







前言
【2024/6/3】2号花了一天时间训练了200张图片,搞了个元件检测的数据集合。于是加入了调用检测视频的指令。但是识别视频的过程不能调用出来,我很不满意。
训练步骤总结
总的来说 YOLO安装就是四个步骤
1、环境安装
2、数据集制作
3、训练模型
4、预测图片
一、环境安装
去github下载大佬的文件或者用
git clone xxx
GitHub中文站真的是个好东西啊~!

查看GPU有没有
查看自己的电脑的电脑是不是支持GPU
(该指令仅适用于 NVIDIA 的GPU)
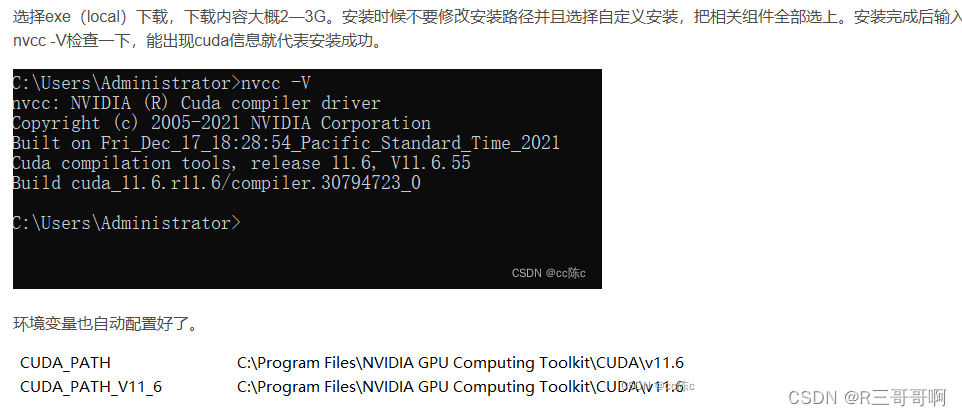
nvidia-smi
是11.2版本的

顺便一提,CPU跑起来真的太费劲了,我之前训练的模型,只有20张图片,跑起来CPU直接拉满 ,时刻担心蓝屏警告 ~ O ~
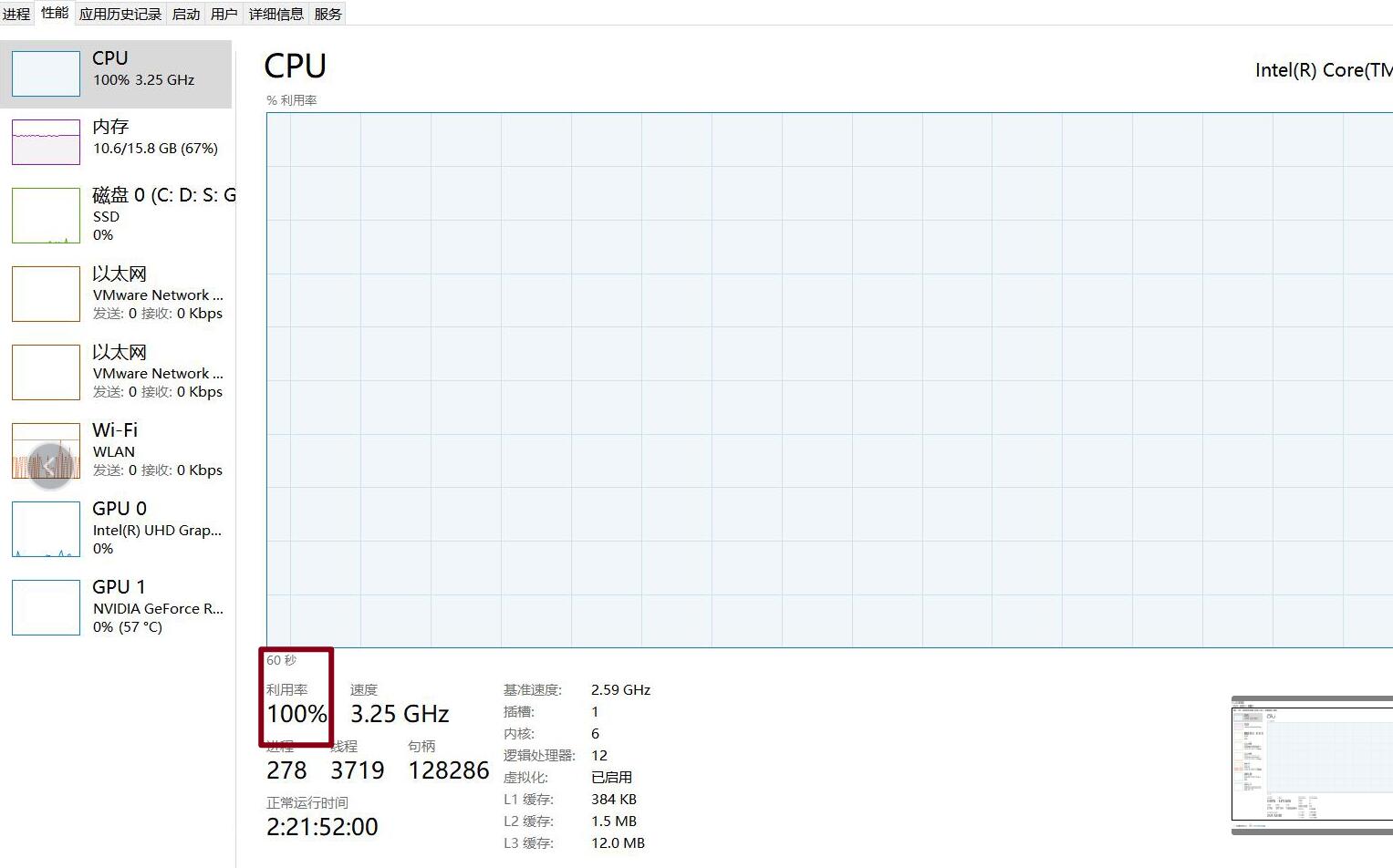
所以各位,如果可以还是GPU吧!
