




一. 线程间划分工作的技术
1.按数量切分
最简单的并行算法,就是并行化的std::for_each,其会对一个数据集中每个元素执行同一个操作。为了并行化该算法,可以为数据集中每个元素分配一个处理线程。如何划分才能获得最佳的性能,很大程度上取决于数据结构实现的细节,在之后有关性能问题的章节会再提及此问题。
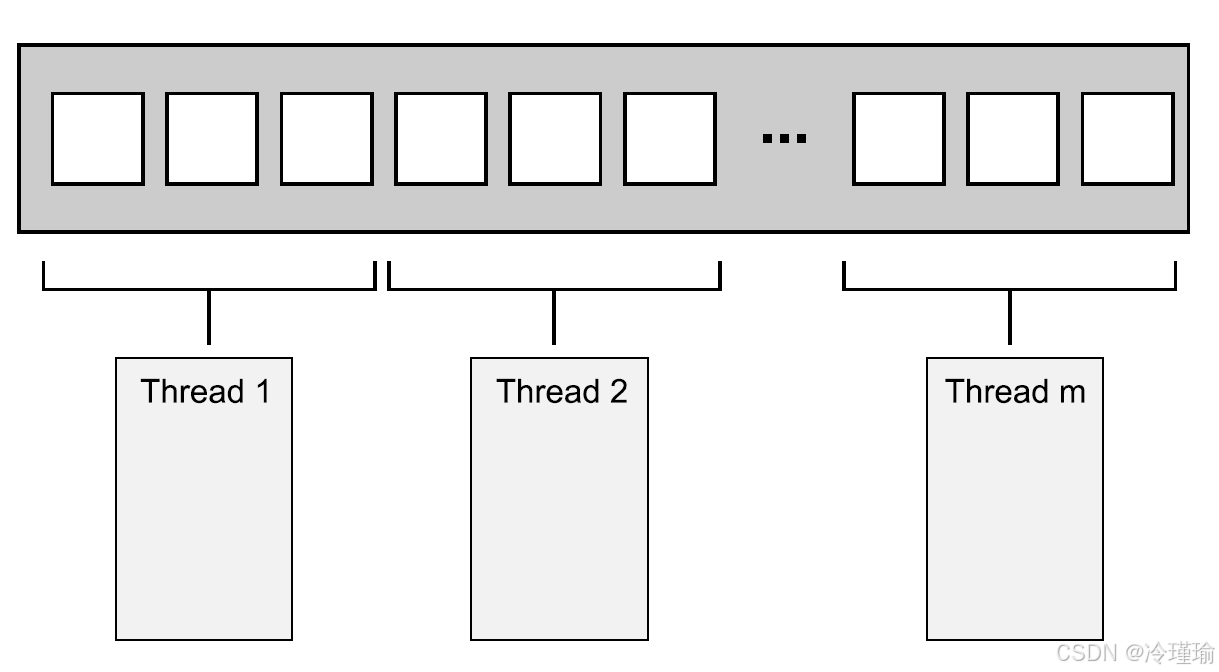
最简单的分配方式:第一组N个元素分配一个线程,下一组N个元素再分配一个线程,以此类推,如图8.1所示。不管数据怎么分,每个线程都会对分配给它的元素进行操作,不过并不会和其他线程进行沟通,直到处理完成。
虽然这个技术十分强大,但是并不是哪都适用。有时不能像之前那样,对任务进行整齐的划分,因为只有对数据进行处理后,才能进行明确的划分。这里特别适用了递归算法,就像快速排序;下面就来看看这种特别的方式。
2.递归划分
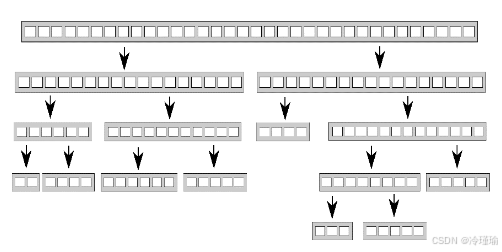
快速排序有两个最基本的步骤:将数据划分到中枢元素之前或之后,然后对中枢元素之前和之后的两半数组再次进行快速排序。这里不能通过对数据的简单划分达到并行,因为,只有在一次排序结束后,才能知道哪些项在中枢元素之前和之后。当要对这种算法进行并行化,很自然的会想到使用递归。每一级的递归都会多次调用quick_sort函数,因为需要知道哪些元素在中枢元素之前和之后。递归调用是完全独立的,因为其访问的是不同的数据集,并且每次迭代都能并发执行。
代码如下:
#include <iostream>
#include <thread>
#include <memory>
#include <future>
template<typename T>
void quick_sort_recursive(T arr[], int start, int end) {
if (start >= end) return;
T key = arr[start];
int left = start, right = end;
while(left < right) {
while (arr[right] >= key && left < right) right--;
while (arr[left] <= key && left < right) left++;
std::swap(arr[left], arr[right]);
}
if (arr[left] < key) {
std::swap(arr[left], arr[start]);
}
quick_sort_recursive(arr, start, left - 1);
quick_sort_recursive(arr, left + 1, end);
}
template<typename T>
void quick_sort(T arr[], int len) {
quick_sort_recursive(arr, 0, len - 1);
}
int main() {
int num_arr[] = { 5,3,7,6,4,1,0,2,9,10,8 };
int length = sizeof(num_arr) / sizeof(int);
quick_sort(num_arr, length );
std::cout << "sorted result is ";
for (int i = 0; i < length; i++) {
std::cout << " " << num_arr[i];
}
std::cout << std::endl;
}
在并行计算实践中,我们早期实现的递归式快速排序算法采用了动态任务分配策略。该实现的核心机制是:每当递归深入一层,就通过std::async()创建异步任务处理数据分区的前半段,同时由当前线程继续处理后半段数据。这种设计的关键优势在于将线程调度决策权交给C++标准库——标准库会根据当前系统负载智能选择在新线程中执行任务,或直接在调用线程上同步执行。
这种动态调度策略对处理大规模数据集尤为重要。理论上,如果每次递归都强制创建新线程,在处理超大规模数据时会导致线程数量呈指数级增长。这不仅可能触发线程资源枯竭,实践中还发现当线程数量超过最佳临界值后,程序性能反而会出现显著下降。因此,在采用递归分治策略时,必须对线程创建数量施加有效约束,防止线程资源的无节制消耗。
虽然std::async()在此场景下表现尚可,但我们通过性能分析发现仍有优化空间。特别是在处理TB级数据集时,频繁创建线程的开销变得不可忽视。为此,我们转而采用线程池方案进行优化,通过复用预创建的线程来降低系统开销。这一改进与《C++并发编程实践》中提出的并行算法设计原则不谋而合——作者在实现并行accumulate算法时,正是通过std::hardware_concurrency()获取硬件支持的并发线程数,并据此建立最优的并行粒度控制机制。
当线程无所事事,不是已经完成对自己数据块的梳理,就是在等待一组排序数据的产生;线程可以从栈上获取这组数据,并且对其排序。
代码如下:
template<typename T>
struct sorter //1
{
struct chunk_to_sort
{
std::list<T> data;
std::promise<std::list<T> > promise;
};
thread_safe_stack<chunk_to_sort> chunks; //⇽-- - 2
std::vector<std::thread> threads; // ⇽-- - 3
unsigned const max_thread_count;
std::atomic<bool> end_of_data;
sorter() :
max_thread_count(std::thread::hardware_concurrency() - 1),
end_of_data(false)
{}
~sorter() //⇽-- - 4
{
end_of_data = true; //⇽-- - 5
for (unsigned i = 0; i < threads.size(); ++i)
{
threads[i].join(); //⇽-- - 6
}
}
void try_sort_chunk()
{
std::shared_ptr<chunk_to_sort> chunk = chunks.try_pop(); //⇽-- - 7
if (chunk)
{
sort_chunk(chunk); //⇽-- - 8
}
}
/**
* @brief 核心的递归排序函数
*
* 这个函数实现了快速排序的递归逻辑。首先检查输入是否为空,
* 如果为空直接返回。否则,取出第一个元素作为分区值,将剩余元素分为
* 小于分区值和大于等于分区值的两部分。然后递归对这两部分进行排序,
* 并将结果合并。
*
* 在递归过程中,会将一部分数据作为新的块压入栈中,并启动新线程进行处理。
* 通过这种方式实现并行排序。
*/
std::list<T> do_sort(std::list<T>& chunk_data) //⇽-- - 9
{
if (chunk_data.empty())
{
return chunk_data;
}
std::list<T> result;
// 取出第一个元素作为分区值
result.splice(result.begin(),chunk_data,chunk_data.begin());
T const& partition_val = *result.begin();
// 对剩余元素进行分区,将小于分区值的元素放在前面
typename std::list<T>::iterator divide_point = //⇽-- - 10
std::partition(chunk_data.begin(),chunk_data.end(),
[&](T const& val) {return val < partition_val; });
// 创建新的下层块,存储小于分区值的元素
chunk_to_sort new_lower_chunk;
new_lower_chunk.data.splice(new_lower_chunk.data.end(),
chunk_data,chunk_data.begin(),
divide_point);
// 获取下层块的 future,用于等待排序结果
std::future<std::list<T> > new_lower =
new_lower_chunk.promise.get_future();
// 将新块推入栈中,等待其他线程处理
chunks.push(std::move(new_lower_chunk)); // ⇽-- - 11
if (threads.size() < max_thread_count) // ⇽-- - 12
{
threads.push_back(std::thread(&sorter<T>::sort_thread,this));
}
// 递归排序上层块(大于等于分区值的元素)
std::list<T> new_higher(do_sort(chunk_data));
result.splice(result.end(),new_higher);
