






embedding层作用:①降维②对低维的数据进行升维时,可能把一些其他特征给放大了,或者把笼统的特征给分开了。
Embedding其实就是一个映射,从原先所属的空间映射到新的多维空间中,也就是把原先所在空间嵌入到一个新的空间中去。
one-hot编码
优点:计算方便快捷、表达能力强。
缺点:过于稀疏时,过度占用资源。
我从哪里来,要到何处去
[
[1 0 0 0 0 0 0 0 0 0]
[0 1 0 0 0 0 0 0 0 0]
[0 0 1 0 0 0 0 0 0 0]
[0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 1 0 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 0 1 0 0 0]
[0 0 0 0 0 0 0 1 0 0]
[0 0 0 0 0 0 0 0 1 0]
[0 0 0 0 0 0 0 0 0 1]
]
面对one-hot的优缺点,Embedding层横空出世。
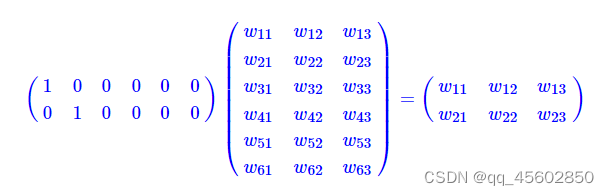
2x6矩阵乘6x3矩阵变成了2x3矩阵。
因此,embedding层,在某种程度上,就是用来降维的,降维的原理就是矩阵乘法。
也就是说,假如我们有一个100W x10W的矩阵,用它乘上一个10W x 20的矩阵,我们可以把它降到100W x 20,瞬间量级降了10W/20=5000倍!!!然而,中间那个10W x 20的矩阵,可以理解为查询表,也可以理解为映射表,也可以理解为过度表。

低维的数据可能包含的特征是非常笼统的,我们需要不停地拉近拉远来改变我们的感受野。
embedding的又一个作用体现了,对低维的数据进行升维时,可能把一些其他特征给放大了,或者把笼统的特征给分开了。同时,这个embedding是一直在学习在优化的,就使得整个拉近拉远的过程慢慢形成一个良好的观察点。比如:我来回靠近和远离屏幕,发现45厘米是最佳观测点,这个距离能10秒就把5个不同点找出来了。
回想一下为什么CNN层数越深准确率越高,卷积层卷了又卷,池化层池了又升,升了又降,全连接层连了又连。因为我们也不知道它什么时候突然就学到了某个有用特征。但是不管怎样,学习都是好事,所以让机器多卷一卷,多连一连,反正错了多少我会用交叉熵告诉你,怎么做才是对的我会用梯度下降算法告诉你,只要给你时间,你迟早会学懂。因此,理论上,只要层数深,只要参数足够,NN能拟合任何特征。
https://www.freesion.com/article/35401156246/















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