小步骤
conda安装
首先,在conda创建环境.
conda create -n toyolo2 python==3.9
创建好,进入
conda activate toyolo2

下载PyTorch
这一步蜜汁步骤就是为了证明,CUDA官网给的版本是要求的最低版本
我这里下载了个CUDA 11.3的
# CUDA 11.3
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
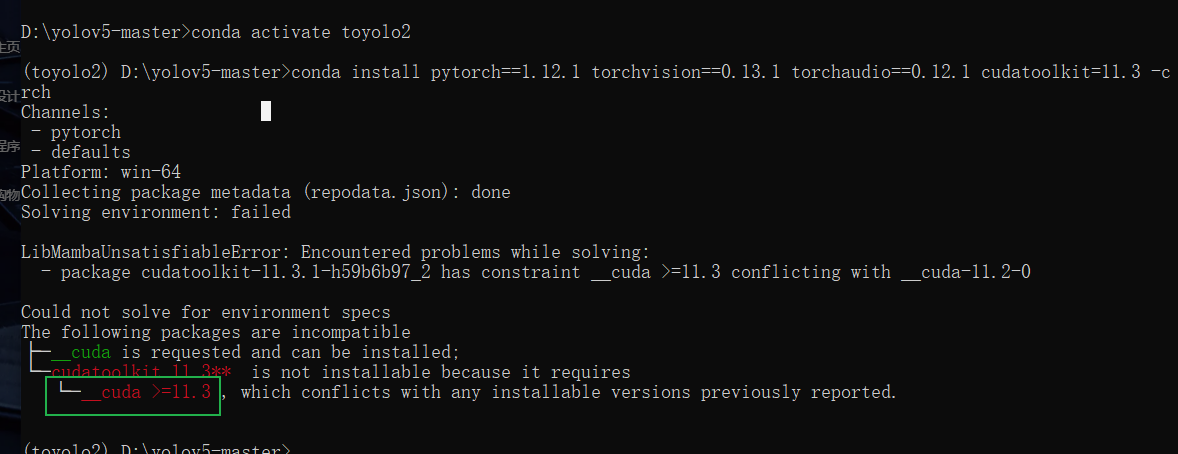
