






1.登录注册智能百度云并进行实名认证
1.1 个人认证每月有一千次的调用机会
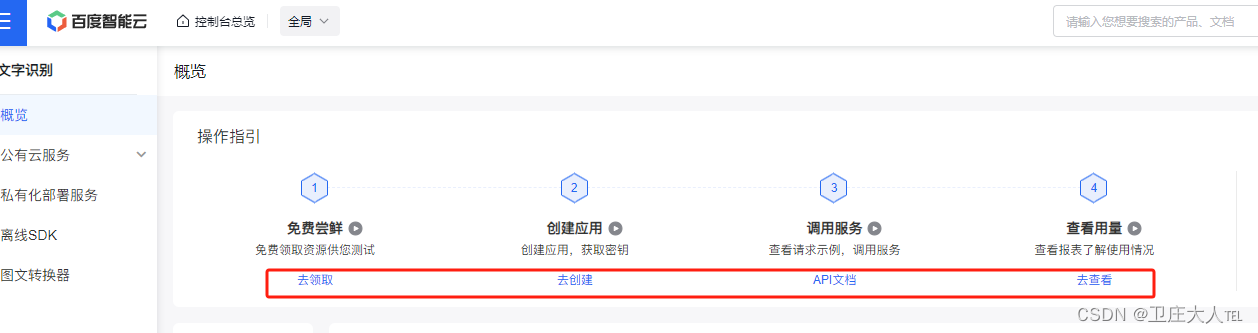
1.2 进入控制台查看相关信息
1.2.1 控制台地址
https://console.bce.baidu.com/ai/#/ai/ocr/overview/index
1.2.2 根据步骤进行设置即可
2.复制粘贴代码,进行调试
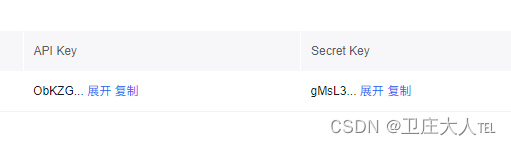
2.1 将工具类中的API_KEY 和 SECRET_KEY 更换为你申请的对应key值即可
https://console.bce.baidu.com/ai/#/ai/ocr/app/list
2.2 开发文档的地址
https://cloud.baidu.com/doc/OCR/s/1k3h7y3db
2.3 线上调试的地址
https://console.bce.baidu.com/tools/?_=1668425998119#/api?product=AI&project=%E6%96%87%E5%AD%97%E8%AF%86%E5%88%AB&parent=%E9%80%9A%E7%94%A8%E5%9C%BA%E6%99%AFOCR&api=rest%2F2.0%2Focr%2Fv1%2Faccurate_basic&method=post
2.4 工具类(更换秘钥可直接使用)
package com.ruoyi.utils;
/**
* @author zhuenci
* @ClassName imageToTextUtils
* Description: 识别图片中的文字信息
* @date 2024/3/14 10:19
* @version 1.0
*
* * 需要添加依赖
* * <!-- https://mvnrepository.com/artifact/com.squareup.okhttp3/okhttp -->
* * <dependency>
* * <groupId>com.squareup.okhttp3</groupId>
* * <artifactId>okhttp</artifactId>
* * <version>4.12.0</version>
* * </dependency>
*/
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.core.toolkit.CollectionUtils;
import com.ruoyi.common.utils.StringUtils;
import lombok.extern.slf4j.Slf4j;
import okhttp3.*;
import org.json.JSONException;
import org.json.JSONObject;
import java.io.IOException;
import java.net.URLEncoder;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Base64;
import java.util.List;
import java.util.Map;
@Slf4j
class imageToTextUtils {
public static final String API_KEY = "ObKZGDN8***886qg2I";
public static final String SECRET_KEY = "gMsL3LhQ***QT61i";
public static final String AUTH_TOKEN_URL = "https://aip.baidubce.com/oauth/2.0/token";
public static final String FILE_TO_TEXT_URL = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic?access_token=";
public static final String WORD_RESULT = "words_result";
public static final String WORDS = "words";
public static final String PDF_PAGE_NUM = "1";
public static final String PDF_PAGE_SIZE = "pdf_file_size";
static final OkHttpClient HTTP_CLIENT = new OkHttpClient().newBuilder().build();
public static void main(String []args) {
String text = getTextByPdfFile("D:\\**\\开发规范文档_V1.0.0.pdf", "1");
String dealText = dealTextFormatString(text,true);
String dealText2 = dealTextFormatString(text,false);
List<Map> listByText = getListByText(text);
Map<String, Object> textMap = getTextMap(text);
/* System.out.println("======================================================================");
System.out.println(JSON.toJSONString(textMap));
System.out.println("======================================================================");*/
/*System.out.println(dealText2);
System.out.println("======================================================================");*/
String path = "D:\\**\\开发规范文档_V1.0.0.pdf";
String multiPdfFileText = getMultiPdfFileText(path);
System.out.println("=======================================================");
System.out.println(multiPdfFileText);
System.out.println("=======================================================");
}
/**
* 返回的结果为追加值(标准化)
* isHh(是否换行)
