






Oracle 知识
select * from hr.employees e;-- hr.employees,hr.departments -- count(*) 总数
select * from hr.departments d;
--练习-计算每个员工的日薪 hr.employees的salary字段表示月薪的意思
select round(e.salary / 30) as "员工日薪" from hr.employees e order by salary desc;
--使用 字符串连接符 || (这就把姓和名连接在一起,并且显示在同一个字段中)
select first_name || last_name as "姓名" from hr.employees e;
--在姓和名之间加上空格 ''
select first_name || ' ' || last_name as "姓名" from hr.employees;
--消除重复的行 distinct 总数107 消除重复的job_id号
select distinct(job_id) from hr.employees;--19条数据
--条件限定 in
select * from hr.employees e where e.salary in(3000,6000);
--名字里倒数第三个字母是u的员工
--%表示任意匹配,有或者没有都可以
--_表示有,并且只有一个
select * from hr.employees where first_name like '%u__';
--常用的逻辑判断 与 或 非 and or not
select salary from hr.employees where salary between 3000 and 5000;
select salary from hr.employees where salary>= 3000 and salary<=5000;
--练习
--1查询所有员工的姓名(last_name+' '+first_name),工资,年终奖金(工资的百分之八十 乘以 commission_pct 在加500)别名(年终奖)。
select last_name|| ' ' || first_name,
salary,
((salary * 0.8) * commission_pct + 500) as "年终奖"
from hr.employees;
--2查询所有有人员的部门编号,并且去掉重复行。
select distinct(department_id) as "部门编号"
from hr.employees e;
--3查询员工的姓名,工资,岗位(JOB_ID),要求工资为2000~3000并且JOB_ID以‘ERK’结束
select
first_name || last_name,
salary,
JOB_ID
from hr.employees e
where salary between 2000 and 3000 and JOB_ID like '%ERK';
--4查询所有有人员的岗位编号,要求岗位(JOB_ID)中包含‘L’同时岗位(JOB_ID)名称以‘N’或‘K’结束,去掉重复行。
select distinct(job_id) as "job_id"
from hr.employees e
where job_id like '%L%' and job_id like '%N' or job_id like '%K';
--1313212
select *
from hr.employees e left join hr.departments d
on e.department_id = d.department_id;
select * from hr.employees e;-- hr.employees,hr.departments -- count(*) 总数
select * from hr.departments d;
--1.查询部门编号大于等于50小于等于90的部门中 工资小于5000的员工的编号、部门编号和工资
select e.employee_id,
e.department_id,
e.salary
from hr.employees e
where e.department_id >= 50 and e.department_id <= 90
and salary < 5000;
--2.显示员工姓名加起来一共15个字符的员工
select (first_name || '' || last_name) as "员工姓名"
from hr.employees
where length(first_name|| '' ||last_name)=15;
--3.显示不带有“ R ”的员工的姓名
select (e.first_name || '' || e.last_name) as "员工姓名"
from hr.employees e
where (e.first_name || '' || e.last_name) not like '%R%';
--4.查询所有员工的部门的平均工资,要求显示部门编号,部门名,部门所在地(需要多表关联查询: employees, department, location)
--常见查询 数据不全
select count(*) as "总数",
avg(e.salary) as "平均工资",
d.department_id,
d.department_name,
l.street_address
from hr.employees e,hr.departments d,hr.locations l
where e.department_id = d.department_id and l.location_id = d.location_id
group by d.department_id,d.department_name,l.street_address;
--用关联查询 数据更全
select avg(e.salary), e.department_id,d.department_name,l.street_address from hr.employees e
left join hr.departments d
on e.department_id = d.department_id
left join hr.locations l
on d.location_id = l.location_id
group by e.department_id ,d.department_name,l.street_address;
--子查询
??????
