)[EB/OL]//MITRE Engenuity. [2023-12-20]. https://mitre-engenuity.org/cybersecurity/center-for-threat-informed-defense/our-work/threat-report-attck-mapper-tram/.
[23] Our TRAM Large Language Model Automates TTP Identification in CTI Reports | by Jon Baker | MITRE-Engenuity | Medium[EB/OL]. [2023-12-20]. https://medium.com/mitre-engenuity/our-tram-large-language-model-automates-ttp-identification-in-cti-reports-5bc0a30d4567.
[24] allenai/scibert: A BERT model for scientific text.[EB/OL]//GitHub. [2023-12-20]. https://github.com/allenai/scibert.
[25] PERRINA F, MARCHIORI F, CONTI M, 等. AGIR: Automating Cyber Threat Intelligence Reporting with Natural Language Generation[M/OL]. arXiv, 2023[2023-11-05]. http://arxiv.org/abs/2310.02655.
[26] A Framework for Document-level Cybersecurity Event Extraction from Open Source Data | IEEE Conference Publication | IEEE Xplore[EB/OL]. [2023-12-20]. https://ieeexplore.ieee.org/document/9437745.
[27] 市场部. 【创新前沿】金睛云华推出安心「CyberGPT」一体机,赋能网络安全行业大模型落地应用[EB/OL]//微信公众平台. [2023-12-21]. http://mp.weixin.qq.com/s?__biz=MzkyODE5NDE4Ng==&mid=2247504381&idx=1&sn=d6805063c8fbf538ed369c67070b2dc1&chksm=c21e1a18f569930e00379bc7cb2253158f65a596707bf704b5bde41f87df4caa37bdf3c14ecf#rd.
[28] 360数字安全. ISC 2023潘剑锋:360正式发布行业首个可交付安全大模型应用[EB/OL]//微信公众平台. [2023-12-21]. http://mp.weixin.qq.com/s?__biz=MzA4MTg0MDQ4Nw==&mid=2247563287&idx=2&sn=791aa1be963b69e3b1fd62980080d302&chksm=9f8d681fa8fae10978073cfc74ea8a62c4c35baac8613b7a82d6f85b5c212ebe5344be1db2aa#rd.
[29] 深信服安全GPT-助力安全领先一步[EB/OL]. [2023-12-21]. https://www.securitygpt.com.cn/.
[30] BROWNLEE J. No Free Lunch Theorem for Machine Learning[EB/OL]//MachineLearningMastery.com. (2021-02-16)[2023-12-21]. https://machinelearningmastery.com/no-free-lunch-theorem-for-machine-learning/.
[31] 大模型时代,如何理解“没有免费的午餐”定理(No Free Lunch Theorem)? - 知乎[EB/OL]. [2023-12-21]. https://www.zhihu.com/question/633117635/answer/3315364559.
[32] FAYYAZI R, YANG S J. On the Uses of Large Language Models to Interpret Ambiguous Cyberattack Descriptions[M/OL]. arXiv, 2023[2023-10-27]. http://arxiv.org/abs/2306.14062.
[33] LIU X, TAN Y, XIAO Z, 等. Not The End of Story: An Evaluation of ChatGPT-Driven Vulnerability Description Mappings[J].
[34] DAS S, DEB N, CORTESI A, 等. Zero-shot Learning for Named Entity Recognition in Software Specification Documents[C/OL]//2023 IEEE 31st International Requirements Engineering Conference (RE). 2023: 100-110[2023-12-23]. https://ieeexplore.ieee.org/document/10260860. DOI:10.1109/RE57278.2023.00019.
[35] deadbits/trs: 🔭 Threat report analysis via LLM and Vector DB[EB/OL]//GitHub. [2023-12-22]. https://github.com/deadbits/trs.
[36] Harnessing the Power of AI in SOAR[EB/OL]. [2023-12-22]. https://www.trellix.com/about/newsroom/stories/xdr/harnessing-the-power-of-ai-in-soar/.