**/
public static String dealTextFormatString(String text,boolean isHh) {
List<Map> list = getListByText(text);
if(CollectionUtils.isEmpty(list)){
return text;
}
StringBuilder sb = new StringBuilder();
list.forEach(s->{
if(!s.containsKey(WORDS)){
return;
}
sb.append(s.get(WORDS));
if(isHh){
sb.append("\n");
}
});
return sb.toString();
}
/**
* 返回的结果为list<map>值
**/
public static List<Map> getListByText(String text){
Map<String, Object> innerMap = getTextMap(text);
if(CollectionUtils.isEmpty(innerMap) || !innerMap.containsKey(WORD_RESULT)){
return null;
}
Object object = innerMap.get(WORD_RESULT);
List<Map> list = JSON.parseArray(JSON.toJSONString(object), Map.class);
return list;
}
/**
* 返回的结果为Map<String,Object>
**/
public static Map<String, Object> getTextMap(String text){
if(StringUtils.isEmpty(text)){
return null;
}
com.alibaba.fastjson.JSONObject obj = JSON.parseObject(text);
if(null == obj){
return null;
}
Map<String, Object> innerMap = obj.getInnerMap();
return innerMap;
}
/**
* pdf 多页识别
**/
public static String getMultiPdfFileText(String path){
String text = getTextByPdfFile(path, PDF_PAGE_NUM);
if(StringUtils.isEmpty(text)){
return text;
}
Map<String, Object> textMap = getTextMap(text);
if(CollectionUtils.isEmpty(textMap) || !textMap.containsKey(WORD_RESULT)){
return text;
}
Object object = textMap.get(PDF_PAGE_SIZE);
int pageSize = Integer.parseInt(String.valueOf(object));
StringBuilder sb = new StringBuilder();
//此次获取的值进行格式化
sb.append(dealTextFormatString(text,true));
System.out.println("=============================第【1】页结束==========================");
int next = Integer.parseInt(PDF_PAGE_NUM) + 1;
return dealMultiText(sb,pageSize,path,String.valueOf(next));
}
private static String dealMultiText(StringBuilder sb, int pageSize, String path, String current) {
String text = getTextByPdfFile(path, current);
if(StringUtils.isEmpty(text)){
return sb.toString();
}
Map<String, Object> textMap = getTextMap(text);
if(CollectionUtils.isEmpty(textMap) || !textMap.containsKey(WORD_RESULT)){
return sb.toString();
}
//此次获取的值进行格式化
sb.append(dealTextFormatString(text,true));
int i = Integer.parseInt(current);
System.out.println("=============================第【"+i+"】页结束==========================");
if(pageSize > i){
i = i + 1;
try {
Thread.sleep(500);
}catch (Exception e){
e.printStackTrace();
}
dealMultiText(sb,pageSize,path,String.valueOf(i));
}
return sb.toString();
}
/**
* // pdf_file 可以通过 getFileContentAsBase64("C:\fakepath\项链发票.pdf") 方法获取,
* 如果Content-Type是application/x-www-form-urlencoded时,二个参数传true
*
* 单页识别
* @param pdfFilePath
* @param pdfPageNum 识别的第几页
* @return
*/
public static String getTextByPdfFile(String pdfFilePath,String pdfPageNum){
String result = StringUtils.EMPTY;
try {
if(StringUtils.isEmpty(pdfPageNum)){
pdfPageNum = PDF_PAGE_NUM;
}
MediaType mediaType = MediaType.parse("application/x-www-form-urlencoded");
String pdfFileData = getFileContentAsBase64(pdfFilePath, true);
String param = String.format("pdf_file=%s&pdf_file_num=%s&detect_direction=false¶graph=false&probability=false",pdfFileData,pdfPageNum);