1.知识点:
1.1 Oracle中的sign()函数用法
sign是一种计算机函数,算法为取数字n的符号,大于0返回1,小于0返回-1,等于0返回0
1.2 Exists()函数
Exists操作符可以帮助我们加快查询速度,提升数据库查询性能,可以突出它的使用场景和适合程度。以下我们就一起探讨Oracle中Exists用法有哪些:
1、Exists运算符:exists运算符是一种逻辑运算符,用于判断子查询是否有返回行,如果有返回结果,则父查询也可以有结果检索出来
1.3 Oracle 数据插入 时 不提交 事务 则数据不能保存
commit
- 自建表 需要加上前缀 ct_xxxxxxxxxxxxxxxxxxx
问题2:配置提交按钮时 primaty 和 secondary 事 需要配置submit action
1.4 sql查询前十条数据
SELECT count(*)总数 FROM container WHERE rownum <= 10;
1.5 Oracle 中 LISTAGG 函数的介绍以及使用
SELECT REFERENCEID,listagg(decode(TYPE, 1, '呼叫', 2, '处理', 3, '转办', 4, '完成', 5, '取消', 6, '关闭', 7,'评估'), '-') types
from CT_EVENT_HANDLING_CLOSETYPE WHERE ACTIVE = '1' group by REFERENCEID;
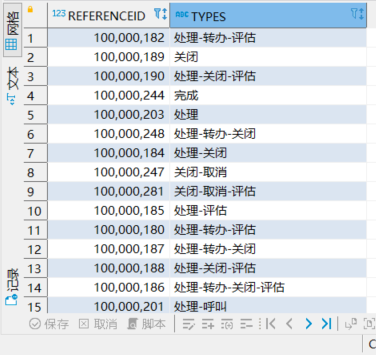
查询外面在套一个left join
left join (select listagg(decode(TYPE, 1, '呼叫', 2, '处理', 3, '转办', 4, '完成', 5, '取消', 6, '关闭', 7,
'评估'), '/') types,
REFERENCEID
from CT_EVENT_HANDLING_CLOSETYPE
where ACTIVE = 1
group by REFERENCEID) CEHC on CEHG.ID = CEHC.REFERENCEID
其主要功能类似于 wmsys.wm_concat 函数, 即将数据分组后, 把指定列的数据再通过指定符号合并
listagg 函数有两个参数:
1、 要合并的列名
2、 自定义连接符号
☆LISTAGG 函数既是分析函数,也是聚合函数
所以,它有两种用法:
1、分析函数,如: row_number()、rank()、dense_rank() 等,用法相似
listagg(合并字段, 连接符) within group(order by 合并的字段的排序) over(partition by 分组字段)
2、聚合函数,如:sum()、count()、avg()等,用法相似
listagg(合并字段, 连接符) within group(order by 合并字段排序) --后面跟 group by 语句
一部分聚合函数其实也可以写成分析函数的形式。
分析函数和聚合函数本质上都是对数据进行分组,二者最大的不同便是:
对数据进行分组分组之后,
聚合函数只会每组返回一条数据,
而分析函数会针对每条记录都返回,
一部分分析函数还会对同一组中的数据进行一些处理(比如:rank() 函数对每组中的数据进行编号);
还有一部分分析函数不会对同一组中的数据进行处理(比如:sum()、listagg()),这种情况下,分析函数返回的数据会有重复的,distinct 处理之后的结果与对应的聚合函数返回的结果一致。
1.6 START WITH
条件1表示我数据的切入点,也就是我第一条数据从哪里开始.
--自顶向下 以BRH_ID = '0003'这个节点为根节点,向下查询
SELECT * FROM IM_BRANCH
START WITH BRH_ID = '0003'
CONNECT BY PRIOR BRH_ID = BRH_PARENTID
--自底向上 以BRH_ID = '0003'这个节点为叶节点,向上查询
SELECT * FROM IM_BRANCH
START WITH BRH_ID = '0003'
CONNECT BY BRH_ID = PRIOR BRH_PARENTID
START WITH... CONNECT BY PRIOR...常见的用法,是用来遍历含有父子关系的表结构中。比如省市关系,一个省
下面包含多个城市,如果城市基本信息表中,包含有属于哪个省级的字段,那么如果要遍历所有的城市,我们就可以
使用START WITH... CONNECT BY PRIOR...