// 等待下层块排序完成
// 由于上层快已经排序完成,且通过new_lower绑定future可以窥测其余线程是否将下层块处理完毕,
//如果!= ready,泽尝试处理其他快。
while (new_lower.wait_for(std::chrono::seconds(0)) !=
std::future_status::ready) //⇽-- - 13
{
// 尝试处理其他块,充分利用线程资源
try_sort_chunk(); // ⇽-- - 14
}
// 将下层块结果合并到结果列表中
result.splice(result.begin(),new_lower.get());
return result;
}
/**
* @brief 对块进行排序并将结果存储在 promise 中
*
* 这个函数接收一个 chunk_to_sort 指针,调用 do_sort 对其 data 进行排序,
* 然后将排序结果存储到对应的 promise 中。这样,等待这个 promise 的线程
* 就可以获取到排序后的结果。
*/
void sort_chunk(std::shared_ptr<chunk_to_sort > const& chunk)
{
chunk->promise.set_value(do_sort(chunk->data)); //⇽-- - 15
}
void sort_thread()
{
while (!end_of_data) //⇽-- - 16
{
try_sort_chunk(); // ⇽-- - 17
//交出时间片
std::this_thread::yield(); //⇽-- - 18
}
}
};
/**
* @brief 并行快速排序的入口函数
*
* 这个函数是用户调用的入口。它首先检查输入是否为空,
* 如果为空直接返回。否则创建 sorter 实例,调用 do_sort 进行排序。
*
* @param input 输入的链表
* @return std::list<T> 排序后的链表
*/
template<typename T>
std::list<T> parallel_quick_sort(std::list<T> input) //⇽-- - 19
{
if (input.empty())
{
return input;
}
sorter<T> s;
return s.do_sort(input); //⇽-- - 20
}
其核心是通过递归将数据分割为小块,利用多线程异步处理子任务来提升性能。sorter类内部维护一个线程安全的任务栈(chunk_to_sort),存储待排序的数据块和与之关联的promise对象用于异步返回结果;工作线程池(threads)从任务栈中动态获取任务,通过do_sort函数递归地将数据按基准值分割为lower和higher两部分,将lower部分封装为独立任务推入栈中由其他线程处理,同时当前线程递归处理higher部分,并通过future等待子任务完成,最终合并结果。线程在空闲时通过try_sort_chunk主动尝试处理栈中任务,避免阻塞等待,而析构函数通过原子标志end_of_data通知线程退出并安全回收资源。整体设计通过任务窃取(当前线程处理完毕后查看其余线程future是否已经ready)、动态负载均衡(线程与处理数据绑定)和异步协作(多线程),在控制线程数量的前提下最大化利用多核性能,实现高效并行排序。
3.通过任务类型划分工作
虽然为每个线程分配不同的数据块,但工作的划分(无论是之前就划分好,还是使用递归的方式划分)仍然在理论阶段,因为这里每个线程对每个数据块的操作是相同的。而另一种选择是让线程做专门的工作,也就是每个线程做不同的工作,就像水管工和电工在建造一所屋子的时候所做的不同工作那样。线程可能会对同一段数据进行操作,但它们对数据进行不同的操作。
对分工的排序,也就是从并发分离关注结果;每个线程都有不同的任务,这就意味着真正意义上的线程独立。其他线程偶尔会向特定线程交付数据,或是通过触发事件的方式来进行处理;不过总体而言,每个线程只需要关注自己所要做的事情即可。其本身就是基本良好的设计,每一段代码只对自己的部分负责。
例如:定义定时器使用问题,如果定时器只在特定线程使用,则将定时器与线程进行绑定。这样定时器的创建销毁使用不会与其他线程冲突,也不需要从应用层担心定时器的维护。但是如果定时器和定时器直接有依赖关系,可以借助Actor模式+CRTP(奇异递归模板模式)进行区分。
3.1 Actor模式
Actor 设计模式是一种并发编程模型,核心思想是通过独立的、封装的计算单元(称为 Actor)之间的消息传递来实现通信。每个 Actor 拥有自己的状态,且不直接与其他 Actor 共享内存,而是通过异步消息进行交互。这种设计避免了锁、竞态条件等传统多线程编程的复杂性。
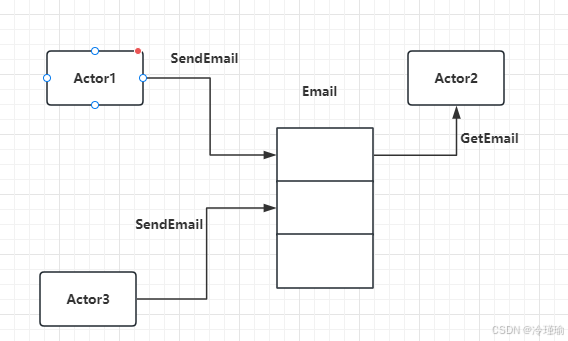
简单点说,actor通过消息传递的方式与外界通信。消息传递是异步的。每个actor都有一个邮箱,该邮箱接收并缓存其他actor发过来的消息,actor一次只能同步处理一个消息,处理消息过程中,除了可以接收消息,不能做任何其他操作。Actor在发送消息前是直到接收方是谁,而接受方收到消息后也知道发送方是谁。
每一个类独立在一个线程里称作Actor,Actor之间通过队列通信,比如Actor1 发消息给Actor2, Actor2 发消息给Actor1都是投递到对方的队列中。好像给对方发邮件,对方从邮箱中取出一样。如下图
3.2 CRTP(奇异递归模板模式)
CRTP(Curiously Recurring Template Pattern) 是一种 C++ 模板元编程技术,核心是派生类继承一个以自身为模板参数的基类,它通过编译期多态实现代码复用,避免虚函数开销。
3.2.1 语法结构
#include <iostream>
template <typename Derived>
class Base {
public:
void call() {
static_cast<Derived*>(this)->implementation();
}
void common() {
std::cout << "[Base] Common logic\n";
call();
}
};
// 派生类1
class Derived1 : public Base<Derived1> {
public:
void implementation() {
std::cout << "[Derived1] Specific logic\n";
}
};
// 派生类2
class Derived2 : public Base<Derived2> {
public:
void implementation() {
std::cout << "[Derived2] Different logic\n";
}
};
// 派生类3(假设需要额外参数)
class Derived3 : public Base<Derived3> {
public:
void implementation() {
std::cout << "[Derived3] Advanced logic with parameter: " << value_ << "\n";
}
void set_value(int v) { value_ = v; }
private:
int value_ = 0;
};
int main() {
Derived1 d1;
d1.common(); // 输出:[Base] Common logic → [Derived1] Specific logic
Derived2 d2;
d2.common(); // 输出:[Base] Common logic → [Derived2] Different logic
Derived3 d3;
d3.set_value(42);
d3.common(); // 输出:[Base] Common logic → [Derived3] Advanced logic with parameter: 42
}
3.2.2 与虚继承区别
| 特性 | CRTP | 虚函数继承 |
|---|---|---|
| 多态时机 | 编译期多态(静态绑定) | 运行时多态(动态绑定) |
| 性能 |
无虚函数表(vtable)开销,效率更高, 适用于高性能场景(如数学库、高频调用逻辑) 编译期确定的类型。 |
虚函数表查找,有一定运行时开销(两次寻址,访问虚函数表地址,根据虚函数表找虚函数) |
| 代码生成 | 模板实例化为具体类型,可能代码膨胀 | 虚函数表统一管理,代码更紧凑 |
| 灵活性 | 类型在编译期确定,无法动态替换 | 支持运行时动态绑定(如工厂模式) |
| 接口约束 | 派生类必须实现基类指定的方法 | 派生类必须覆盖纯虚函数 |
| 扩展性 | 适合静态代码复用(如运算符重载) | 适合动态多态(如插件系统),便接口于管理 |
| 错误检测 | 编译期检查类型匹配,错误更早暴露 | 运行时可能因未实现虚函数导致崩溃 |
关于第五点接口约束:
CRTP:基类通过模板的静态类型转换(static_cast<Derived*>(this))调用派生类的方法。若派生类未实现基类预期的方法,编译时会直接报错(如未找到 implementation() 方法)。