[37] 狩猎 | 宣布 IOC-Hunter[EB/OL]. [2023-12-22]. https://hunt.io/blog/announcing-hunt-ioc-hunter.
[38] IoC detection experiments with ChatGPT[EB/OL]. (2023-02-15)[2023-12-23]. https://securelist.com/ioc-detection-experiments-with-chatgpt/108756/.
[39] AGHAEI E, NIU X, SHADID W, 等. SecureBERT: A Domain-Specific Language Model for Cybersecurity[M/OL]. arXiv, 2022[2023-12-23]. http://arxiv.org/abs/2204.02685. DOI:10.48550/arXiv.2204.02685.
[40] RANADE P, PIPLAI A, JOSHI A, 等. CyBERT: Contextualized Embeddings for the Cybersecurity Domain[C/OL]//2021 IEEE International Conference on Big Data (Big Data). 2021: 3334-3342[2023-12-23]. https://ieeexplore.ieee.org/document/9671824. DOI:10.1109/BigData52589.2021.9671824.
[41] Clouditera/secgpt[CP/OL]. Clouditera, 2023[2023-12-23]. https://github.com/Clouditera/secgpt.
[42] BAYER M, FREY T, REUTER C. Multi-level fine-tuning, data augmentation, and few-shot learning for specialized cyber threat intelligence[J/OL]. Computers & Security, 2023, 134: 103430. DOI:10.1016/j.cose.2023.103430.
[43] SIRACUSANO G, SANVITO D, GONZALEZ R, 等. Time for aCTIon: Automated Analysis of Cyber Threat Intelligence in the Wild[M/OL]. arXiv, 2023[2023-11-05]. http://arxiv.org/abs/2307.10214.
[44] YAO S, ZHAO J, YU D, 等. ReAct: Synergizing Reasoning and Acting in Language Models[M/OL]. arXiv, 2023[2023-12-23]. http://arxiv.org/abs/2210.03629. DOI:10.48550/arXiv.2210.03629.
[45] chatchat-space/Langchain-Chachat: Langchain-Chachat(原Langchain-ChatGLM)基于Langchain 与 ChatGLM 等语言模型的本地知识库问答 | Langchain-Chatatch(以前称为 langchain-ChatGLM),基于本地知识的 LLM(如 ChatGLM),带有 langchain 的 QA 应用程序[EB/OL]. [2023-12-23]. https://github.com/chatchat-space/Langchain-Chatchat.
[46] SAM WITTEVEEN. Tagging and Extraction - Classification using OpenAI Functions[Z/OL]. (2023-06-20)[2023-12-23]. https://www.youtube.com/watch?v=a8hMgIcUEnE.
[47] ROCCIA T. fr0gger/Awesome-GPT-Agents[CP/OL]. (2023-12-21)[2023-12-21]. https://github.com/fr0gger/Awesome-GPT-Agents.
[48] ERNALBANT Y. Custom GPTs for Vulnerability Management: Harness the Power of AI in Cyber Defense[EB/OL]//SOCRadar® Cyber Intelligence Inc. (2023-12-08)[2023-12-21]. https://socradar.io/custom-gpts-for-vulnerability-management-harness-the-power-of-ai-in-cyber-defense/.
[49] PAN S, LUO L, WANG Y, 等. Unifying Large Language Models and Knowledge Graphs: A Roadmap[M/OL]. arXiv, 2023[2023-11-05]. http://arxiv.org/abs/2306.08302. DOI:10.48550/arXiv.2306.08302.
[50] AGRAWAL G, KUMARAGE T, ALGHAMI Z, 等. Can Knowledge Graphs Reduce Hallucinations in LLMs? : A Survey[M/OL]. arXiv, 2023[2023-12-22]. http://arxiv.org/abs/2311.07914. DOI:10.48550/arXiv.2311.07914.
[51] zjukg/KG-LLM-Papers: [Paper List] Papers integrating knowledge graphs (KGs) and large language models (LLMs)[EB/OL]. [2023-12-21]. https://github.com/zjukg/KG-LLM-Papers.















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