1.7 Oracle数据库rownum和row_number的不同点
在Oracle数据库中,我们常常会用到rownum和row_number这两个关键字来操作行数据。它们虽然都可以用来对查询结果的行数进行限制,但它们有着不同的用法和功效。本文将详细讲解这两个关键字的区别,并结合实例进行说明。
rownum
rownum是Oracle数据库中内置的一个伪列,它在查询结果返回之后才会计算。rownum可以用来计算查询结果集中每一行的行号,但不能在where字句中使用和修改,因为它是在计算结果后才产生的。
我们希望查询employee表中前5条年龄最小的员工信息,可以使用如下查询语句:
select * from (
select * from employee order by age
) where rownum <= 5;
我们继续使用上面的employee表,假设现在有一个需求:查询年龄在25岁以上的前5个员工信息。如果直接使用rownum限制行数,会得到以下结果:
select * from employee where age >= 25 and rownum <= 5;
1.8 row_number
row_number是Oracle数据库中窗口函数中的一种,它可以用来计算查询结果集中每一行的行号。与rownum不同的是,row_number是在查询结果返回之前产生的,因此可以进行更为灵活的操作。一般情况下,row_number的使用如下:
select row_number() over (order by column_name) as row_num, *
from table;
此语句的作用是为查询结果集中的每一行添加一个序列号row_num,使其按指定列名进行排序
1.9 SQL显示-涉及数据拼接显示的(知识点)

1-10 字父表之间的关系(知识点)
--EVENTTYPEITEM,RESPONSIBILITYGROUP
--子表
SELECT * FROM CT_EXCEPTION_OBJECT_EVENTTYPE CEOE2;
--父表
SELECT * FROM CT_HANDLING_EMPLOYEE_GROUP HEG;
--根据子节点查询父节点
--CEOE2.EVENTTYPEITEM,CEOE2.RESPONSIBILITYGROUP,HEG.DEPTNO parent_DEPTNO,HEG.DEPARTMENTNAME parent_DEPTNO
select DISTINCT HEG.DEPTNO parent_DEPTNO
from CT_EXCEPTION_OBJECT_EVENTTYPE CEOE2, CT_HANDLING_EMPLOYEE_GROUP HEG
where CEOE2.EVENTTYPEITEM=HEG.DEPARTMENTNAME --and CEOE2.EVENTTYPEITEM='100010222';
--根据父节点查询虽有的子节点
SELECT DISTINCT * FROM CT_HANDLING_EMPLOYEE_GROUP HEG start with id = '100010436' Connect By Prior id = pid;
--根据id查询所有的子数据
select * from CT_HANDLING_EMPLOYEE_GROUP HEG
start with HEG.DEPTNO = 'PM2.1'
connect by prior id = pid -- prior 右边是子级id,就往子级的方向查询
ORDER BY DEPTNO;
------------------------------------- 重要 ----------------------------------------------
SELECT * FROM CT_HANDLING_EMPLOYEE_GROUP WHERE PID in(
SELECT PID FROM CT_HANDLING_EMPLOYEE_GROUP WHERE DEPTNO = '431PRD11010103-1'
)
1.11 having条件查询
-
当使用group by进行分组时,想要使用条件查询,必须使用having,而不是where
group by …having…
#查询平均工资小于8000的部门
#emp为员工表,deptno为部门编号字段,sal为工资字段
select deptno, AVG(sal) from emp
group by deptno #按部门分组
having AVG(sal)<8000 #查询条件,类似where,但是group by中只能使用having
1.12 SQL别名 ??
1.13 SQL条件分支 Case When
case when 支持同时指定多个分支,示例语法如下:
CASE WHEN (条件1) THEN 结果1
WHEN (条件2) THEN 结果2
...