虚函数:若基类声明了纯虚函数(如 virtual void foo() = 0;),则派生类必须覆盖(实现)该函数,否则派生类无法实例化,编译会报错。
3.3 Actor+CCTP 并发任务设计示例
#include <thread>
#include <atomic>
#include <iostream>
#include <mutex>
#include <queue>
#include <atomic>
template<typename ClassType, typename QueType>
class ActorSingle {
public:
static ClassType& Inst() {
static ClassType as;
return as;
}
~ ActorSingle(){
}
void PostMsg(const QueType& data) {
_que.push(data);
}
protected:
ActorSingle():_bstop(false){
}
ActorSingle(const ActorSingle&) = delete;
ActorSingle(ActorSingle&&) = delete;
ActorSingle& operator = (const ActorSingle&) = delete;
std::atomic<bool> _bstop;
ThreadSafeQue<QueType> _que;
std::thread _thread;
};
struct MsgClassA {
std::string name;
friend std::ostream& operator << (std::ostream& os, const MsgClassA& ca) {
os << ca.name;
return os;
}
};
class ClassA : public ActorSingle<ClassA, MsgClassA> {
friend class ActorSingle<ClassA, MsgClassA>;
public:
~ClassA() {
_bstop = true;
_que.NotifyStop();
_thread.join();
std::cout << "ClassA destruct " << std::endl;
}
void DealMsg(std::shared_ptr<MsgClassA> data) {
std::cout << "class A deal msg is " << *data << std::endl;
MsgClassB msga;
msga.name = "llfc";
ClassB::Inst().PostMsg(msga);
}
private:
ClassA(){
_thread = std::thread([this]() {
for (; (_bstop.load() == false);) {
std::shared_ptr<MsgClassA> data = _que.WaitAndPop();
if (data == nullptr) {
continue;
}
DealMsg(data);
}
std::cout << "ClassA thread exit " << std::endl;
});
}
};
struct MsgClassB {
std::string name;
friend std::ostream& operator << (std::ostream& os, const MsgClassB& ca) {
os << ca.name;
return os;
}
};
class ClassB : public ActorSingle<ClassB, MsgClassB> {
friend class ActorSingle<ClassB, MsgClassB>;
public:
~ClassB() {
_bstop = true;
_que.NotifyStop();
_thread.join();
std::cout << "ClassB destruct " << std::endl;
}
void DealMsg(std::shared_ptr<MsgClassB> data) {
std::cout << "class B deal msg is " << *data << std::endl;
MsgClassC msga;
msga.name = "llfc";
ClassC::Inst().PostMsg(msga);
}
private:
ClassB(){
_thread = std::thread([this]() {
for (; (_bstop.load() == false);) {
std::shared_ptr<MsgClassB> data = _que.WaitAndPop();
if (data == nullptr) {
continue;
}
DealMsg(data);
}
std::cout << "ClassB thread exit " << std::endl;
});
}
};
struct MsgClassC {
std::string name;
friend std::ostream& operator << (std::ostream& os, const MsgClassC& ca) {
os << ca.name;
return os;
}
};
class ClassC : public ActorSingle<ClassC, MsgClassC> {
friend class ActorSingle<ClassC, MsgClassC>;
public:
~ClassC() {
_bstop = true;
_que.NotifyStop();
_thread.join();
std::cout << "ClassC destruct " << std::endl;
}
void DealMsg(std::shared_ptr<MsgClassC> data) {
std::cout << "class C deal msg is " << *data << std::endl;
}
private:
ClassC(){
_thread = std::thread([this]() {
for (; (_bstop.load() == false);) {
std::shared_ptr<MsgClassC> data = _que.WaitAndPop();
if (data == nullptr) {
continue;
}
DealMsg(data);
}
std::cout << "ClassC thread exit " << std::endl;
});
}
};
template<typename T>
class ThreadSafeQue
{
private:
struct node
{
std::shared_ptr<T> data;
std::unique_ptr<node> next;
};
std::mutex head_mutex;
std::unique_ptr<node> head;
std::mutex tail_mutex;
node* tail;
std::condition_variable data_cond;
std::atomic<bool> _bstop;
node* get_tail()
{
std::lock_guard<std::mutex> tail_lock(tail_mutex);
return tail;
}
std::unique_ptr<node> pop_head()
{
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return old_head;
}
std::unique_lock<std::mutex> wait_for_data()
{
std::unique_lock<std::mutex> head_lock(head_mutex);
data_cond.wait(head_lock,[&] {return (_bstop.load() == true) || (head.get() != get_tail()); });
return std::move(head_lock);
}
std::unique_ptr<node> wait_pop_head()
{
std::unique_lock<std::mutex> head_lock(wait_for_data());
if (_bstop.load()) {
return nullptr;
}
return pop_head();
}
std::unique_ptr<node> wait_pop_head(T& value)
{
std::unique_lock<std::mutex> head_lock(wait_for_data());
if (_bstop.load()) {
return nullptr;
}
value = std::move(*head->data);
