






2.1 经验误差与过拟合
错误率(error rate): 分类错误的样本数占样本总数的比例
精度(accuracy):1- 错误率
训练误差 / 经验误差:在训练集上的误差
泛化误差:在新样本上的误差
过拟合
欠拟合
2.2 评估方法
测试集:测试学习器对新样本的判别能力,以测试集上的“测试误差”作为泛化误差的近似
对数据集进行适当的处理,拆分成训练集和测试集,常用的处理方法:
2.2.1 留出法
直接将数据集划分为两个互斥的集合
2.2.2 交叉验证法
将数据集划分为k个大小相似的互斥子集。每次用k-1个子集的并集作为训练集,余下的子集作为测试集合,得到k组训练/测试集,从而进行k次训练和测试,最终返回这k个测试结果的均值。

2.2.4 调参与最终模型
2.3 性能度量
性能度量:衡量模型泛化能力的评价标准
2.3.1 错误率与精度
分类任务中最常用的两种性能度量:错误率,精度
错误率:分类错误的样本数占样本总数的比例
精度:分类正确的样本数占样本总数的比例


2.3.2 查准率,查全率与F1
“查准率” (精确率 precision)
“查全率”(召回率 recall)
对于二分类问题,可以将样例根据其真实类别与学习器预测类别的组合划分为:
- 真正例(true positive):正例里面被预测为正例
- 假正例(false positive):反例里面被预测为正例
- 真反例(true negative):反例里面被预测为反例
- 假反例(false negative):正例里面被预测为反例
令 TP,FP,TN,FN 分别表示其对应的样例数,则有

精确率与召回率 的定义如下:


“平衡点”(Break-Event Point):精确率 == 召回率时的取值
但是 BEP 过于简化,更常用的是F1度量:

2.3.3 ROC 与 AUC
与P-R曲线类似,我们根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别作为横、纵坐标做图。
ROC曲线的的横轴为:假正例率 FP
ROC曲线的的纵轴为:真正例率 TP


2.3.4 代价敏感错误率与代价曲线
代价敏感错误率
不同类型的错误所造成的后果或者代价是不同的,代价敏感错误率是基于非均等代价的。二分类代价矩阵:costij表示将第i类样本预测为第j类样本的代价。一般说来,costii=0;若将第0类判别为第1类所造成的损失更大,则cost01> cost10;在非均等错误代价下,我们希望的是最小化“总体代价”,这样“代价敏感”的错误率为:

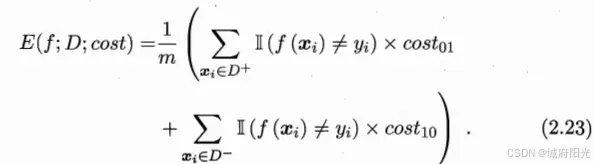
2.4 比较检验
使用某种实验评估方法测得学习器的某个性能度量结果,然后对这些结果进行比较。
是直接取得性能度量的值比“大小”吗?
实际上比较复杂,涉及到几个重要因素:
- 希望比较的是泛化能力。然而获得的是测试集上的性能,测试集也是样本,可能包括的不全;
- 测试集上的性能与测试集本身的选择有很大关系,且不论使用不同大小的测试集会得到不同的结果,(即使使用相同大小的测试集,若包含的测试样例不同,测试结果也会有不同)
- 机器学习算法本身具有一定的随机性,即便使用相同的参数设置在同一个测试集上多次运行,其结果也会有不同。


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