ELSE 其他结果 END
----------------------------------------------------------------------------------------
SELECT
name,
CASE WHEN (name = '鸡哥') THEN '会' ELSE '不会' END AS can_rap
FROM
student;
eg:
-- 请在此处输入 SQL
select
name as '学生姓名', --一列字段名
case when (age >= 60) then '老同学'
when (age >= 20 and age < 60) then '年轻'
else '小同学'
end as age_level --一列条件显示的字段名
from
student
order by
name asc;
1.14 exists子查询语句
使用 exists 子查询的方式,SQL 代码如下:
-- 主查询
SELECT name, total_amount
FROM customers
WHERE EXISTS (
-- 子查询
SELECT 1
FROM orders
WHERE orders.customer_id = customers.customer_id
);
--它可以嵌套在主查询中,帮助我们进行更复杂的条件过滤和数据检索。
其中,子查询中的一种特殊类型是 "exists" 子查询,用于检查主查询的结果集是否存在满足条件的记录,它返回布尔值(True 或 False),而不返回实际的数据。
和 exists 相对的是 not exists,用于查找不满足存在条件的记录。
1.15 oracle中in的用法

1.16 UNION 和UNION ALL
在 SQL 中,组合查询是一种将多个 SELECT 查询结果合并在一起的查询操作。
包括两种常见的组合查询操作:UNION 和 UNION ALL。
UNION 操作:它用于将两个或多个查询的结果集合并, 并去除重复的行 。即如果两个查询的结果有相同的行,则只保留一行。
UNION ALL 操作:它也用于将两个或多个查询的结果集合并, 但不去除重复的行 。即如果两个查询的结果有相同的行,则全部保留。
--eg:
-- 请在此处输入 SQL
select name,age,score,class_id from student as '学生表'
union all
select name,age,score,class_id from student_new as '新学生表'
1.17 trunc 函数用法
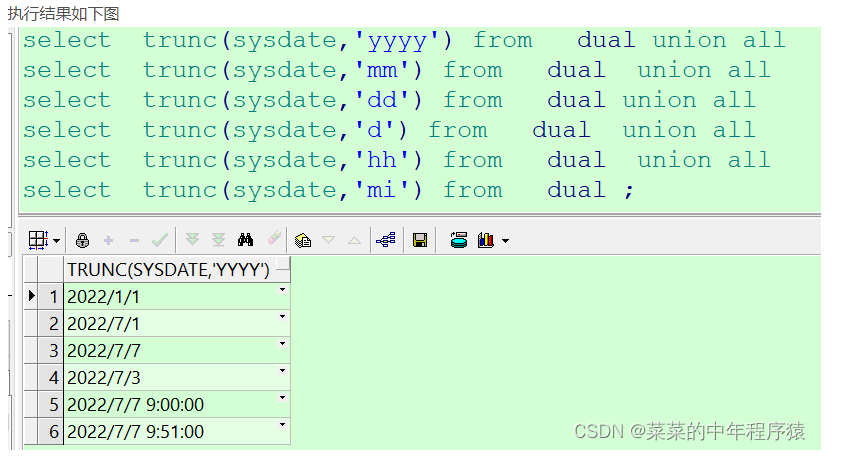
用于截取时间或者数值,返回指定的值
一、截取时间
select trunc(sysdate,'yyyy') from dual ;--返回当年第一天
select trunc(sysdate,'mm') from dual ; --返回当月第一天
select trunc(sysdate,'dd') from dual ;--返回当前年月日
select trunc(sysdate,'d') from dual ; --返回当前星期的第一天(星期日)
select trunc(sysdate,'hh') from dual ;--返回当前日期截取到小时,分秒补0
select trunc(sysdate,'mi') from dual ;--返回当前日期截取到分,秒补0
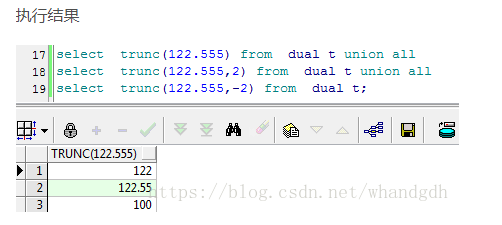
二、截取数值
语法:trunc(number,[decimals])
number:指需要截取的数字,
[decimals]:截取位数,可选参数,如果参数是负数表示从小数点左边截取。注意这里的截取都不做四舍五入。直接舍掉
select trunc(122.555) from dual t; --默认取整
select trunc(122.555,2) from dual t;
select trunc(122.555,-2) from dual t;--负数表示从小数点左边开始截取2位
2.sql优化
1.避免使用 select * ,使用精确字段查询 (条件越多 查询速度越快)
2.union all 代替 union
union 获取排重后的数据 (较慢),union all (不管重复 不重复都先查询出来)
3.小表驱动大表,也就是说用小表的数据集驱动大表的数据集
in 适用于左边大表,右边小表。
exists 适用于左边小表,右边大表。
4.批量操作
使用代码进行数据库的批量数据操作时,不要多次请求数据库,消耗性能
orderMapper.insertBatch(list):
提供一个批量插入数据的方法
5.使用limit 限制
使用limit 1,只返回该用户下单时间最小的那一条数据
在删除或者修改数据时,为了防止误操作,导致删除或修改了不相干的数据,也可以在sql语句最后加上limit
SQL查询时不必要使用count 使用limit 1 让数据库查询时遇到一条就返回,不要再继续查找还有多少条了