return pop_head();
}
std::unique_ptr<node> try_pop_head()
{
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == get_tail())
{
return std::unique_ptr<node>();
}
return pop_head();
}
std::unique_ptr<node> try_pop_head(T& value)
{
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == get_tail())
{
return std::unique_ptr<node>();
}
value = std::move(*head->data);
return pop_head();
}
public:
ThreadSafeQue() : // ⇽-- - 1
head(new node), tail(head.get()), _bstop(false)
{}
ThreadSafeQue(const ThreadSafeQue& other) = delete;
ThreadSafeQue& operator=(const ThreadSafeQue& other) = delete;
void NotifyStop() {
_bstop.store(true);
data_cond.notify_one();
}
std::shared_ptr<T> WaitAndPop() // <------3
{
std::unique_ptr<node> const old_head = wait_pop_head();
if (old_head == nullptr) {
return nullptr;
}
return old_head->data;
}
void WaitAndPop(T& value) // <------4
{
std::unique_ptr<node> const old_head = wait_pop_head(value);
}
std::shared_ptr<T> Try()
{
std::unique_ptr<node> old_head = try_pop_head();
return old_head ? old_head->data : std::shared_ptr<T>();
}
bool try_pop(T& value)
{
std::unique_ptr<node> const old_head = try_pop_head(value);
return old_head;
}
bool empty()
{
std::lock_guard<std::mutex> head_lock(head_mutex);
return (head.get() == get_tail());
}
void push(T new_value) //<------2
{
std::shared_ptr<T> new_data(
std::make_shared<T>(std::move(new_value)));
std::unique_ptr<node> p(new node);
{
std::lock_guard<std::mutex> tail_lock(tail_mutex);
tail->data = new_data;
node* const new_tail = p.get();
tail->next = std::move(p);
tail = new_tail;
}
data_cond.notify_one();
}
};
int main()
{
MsgClassA msga;
msga.name = "llfc";
ClassA::Inst().PostMsg(msga);
std::this_thread::sleep_for(std::chrono::seconds(2));
std::cout << "main process exited!\n";
}
二. 影响并发代码性能的因素
1.处理器数量对多线程性能的影响
开发和目标平台的处理器数量及核心数可能不同,导致并发程序行为和性能表现差异,需在不同平台上测试,不可一撮二就。单核16芯、四核双芯或十六核单芯处理器都能运行16个并发线程。线程数少于16时,处理器可能空闲;线程数超过16时,会出现超额认购,浪费处理器时间在线程切换上。
利用C++标准线程库的std::thread::hardware_concurrency()可获取硬件支持的线程数量,但需谨慎使用,因为它不考虑系统上其他运行线程(同一时刻内其余进程也可能使用cpu),可能导致超额认购。std::async()能合理安排线程数量,避免超额认购;线程池也可谨慎使用来管理线程资源,提高效率。
随着处理器数量增加,多个处理器访问同一数据时,会出现数据冲突或竞争,影响性能,需通过同步机制等来解决。
2.数据争用与乒乓缓存
乒乓缓存:指的某个数据在多个cpu的缓存中反复更新传递(当多个线程频繁访问同一缓存行(Cache Line)中的数据时,会触发缓存一致性协议(如MESI)的反复失效和同步,导致性能下降。)
当有线程对数据进行修改的时候,这个修改需要更新到其他核芯的缓存中去,就要耗费一定的时间。根据线程的操作性质,以及使用到的内存序,这样的修改可能会让第二个处理器停下来,等待硬件内存更新缓存中的数据。
看下述代码
std::atomic<unsigned long> counter(0);
void processing_loop()
{
while(counter.fetch_add(1,std::memory_order_relaxed)<100000000)
{
do_something();
}
}
由于counter是全局变量,当多个线程同时调用processing_loop去修改同一个变量,这就要求counter在缓存内做一份拷贝,再改变自己的值,或其他线程以发布的方式对缓存中的拷贝副本进行更新。fetch_add是一个“读-改-写”操作,因此就要对最新的值进行检索。如果另一个线程在另一个处理器上执行同样的代码,counter的数据需要在两个处理器之间进行传递,那么这两个处理器的缓存中间就存有counter的最新值(当counter的值增加时)。如果do_something()足够短,或有很多处理器来对这段代码进行处理时,处理器将会互相等待;一个处理器准备更新这个值,另一个处理器正在修改这个值,所以该处理器就不得不等待第二个处理器更新完成,并且完成更新传递时,才能执行更新。这种情况被称为高竞争(high contention)。
在这个循环中,counter的数据将在每个缓存中传递若干次。这就叫做乒乓缓存(cache ping-pong)
3.避免伪共享
处理器缓存通常不会用来处理在单个存储位置,但其会用来处理称为缓存行(cache lines)的内存块。内存块通常大小为32或64字节,处理器对缓存行进行数据处理。这样有优势也有劣势:
优势:当线程访问的一组数据是在同一数据行中,对于应用的性能来说就要好于向多个缓存行进行传播。
劣势:当在同一缓存行存储的是无关数据,且需要被不同线程访问,这就会造成性能问题
例如:
struct Data {
int x; // 线程A频繁修改
int y; // 线程B频繁修改
};
X和Y分别是线程A和线程B关注的两个属性,线程A修改x会导致该缓存行在核心B的缓存中失效,反之亦然(即使y未被修改)。每次修改触发MESI协议的Invalidate消息,其他核心需重新加载缓存行。缓存行频繁失效导致大量缓存同步操作,CPU时间浪费在协调缓存一致性上。高并发下,这种无效化操作成为性能瓶颈。
解决办法:
为了减少伪共享,可以将被不同线程频繁访问的数据项放置在不同的缓存行中。这样,每个线程访问的数据项就不会互相干扰。可以在数据项之间插入足够的填充字节,使得每个数据项都位于不同的缓存行中。
手动填充:
struct AlignedData {
int x;
char padding[60]; // 填充至64字节(假设缓存行64字节)
int y;
};
编译器指令对齐:
struct alignas(64) ThreadData {
int local_counter;
};
线程本地存储:
使用线程局部变量避免共享
thread_local int local_x; // 每个线程独有副本
通过sysconf获取系统缓存行大小(Linux):
long cache_line_size = sysconf(_SC_LEVEL1_DCACHE_LINESIZE);
案例:
错误实现:
std::atomic<int> counters[4]; // 假设4个线程各自累加自己的计数器
优化后:
struct alignas(64) AlignedCounter {
std::atomic<int> value;
};
AlignedCounter counters[4]; // 每个计数器独占缓存行
提供工具:
-
perf(Linux):通过perf stat -e cache-misses统计缓存未命中次数。 -
Valgrind的
Cachegrind:模拟缓存行为,分析缓存行争用。
4.数据紧凑是否重要?
