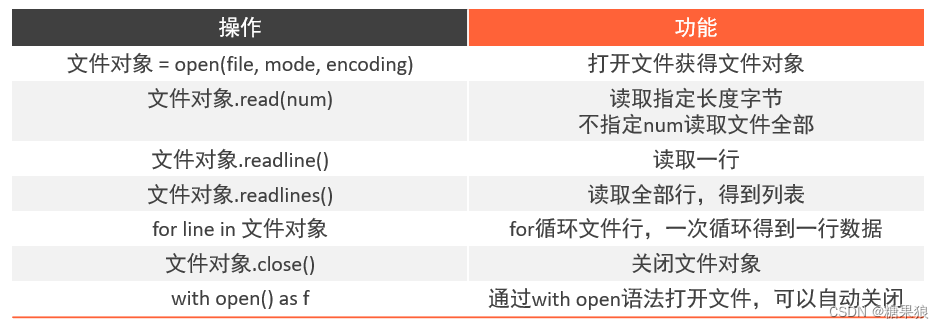
# 一、读取文件
# open(file, mode, encoding)
# mode: r w a
f = open("E:/jupyter/hwdata2a.csv", "r", encoding="UTF-8")
print(type(f))
print(f"读取10字节的结果:{f.read(10)}")
# 多次read,下一个read会在上一个之后接着读取
print(f"read方法读取全部内容的结果:{f.read()}")
# 读取全部行,封装到列表中
lines = f.readlines()
print(f"lines对象的类型是:{type(lines)}")
print(f"lines对象的类容是:{lines}")
# 每次读取一行
line1 = f.readline()
line2 = f.readline()
print(f"第一行内容是:{line1}")
print(f"第二行内容是:{line2}")
# for循环读取每一行
for line in f:
print(f"每一行数据是:{line}")
# 二、关闭文件
f.close()
# 读取完自动关闭文件
with open("E:/jupyter/hwdata2a.csv", "r", encoding="UTF-8") as f:
for line in f:
print(f"文件的每一行是:{line}")
# 案例:字符数量统计
# 方法一
f = open("C:/Users/LUO/Desktop/word.txt", "r", encoding="UTF-8")
content = f.read()
count = content.count("itheima")
print(f"itheima在文件中出现了:{count}次")
f.close()
# 方法二
f = open("C:/Users/LUO/Desktop/word.txt", "r", encoding="UTF-8")
count = 0
for line in f:
line = line.strip() # 去除开头结尾的空格以及换行符
words = line.split(" ")
print(words)
# 统计次数
for word in words:
if word == "itheima":
count += 1
print(f"itheima出现的次数是:{count}次")
f.close()







 本文详细介绍了如何使用Python进行文件的读取(包括一次性读取、按行读取和字符计数)、写入(包括覆盖写入和追加)以及一个文件操作的综合案例。
本文详细介绍了如何使用Python进行文件的读取(包括一次性读取、按行读取和字符计数)、写入(包括覆盖写入和追加)以及一个文件操作的综合案例。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