#### SQL写法:
SELECT 1 FROM table WHERE a = 1 AND b = 2 LIMIT 1
6.用连接查询代替子查询
根据业务复杂场景使用 keft join ,inner join
7.选择合理的字段数据类型
8.group by 分组
9.索引优化
使用explain命令,查看mysql的执行计划。
例如:
explain select * from `order` where code='002';
3.模糊查询sql
--模糊查询
--查找 PREVIOUSSEQUENCENO 以T结尾的数据
SELECT * FROM WIP_OPERATION wo WHERE PREVIOUSSEQUENCENO LIKE '%T';
--查找 PREVIOUSSEQUENCENO 以L开头的数据
SELECT * FROM WIP_OPERATION wo WHERE PREVIOUSSEQUENCENO LIKE 'L%';
--查找 PREVIOUSSEQUENCENO 包含AS的数据
SELECT * FROM WIP_OPERATION wo WHERE PREVIOUSSEQUENCENO LIKE '%AS%';
--查找 PREVIOUSSEQUENCENO 不包含FIRST的数据
SELECT * FROM WIP_OPERATION wo WHERE PREVIOUSSEQUENCENO NOT LIKE '%FIRST%';
4.行锁 表锁
二、mysql锁表的解决
#查看进程id,然后用kill id杀掉进程
show processlist;
SELECT * FROM information_schema.PROCESSLIST;
#查询正在执行的进程
SELECT * FROM information_schema.PROCESSLIST where length(info) >0 ;
#查询是否锁表
show OPEN TABLES where In_use > 0;
#查看被锁住的
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
#等待锁定
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
#杀掉锁表进程
kill 5601
————————————————
版权声明:本文为CSDN博主「小马哥ma」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_58871547/article/details/123414091
SELECT * FROM userInfo;
--锁表 行锁
原因:某行数据未提交 未commit 做update
5.Oracle建表SQL
CREATE TABLE FLXUSER.USERDETAIL(
ID NUMBER NOT NULL,
USERNAME NVARCHAR2(32),
PASSWORD NVARCHAR2(32),
------------------------------------【APRISO必须字段】
REFERENCEID NUMBER NULL,
LASTUPDATEON DATE NULL,
LASTUPDATEDBY NVARCHAR2(50) NULL,
CREATEDON DATE NULL,
CREATEDBY NVARCHAR2(50) NULL,
ACTIVE NUMBER(1) DEFAULT 1 NOT NULL,
LASTDELETEON DATE NULL,
LASTDELETEDBY NVARCHAR2(50) NULL,
LASTREACTIVATEON DATE NULL,
LASTREACTIVATEDBY NVARCHAR2(50) NULL,
ARCHIVEID NUMBER NULL,
LASTARCHIVEON DATE NULL,
LASTARCHIVEDBY NVARCHAR2(50) NULL,
LASTRESTOREON DATE NULL,
LASTRESTOREDBY NVARCHAR2(50) NULL,
ROWVERSIONSTAMP NUMBER(38) DEFAULT 1 NULL,
------------------------------------【主键】
CONSTRAINT PK_USER PRIMARY KEY(ID)
NOT DEFERRABLE
USING INDEX
TABLESPACE FLEXNET PCTFREE 10 INITRANS 2 MAXTRANS 255
STORAGE( INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT )
NOLOGGING
)
TABLESPACE FLEXNET NOCOMPRESS PCTFREE 10 INITRANS 1 MAXTRANS 255
STORAGE( INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645 BUFFER_POOL DEFAULT )