数据并非越紧凑越好。对于单线程而言,紧凑布局更好,数据集中在少量缓存行,减少内存访问延迟。对于多线程而言,紧凑布局导致不同线程共享缓存行,频繁失效。
当线程数 > CPU核心数时,操作系统会在核心上切换线程(时间片轮转)。若线程A在核心1运行后切换到核心2,其使用的数据需从核心1的缓存迁移到核心2的缓存(或从内存重新加载)。若线程A和线程B的数据布局紧凑(共享缓存行),切换时核心需加载更多无关数据,浪费缓存空间。同时频繁切换导致大量缓存行迁移,,进而导致CPU性能下降。
总的来说我们需要控制几个原则:
- 单线程:紧凑布局,减少缓存行占用。
- 多线程:隔离数据,避免共享缓存行。
-
系统级:控制线程数量,减少切换频率。
三.多线程性能优化数据结构设计关键要点
我们主要从以下角度考量:
竞争(Contention):减少线程对共享资源的争用。
伪共享(False Sharing):避免不同线程频繁访问同一缓存行的不同数据。
数据局部性(Data Proximity):优化数据布局以提升缓存利用率。
1.数组结构优化策略
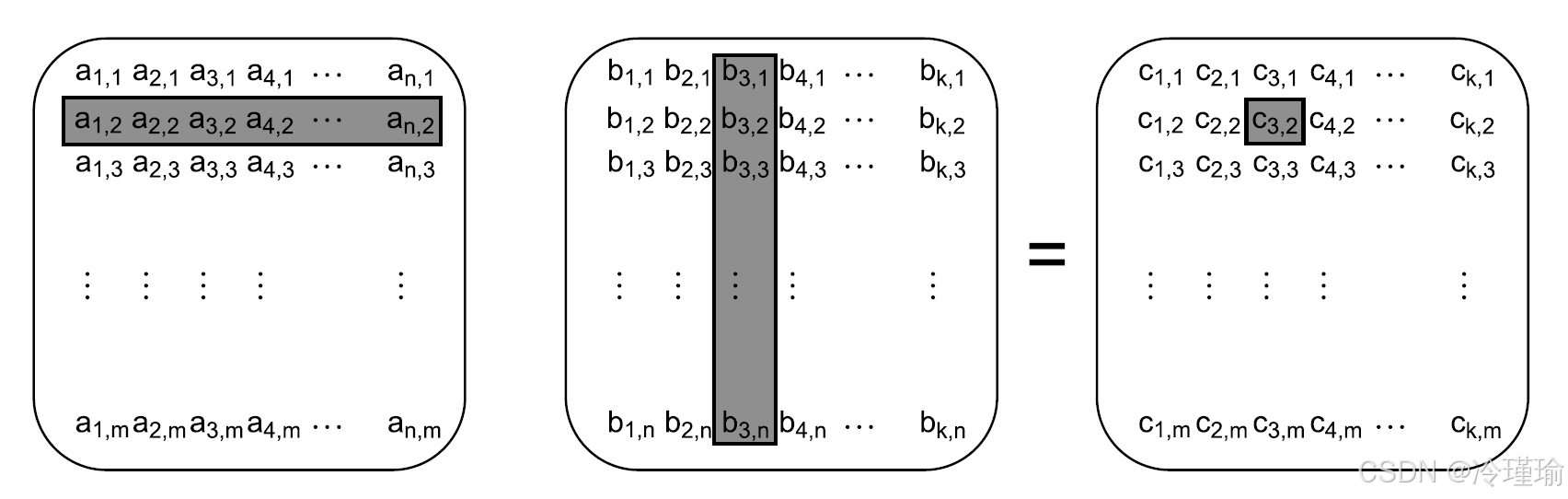
当线程处理连续行,写入列数据时易引发伪共享(若列连续存储)。
当线程处理连续列,写入行数据时内存连续,伪共享风险较低。
分块处理:将矩阵划分为子块(如100x100),减少数据访问量(仅需相邻行/列),显著降低缓存缺失,提升性能。
2.其他数据结构的优化
对于树状结构,可能存在以下两点原因:
2.1 动态内存分配特性
传统树结构(如二叉树)的节点通常通过new或malloc动态分配,内存地址随机分散。CPU以缓存行为单位进行数据加载。随机节点可能导致:遍历树的时候可能会频繁导致缓存缺失,触发MESI。
解决思路:预先分配连续内存块(如数组)存储所有节点。通过索引(而非指针)管理父子关系。
例如:
struct TreeNode {
int data;
int left_child_idx; // 左子节点索引
int right_child_idx; // 右子节点索引
};
TreeNode node_pool[MAX_NODES]; // 连续内存存储所有节点
通过一定的内存分配策略,将树按层级或子树划分为块,每块内节点连续存储。节点在内存中连续排列,遍历时触发缓存预取,减少缺失。
不过这种策略只适用于已经预想到的节点大小,或者后续检测内存不够进行扩容。同时在设计的时候我们去关注以下节点大小,避免超过缓存行。
2.2 分离节点元数据与实际数据:避免伪共享
在树的结构中一般会姜元数据(指针)与实际数据(键值对)混合存储。多线程场景下:线程A修改节点X的key,线程B修改节点Y的left指针。若X和Y位于同一缓存行,触发伪共享(False Sharing)。
struct TreeNode {
TreeNode* left; // 元数据(指针)
TreeNode* right; // 元数据(指针)
int key; // 实际数据
Value value; // 实际数据
};
可以将元数据与数据分离 ,或者设置缓存行隔离或者指定64字节对齐等等
struct TreeNode {
TreeNode* left;
TreeNode* right;
char padding1[64 - sizeof(TreeNode*) * 2]; // 填充至64字节
int key;
Value value;
char padding2[64 - sizeof(int) - sizeof(Value)]; // 再次填充
};
3.如何检测数据伪共享
一种测试伪共享问题的方法是:对大量的数据块填充数据,让不同线程并发的进行访问。比如,你可以使用,如果这样能够提高性能,你就能知道伪共享在这里的确存在。
struct protected_data
{
std::mutex m;
char padding[65536]; // 65536字节已经超过一个缓存行的数量级
my_data data_to_protect;
};
3.1 示例
未优化缓存行代码:
// File: false_sharing.cpp
#include <iostream>
#include <thread>
#include <chrono>
struct ContendedData {
volatile int a; // 线程1频繁修改
volatile int b; // 线程2频繁修改
};
void thread1_task(ContendedData& data) {
for (int i = 0; i < 100'000'000; ++i) {
data.a++;
}
}
void thread2_task(ContendedData& data) {
for (int i = 0; i < 100'000'000; ++i) {
data.b++;
}
}
// g++ -O0 no_dcache_opti.cpp -o no_dcache_opti -lpthread
int main() {
ContendedData data{0, 0};
auto start = std::chrono::high_resolution_clock::now();
std::thread t1(thread1_task, std::ref(data));
std::thread t2(thread2_task, std::ref(data));
t1.join();
t2.join();
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << "Time: " << duration << " ms\n";
std::cout << "Final values: a=" << data.a << ", b=" << data.b << "\n";
return 0;
}
优化缓存行代码:
// File: padded_data.cpp
#include <iostream>
#include <thread>
#include <chrono>
struct PaddedData {
volatile int a;
char padding[64 - sizeof(int)]; // 填充至64字节(假设缓存行大小为64字节)
volatile int b;
};
void thread1_task(PaddedData& data) {
for (int i = 0; i < 100'000'000; ++i) {
data.a++;
}
}
void thread2_task(PaddedData& data) {
for (int i = 0; i < 100'000'000; ++i) {
data.b++;
}
}
int main() {
PaddedData data{0, {}, 0};
auto start = std::chrono::high_resolution_clock::now();
std::thread t1(thread1_task, std::ref(data));
std::thread t2(thread2_task, std::ref(data));
t1.join();
