







目录

机器学习
- 监督学习:有标签
回归 regression ——连续数值
分类 classification ——离散值 - 无监督学习:没有标签
聚类
鸡尾酒会算法
单变量线性回归
 代价函数 cost :平方误差函数 squared error —— 适用于线性回归
代价函数 cost :平方误差函数 squared error —— 适用于线性回归
梯度下降
往往局部最优,但单变量线性回归也是全局最优。


多变量线性回归

多元梯度下降


特征缩放
make sure features are on a similar scale
均值归一化 —— x0=1,其他约为0。
学习率 α
出现异常,一般需要调小α
正规方程
计算偏导为0除,不需要迭代计算,可以一步得到。
不需要特征缩放。
Θ
=
(
X
T
X
)
−
1
X
T
y
\Theta = (X^TX)^{-1}X^Ty
Θ=(XTX)−1XTy
(XTX)不可逆
原因:有重复的特征;特征太多,多于数据量。
Octave:pinv(X'*X)*X'*y

Octave
CLI 命令行
% 注释
^ 次幂 .^ 元素次幂 * .*
~= 不等于 false 0;true 1
disp 屏幕打印 sprintf 输出
format long format short
ones() zeros() rand() randn() eye() 单位矩阵 magic() 幻方矩阵
size() length()
load 加载数据 save 命名 变量 保存文件
who 所有变量 whos 详细信息 clear 清除缓存变量
A(:) 把矩阵A变成一个列向量
log() exp() abs()
max() 每一列的最大值
find()
sum() prod()
floor() 向下取整 ceil() 向上取整
flipud() 垂直翻转
A' 转置
pinv() 逆
hist 直方图
plot() hold on 在同一张图上画图
print -dpng 'name'
figure(n);plot() 同时画n张图
subplot() 子图
xlabel() ylabel() legend() title() axis()
imagesc(A) 将矩阵A可视化 colorbar colormap gray
for i=1:10 XXXX end
while XXXX end
break continue
if XXXX elseif XXXX else XXXX end
function [返回值1, 返回值2] = 函数名(变量1, 变量2)
向量化计算
logistic regression——分类算法
Sigmoid/Logistic function
函数意义:某个输入情况下,得到的输出为1的概率
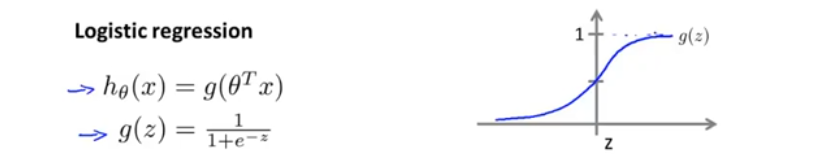
决策界限
代价函数

梯度下降

高级优化

多元分类
将某些类别合并,与另一个类别进行分类。多次操作。
正则化
过拟合

代价函数

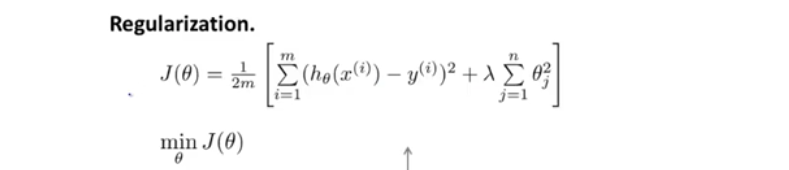
线性回归
梯度下降

正规方程
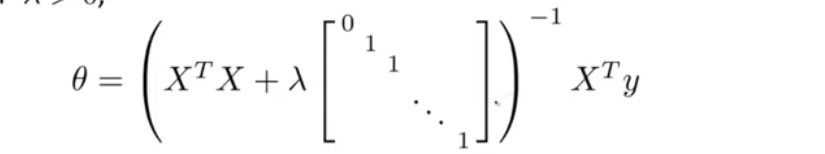
logistic 回归
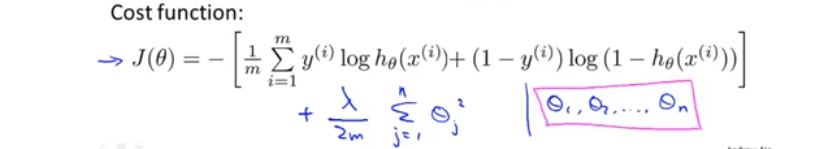

神经网络学习
解决非线性问题
 例子:改变权重θ可以实现 AND OR NOT XNOR 等功能
例子:改变权重θ可以实现 AND OR NOT XNOR 等功能
 多元分类
多元分类
神经网络参数的反向传播算法
二元分类:一个输出单元
多元分类:多个输出单元
代价函数

反向传播算法



展开参数
梯度检测

随机初始化
权重矩阵随机初始化,打破对称性。
组合到一起
- 选择神经网络结构

- 训练神经网络


应用机器学习的建议
- 评估假设
- 训练集、验证集(模型选择)、测试集(6:2:2)
- 偏差(欠拟合):训练集误差大,验证集误差也大
方差(过拟合):训练集误差小,但验证集误差大

- 正则化:λ小(高方差、过拟合),λ大(高偏差、欠拟合)

- 学习曲线:样本数量为横轴,画训练集和验证集的误差曲线。


- 改进方法:

机器学习系统设计
- 执行优先级:先进行一次简单快速的实现,画出学习曲线,再决定优化方向。
- 误差分析:交叉验证集
- 不对称性分类的误差评估:

- 精确度和召回率的权衡:F值
- 机器学习数据
支持向量机
- 优化目标


- 大间隔分类:C非常大的时候
- 核函数:相似度函数

- 使用SVM:使用已有软件库。

无监督学习
- 无监督学习:不带标签——聚类算法。
- K-Means:遍历样本,进行分类;移动中心。
- 优化目标:距离平均值。
- 随机初始化:K<m
- 选取聚类数量:根据后续目的。
降维
- 无监督学习。
- 目标:数据压缩;可视化。
- 主成分分析PCA:最小化投影距离和。
预处理:均值归一化;特征值缩放。
奇异值分解SVD - 应用PCA的建议:只在训练集上运用;不建议用来防止过拟合;原数据效果不好时再考虑PCA。
异常检测
- 选择特征;计算参数;对比新数据。
- 对数据进行变换,使其类似高斯分布。
- 多变量高斯分布。
推荐系统
- 基于内容的推荐算法
- 协同过滤算法
大规模机器学习
- 批梯度下降(原始方法):遍历所有数据求和,每次需要所有样本。
- 随机梯度下降:先打乱顺序,遍历过程中优化,每次只考虑一个样本。
- Mini-Batch梯度下降:每次b个样本。

- 在线学习。
- 减少映射与数据并行。















 4011
4011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