NOPARALLEL
LOGGING
NOCACHE
MONITORING
NOROWDEPENDENCIES
DISABLE ROW MOVEMENT
--LOB (OPERATIONFLOWLAYOUT) STORE AS SYS_LOB0000075507C00021$$ (TABLESPACE FLEXNET ENABLE STORAGE IN ROW CHUNK 8192 PCTVERSION 10 CACHE LOGGING)
GO
------------------------------------【删除约束】
--ALTER TABLE FLXUSER.Table_Apriso_TEST DROP CONSTRAINT FK_Table_Apriso_TEST_01
--GO
------------------------------------【创建约束】
ALTER TABLE FLXUSER.Table_Apriso_TEST
ADD ( CONSTRAINT FK_Table_Apriso_TEST_01
FOREIGN KEY(PRODUCTID)
REFERENCES FLXUSER.PRODUCT(ID)
NOT DEFERRABLE INITIALLY IMMEDIATE VALIDATE )
GO
------------------------------------【注释】
COMMENT ON TABLE FLXUSER.USERDETAIL IS '用户表.';
COMMENT ON COLUMN FLXUSER.USERDETAIL.ID IS '自增ID.';
COMMENT ON COLUMN FLXUSER.USERDETAIL.USERNAME IS '用户名.';
COMMENT ON COLUMN FLXUSER.USERDETAIL.PASSWORD IS '密码.';
GO
------------------------------------【索引】
CREATE INDEX FLXUSER.IDX_USER_Apriso_TEST_01
ON FLXUSER.USERDETAIL(ID, USERNAME)
TABLESPACE FLEXNET NOCOMPRESS PCTFREE 10 INITRANS 2 MAXTRANS 255
STORAGE( INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS UNLIMITED BUFFER_POOL DEFAULT )
VISIBLE
NOPARALLEL
LOGGING
GO
------------------------------------【赋权限】
GRANT SELECT ON FLXUSER.USERDETAIL TO APP_READER_FLXUSER
GO
GRANT SELECT, INSERT, UPDATE, DELETE ON FLXUSER.USERDETAIL TO APP_WRITER_FLXUSER
GO
------------------------------------【中间表赋权限——ESB】
--GRANT SELECT, INSERT, UPDATE, DELETE ON FLXUSER.CT_WIP_ORDER_CHANGE TO EDI
--GO
------------------------------------【删除Sequence】
DROP SEQUENCE FLXUSER.SEQ_USER
GO
--创建seq 使得ID自增 相当于MySQL中的 auto_increment
------------------------------------【创建Sequence】
CREATE SEQUENCE FLXUSER.SEQ_USERINFO
INCREMENT BY 1 START WITH 100000001
NOMAXVALUE NOMINVALUE NOCYCLE CACHE 20 NOORDER
GO
--触发器是一种用来保障参照完整性的特殊的存储过程,它维护不同表中数据间关系的有关规则
------------------------------------【触发器】
CREATE OR REPLACE TRIGGER "FLXUSER"."INS_USERINFO"
BEFORE INSERT ON "USERINFO"
FOR EACH ROW
DECLARE
i_LAST NUMBER;
BEGIN
SELECT SEQ_USERINFO.NEXTVAL INTO i_LAST FROM Dual;
PKG_IDENTITY.SET_IDENTITY(i_LAST);
:NEW.ID := i_LAST;
END;
GO
内容中有借鉴,不当之处多多见谅


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