t2.join();
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::cout << "Time: " << duration << " ms\n";
std::cout << "Final values: a=" << data.a << ", b=" << data.b << "\n";
return 0;
}
我的服务器是:
Linux hcss-ecs-4e5d 5.15.0-113-generic #123-Ubuntu SMP Mon Jun 10 08:16:17 UTC 2024 x86_64 x86_64 x86_64 GNU/Linux
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 42 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Vendor ID: AuthenticAMD
Model name: General Purpose Processor
CPU family: 25
Model: 1
Thread(s) per core: 2
Core(s) per socket: 1
Socket(s): 1
Stepping: 1
BogoMIPS: 4899.61
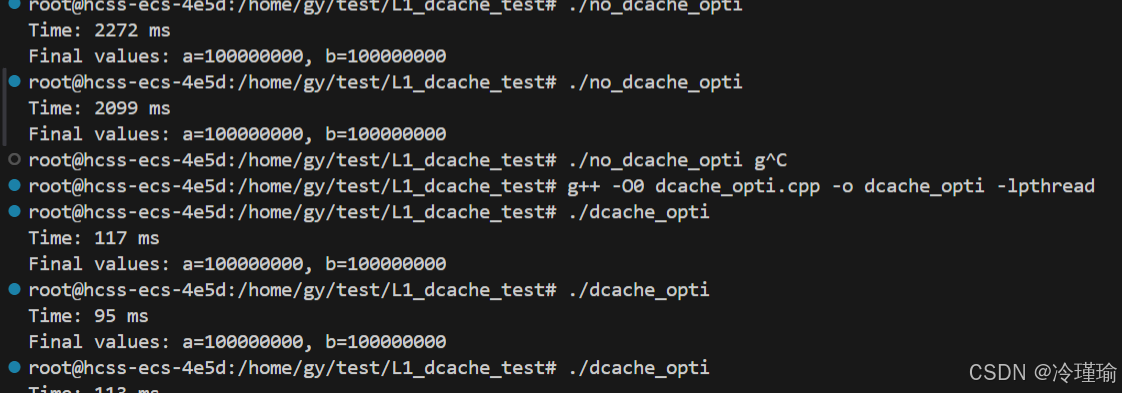
发现性能有大概20倍的优化 ,使用perf观测L1-dcache-load-misses:
使用命令:perf stat -e cache-misses,cache-references,L1-dcache-load-misses ./app
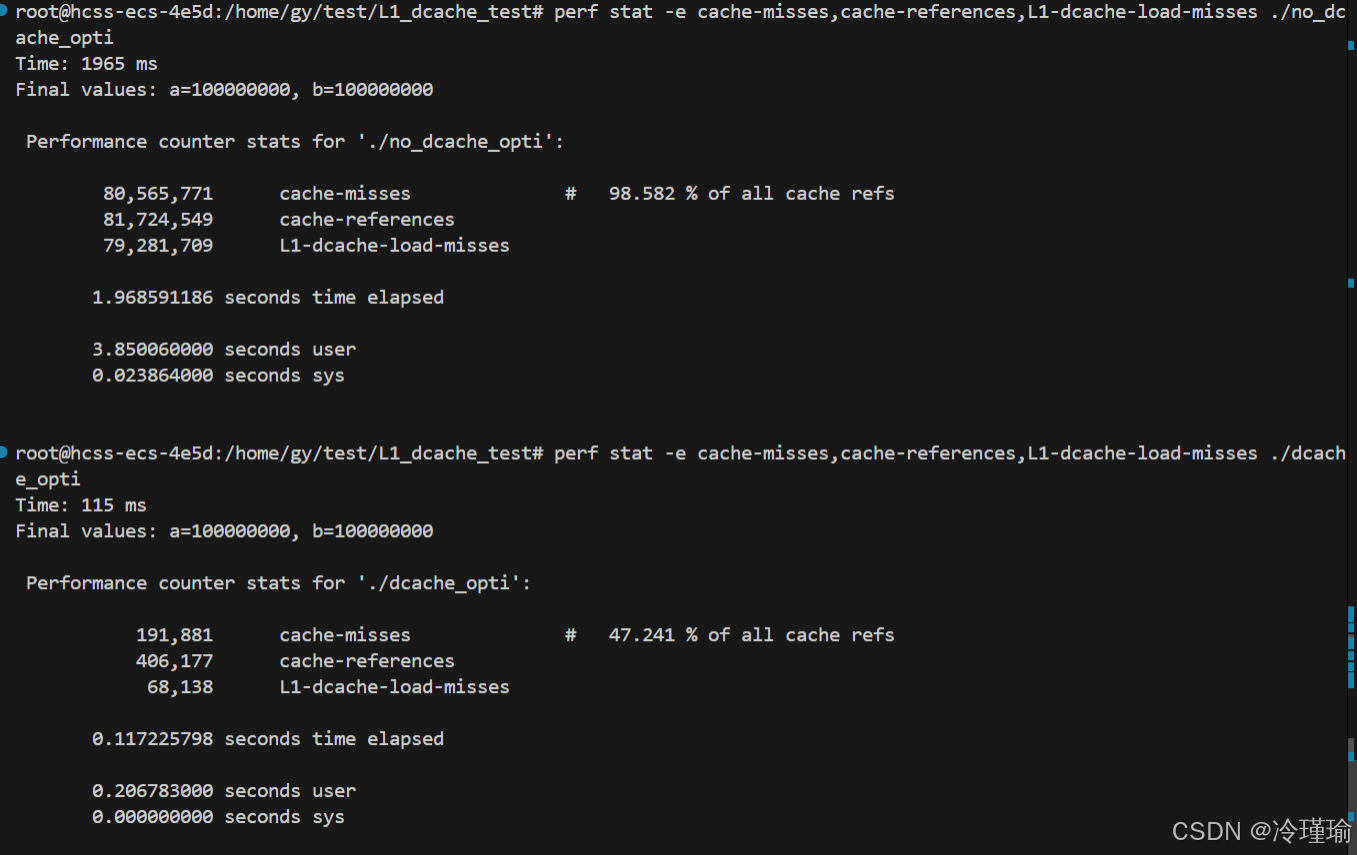
整理表格如下:
| 指标 | 未优化版本 | 优化版本 | 优化效果 |
|---|---|---|---|
| 执行时间 | 1965 ms | 115 ms | 17 倍加速 |
缓存总访问次数(cache-references) | 81,724,549 | 406,177 | 访问次数锐减 |
缓存未命中率(cache-misses) | 98.58% | 47.24% | 未命中次数减少 99.7% |
| L1 缓存未命中次数 | 79,281,709 | 68,138 | L1 命中率提升 99.9% |
| CPU 用户态时间 | 3.85 秒 | 0.206 秒 | CPU 利用率提升 18.7 倍 |
四.设计并发代码的注意事项
在C++并行算法中确保异常安全需要特别注意以下几点,以下是总结:
1.线程间的异常传播
并行代码中,若子线程抛出异常且未被捕获,将导致程序调用std::terminate()终止。
解决办法:封装任务与异常传递
-
使用
std::packaged_task和std::future将子线程的任务封装,使异常能通过future传递到主线程。 -
子线程中的异常会被
future捕获,主线程通过future::get()重新抛出异常,确保异常在正确上下文中处理。
2.资源泄露风险
线程未正确汇入(join)或分离(detach)可能导致资源泄露,尤其是在异常发生时。
解决办法:RAII管理线程生命周期
创建join_threads类,利用RAII在析构函数中自动汇入所有线程,即使发生异常也能保证线程安全汇入。
class join_threads {
std::vector<std::thread>& threads;
public:
explicit join_threads(std::vector<std::thread>& t) : threads(t) {}
~join_threads() {
for (auto& t : threads) {
if (t.joinable()) t.join();
}
}
};
3.示例
在清单8.2 std::accumulate的原始并行版本(源于清单2.8)
template<typename Iterator,typename T>
struct accumulate_block
{
void operator()(Iterator first,Iterator last,T& result)
{
result=std::accumulate(first,last,result); // 1
}
};
template<typename Iterator,typename T>
T parallel_accumulate(Iterator first,Iterator last,T init)
{
unsigned long const length=std::distance(first,last); // 2
if(!length)
return init;
unsigned long const min_per_thread=25;
unsigned long const max_threads=
(length+min_per_thread-1)/min_per_thread;
unsigned long const hardware_threads=
std::thread::hardware_concurrency();
unsigned long const num_threads=
std::min(hardware_threads!=0?hardware_threads:2,max_threads);
unsigned long const block_size=length/num_threads;
std::vector<T> results(num_threads); // 3
std::vector<std::thread> threads(num_threads-1); // 4
Iterator block_start=first; // 5
for(unsigned long i=0;i<(num_threads-1);++i)
{
Iterator block_end=block_start; // 6
std::advance(block_end,block_size);
threads[i]=std::thread( // 7
accumulate_block<Iterator,T>(),
block_start,block_end,std::ref(results[i]));
block_start=block_end; // 8
}
accumulate_block()(block_start,last,results[num_threads-1]); // 9
std::for_each(threads.begin(),threads.end(),
std::mem_fn(&std::thread::join));
return std::accumulate(results.begin(),results.end(),init); // 10
}
我们可以调整以下几部分:
3.1 任务函数调整:
struct accumulate_block {
T operator()(Iterator first, Iterator last) {