RequestBody body = RequestBody.create(mediaType, param);
Request request = new Request.Builder()
.url(FILE_TO_TEXT_URL + getAccessToken())
.method("POST", body)
.addHeader("Content-Type", "application/x-www-form-urlencoded")
.addHeader("Accept", "application/json")
.build();
Response response = HTTP_CLIENT.newCall(request).execute();
result = response.body().string();
}catch (IOException e){
log.error("获取pdf返回文字信息出错,错误信息为:{}",e.getMessage());
e.printStackTrace();
}
log.info("返回结果为:"+ result );
return result;
}
/**
* image 可以通过 getFileContentAsBase64("C:\fakepath\621eec7950394a008cc134ce8c797108.png") 方法获取,
* 如果Content-Type是application/x-www-form-urlencoded时,第二个参数传true
* @param imageUrl
* @return
*/
public static String getTextByImage(String imageUrl){
String result = StringUtils.EMPTY;
try {
String imageData = getFileContentAsBase64(imageUrl, true);
MediaType mediaType = MediaType.parse("application/x-www-form-urlencoded");
String imageParam = String.format("image=%s&detect_direction=false¶graph=false&probability=false",imageData);
RequestBody body = RequestBody.create(mediaType, imageParam);
Request request = new Request.Builder()
.url(FILE_TO_TEXT_URL + getAccessToken())
.method("POST", body)
.addHeader("Content-Type", "application/x-www-form-urlencoded")
.addHeader("Accept", "application/json")
.build();
Response response = HTTP_CLIENT.newCall(request).execute();
result = response.body().string();
}catch (IOException e){
log.error("获取图片返回文字信息出错,错误信息为:{}",e.getMessage());
e.printStackTrace();
}
log.info("返回结果为:"+ result );
return result;
}
/**
* 获取文件base64编码
*
* @param path 文件路径
* @param urlEncode 如果Content-Type是application/x-www-form-urlencoded时,传true
* @return base64编码信息,不带文件头
*/
static String getFileContentAsBase64(String path, boolean urlEncode) {
String base64 = StringUtils.EMPTY;
try {
byte[] b = Files.readAllBytes(Paths.get(path));
base64 = Base64.getEncoder().encodeToString(b);
if (urlEncode) {
base64 = URLEncoder.encode(base64, "utf-8");
}
}catch (IOException e){
log.error("获取文件base64编码出现问题,异常信息为:{}",e.getMessage());
e.printStackTrace();
}
return base64;
}
/**
* 从用户的AK,SK生成鉴权签名(Access Token)
*
* @return 鉴权签名(Access Token)
*/
static String getAccessToken() {
String accessToken = StringUtils.EMPTY;
try {
MediaType mediaType = MediaType.parse("application/x-www-form-urlencoded");
RequestBody body = RequestBody.create(mediaType, "grant_type=client_credentials&client_id=" + API_KEY + "&client_secret=" + SECRET_KEY);
Request request = new Request.Builder()
.url(AUTH_TOKEN_URL)
.method("POST", body)
.addHeader("Content-Type", "application/x-www-form-urlencoded")
.build();
Response response = HTTP_CLIENT.newCall(request).execute();
accessToken = new JSONObject(response.body().string()).getString("access_token");
}catch (IOException e){
log.error("http请求出错,异常信息为:{}",e.getMessage());
e.printStackTrace();
}catch (JSONException e){
log.error("获取accessToken出现错误,异常信息为:{}",e.getMessage());
e.printStackTrace();
}
return accessToken;
}
}

















 1605
1605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