return std::accumulate(first, last, T()); // 返回结果而非引用
}
};
原始任务函数通过引用传递结果(void operator()(…, T& result)),若子线程中操作(如std::accumulate)抛出异常。
但是如果将任务函数改为返回结果(T operator()(…)),结合std::future:线程调用future.get()时重新抛出,允许在正确上下文中处理。
3.2 使用std::packaged_task分发任务:解决跨线程异常传播问题
在原示例中,子线程抛出的异常无法传递到主线程,直接触发std::terminate()。
std::packaged_task<T(Iterator, Iterator)> task(accumulate_block());
futures[i] = task.get_future();
threads[i] = std::thread(std::move(task), block_start, block_end);
通过std::packaged_task封装任务:任务中的异常会被自动捕获并存储到关联的std::future中。主线程通过future.get()获取结果或异常,实现跨线程安全的异常传播。
3.3 异常安全汇入线程:解决资源泄露问题
主线程在创建子线程后,若自身抛出异常(如内存不足)已创建的线程可能未被join(),导致资源泄露或僵尸线程。
通过引入RAII机制:
class join_threads {
std::vector<std::thread>& threads;
public:
~join_threads() {
for (auto& t : threads) if (t.joinable()) t.join();
}
};
在析构函数中确保所有线程join(),无论主线程正常退出还是因异常退出。
五. 在实践中设计并发代码
C++标准库中有三个标准函数,find, for_each以及partial_sum。我们将结合三个函数修改在清单8.2 的实现。
值得注意的是,在c++17中,find for_each函数可以直接指定std::execution::par进行并行操作,本章节通过多线程方式演示for_each并行操作。
1.并行版本for_each和find
1.1 方法一
template<typename Iterator,typename Func>
void parallel_for_each(Iterator first,Iterator last,Func f)
{
unsigned long const length=std::distance(first,last);
if(!length)
return;
unsigned long const min_per_thread=25;
unsigned long const max_threads=
(length+min_per_thread-1)/min_per_thread;
unsigned long const hardware_threads=
std::thread::hardware_concurrency();
unsigned long const num_threads=
std::min(hardware_threads!=0?hardware_threads:2,max_threads);
unsigned long const block_size=length/num_threads;
std::vector<std::future<void> > futures(num_threads-1); // 1
std::vector<std::thread> threads(num_threads-1);
join_threads joiner(threads);
Iterator block_start=first;
for(unsigned long i=0;i<(num_threads-1);++i)
{
Iterator block_end=block_start;
std::advance(block_end,block_size);
std::packaged_task<void(void)> task( // 2
[=]()
{
std::for_each(block_start,block_end,f);
});
futures[i]=task.get_future();
threads[i]=std::thread(std::move(task)); // 3
block_start=block_end;
}
std::for_each(block_start,last,f);
for(unsigned long i=0;i<(num_threads-1);++i)
{
futures[i].get(); // 4
}
}
我们将for_each置于lamda表达式中,封装成一个任务传递给thread, numthreads-1个线程并行处理for_each,剩下的主线程处理余下的for_each.最后通过futures.get汇总计算得到总结果。
1.2 方法二
第二种划分方式是我们采取递归的方式,实现并行std::accumulate的时候,使用std::async会简化代码;同样,parallel_for_each也可以使用std::async。实现如下所示。
async可以帮助我们判断是否需要开启线程还是自动串行执行。每次我们将要处理的数据一分为2,前半部分交给一个async开辟线程处理,后半部分在本线程处理。而所谓的本线程不一定是主线程,因为我们通过async递归执行parallel_for_each,也就相当于在一个线程里独立执行了。
template<typename Iterator,typename Func>
void parallel_for_each(Iterator first,Iterator last,Func f)
{
unsigned long const length=std::distance(first,last);
if(!length)
return;
unsigned long const min_per_thread=25;
if(length<(2*min_per_thread))
{
std::for_each(first,last,f); // 1
}
else
{
Iterator const mid_point=first+length/2;
std::future<void> first_half= // 2
std::async(¶llel_for_each<Iterator,Func>,
first,mid_point,f);
parallel_for_each(mid_point,last,f); // 3
first_half.get(); // 4
}
}
同理,find也是如此。可以将要查找的数据分为几个区间,每个区间交给一个线程处理。
当然也可以利用async的特性,让他决定是否需要开启线程
2.并行版本partial_sum
我们可以通过将输入数据划分为多个块,每个块由不同线程处理,并通过promise和future传递块之间的依赖值,以实现并行计算的同时保证结果的正确性。
例如:
输入数组{1,2,3,4,5,6,7},分块处理:
-
线程1处理{1,2,3}:计算前缀和为
{1,3,6},传递6给线程2。 -
线程2处理{4,5,6}:计算块内前缀和为
{4,9,15},加上6得{10,15,21},传递21给主线程。 -
主线程处理{7}:加上21得到28。
最终结果:{1,3,6,10,15,21,28}。
分块处理逻辑如下:
-
划分数据块:根据硬件线程数确定线程数量,将数据划分为多个块,每个线程处理一个块(主线程处理最后一个块)。
-
计算块内前缀和:每个线程先独立计算自己块内的前缀和。
-
处理跨块依赖:每个块的最后一个元素需要加上前一个块的最后一个元素值。通过
promise传递当前块的最后一个值,供后续块使用。 -
更新块内元素:在获取前一个块的最后一个值后,将其加到当前块的所有元素(除最后一个外)上
在process_chunk类中我们重载operator(),处理单个数据块。然后调用std::partial_sum计算块内前缀和。若存在前一个块的future值(previous_end_value),则获取该值并加到当前块的最后一个元素,随后更新当前块的promise。使用std::for_each将前一个块的累加值(addend)加到当前块除最后一个元素外的所有元素。每个线程处理一个分块,通过promise传递当前块的最后一个值,供后续块使用。主线程处理最后一个分块,并等待前一个块的最后一个值(若存在)。这样通过不断地传输叠加,计算最后的总值。
template<typename Iterator>
void parallel_partial_sum(Iterator first, Iterator last)
{
typedef typename Iterator::value_type value_type;
struct process_chunk //⇽-- - 1
{
void operator()(Iterator begin, Iterator last,
std::future<value_type>* previous_end_value,
std::promise<value_type>* end_value)
{
try
{
Iterator end = last;
++end;
std::partial_sum(begin, end, begin); //⇽-- - 2
if (previous_end_value) //⇽-- - 3
{
value_type addend = previous_end_value->get(); // ⇽-- - 4
*last += addend; // ⇽-- - 5
if (end_value)
{
end_value->set_value(*last); //⇽-- - 6
}
// ⇽-- - 7
std::for_each(begin, last, [addend](value_type& item)
{
item += addend;
});
}
else if (end_value)
{
// ⇽-- - 8
end_value->set_value(*last);
}
}
catch (...) // ⇽-- - 9
{
if (end_value)
{
end_value->set_exception(std::current_exception()); // ⇽-- - 10
}
else
{
throw; // ⇽-- - 11
}
}
}
};
unsigned long const length = std::distance(first, last);
if (!length) {
return;
}
unsigned long const min_per_thread = 25; //⇽-- - 12
unsigned long const max_threads = (length + min_per_thread - 1) / min_per_thread;
unsigned long const hardware_threads = std::thread::hardware_concurrency();
unsigned long const num_threads = std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
unsigned long const block_size = length / num_threads;
typedef typename Iterator::value_type value_type;
std::vector<std::thread> threads(num_threads - 1); // ⇽-- - 13
std::vector<std::promise<value_type> > end_values(num_threads - 1); // ⇽-- - 14
std::vector<std::future<value_type> > previous_end_values; // ⇽-- - 15
previous_end_values.reserve(num_threads - 1); // ⇽-- - 16
join_threads joiner(threads);
Iterator block_start = first;
for (unsigned long i = 0; i < (num_threads - 1); ++i)
{
Iterator block_last = block_start;
std::advance(block_last, block_size - 1); // ⇽-- - 17
// ⇽-- - 18
threads[i] = std::thread(process_chunk(), block_start, block_last,
(i != 0) ? &previous_end_values[i - 1] : 0,
&end_values[i]);
block_start = block_last;
++block_start; // ⇽-- - 19
previous_end_values.push_back(end_values[i].get_future()); // ⇽-- - 20
}
Iterator final_element = block_start;
std::advance(final_element, std::distance(block_start, last) - 1); // ⇽-- - 21
// ⇽-- - 22
process_chunk()(block_start, final_element, (num_threads > 1) ? &previous_end_values.back() : 0,
0);
}

















 6813
6813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