显示是错误的,看来列出的版本是最低需求的。
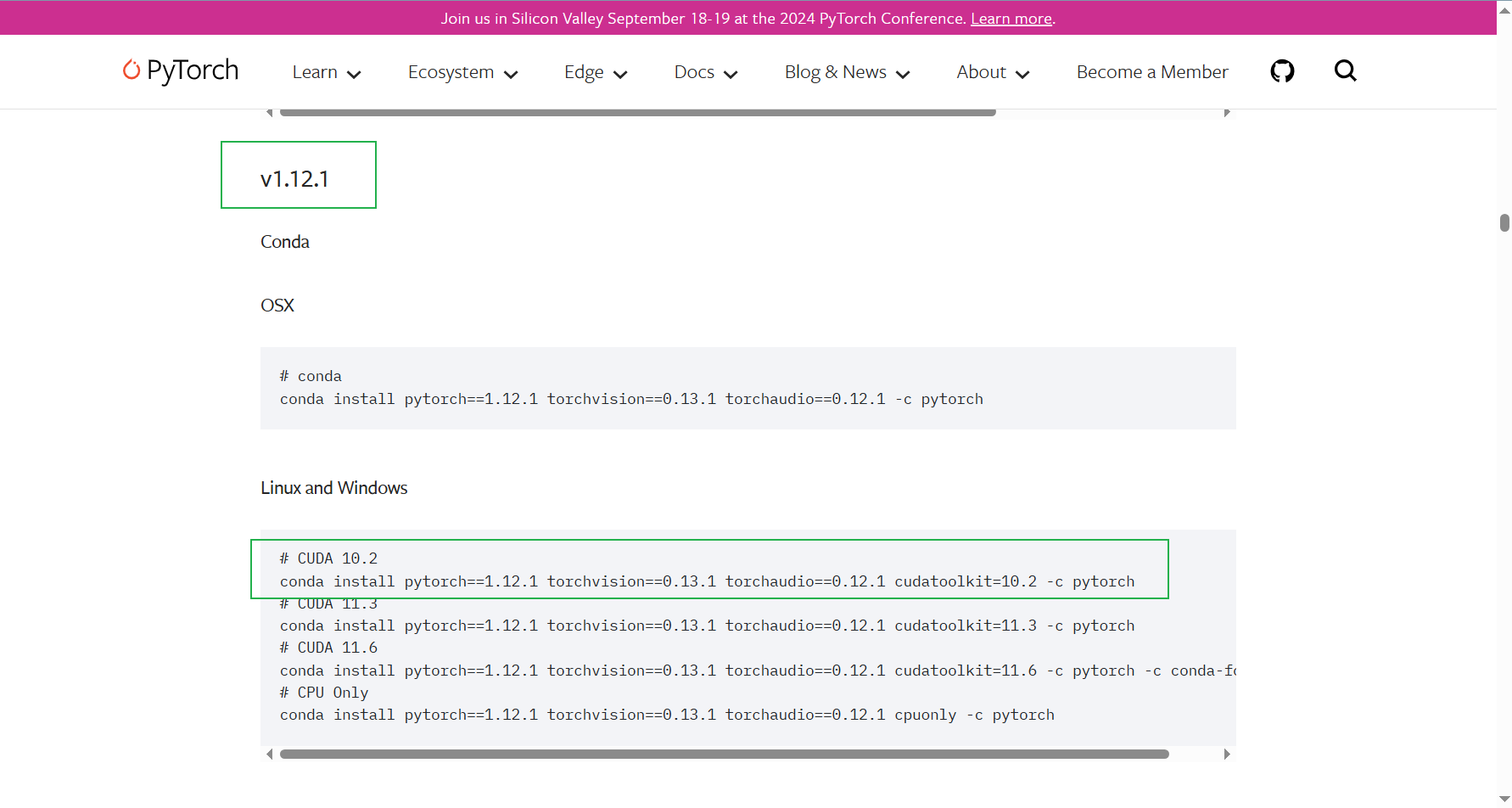
换这个
# CUDA 10.2
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=10.2 -c pytorch
一眨眼的功夫就成功了。
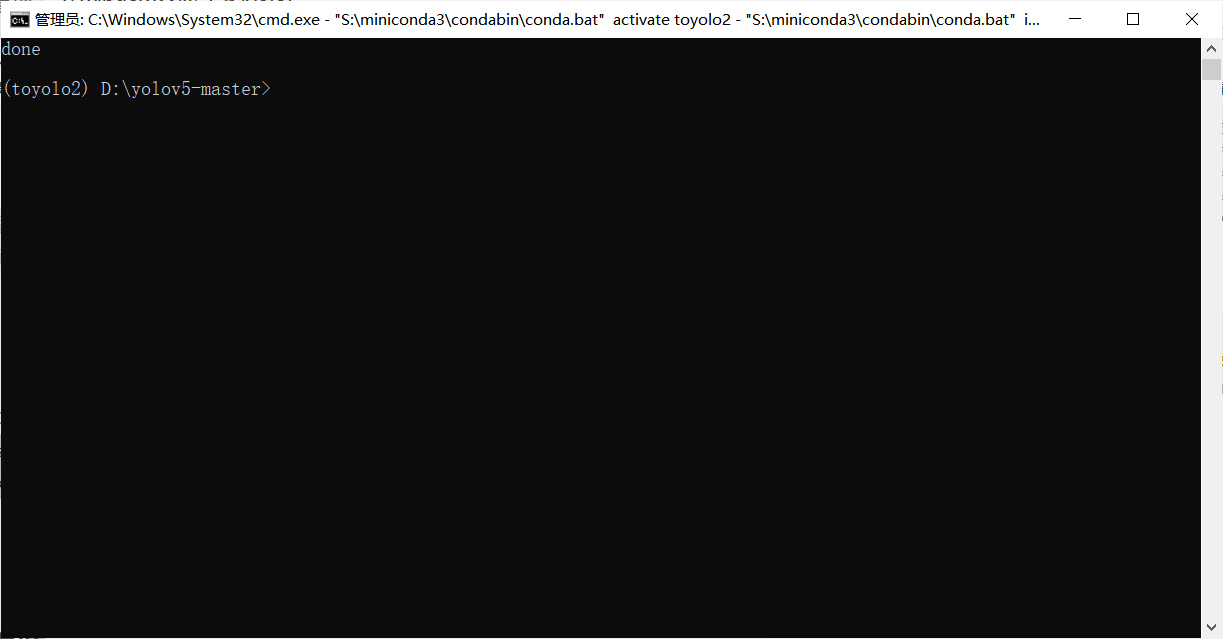
安装新环境的依赖,就是yolo5-master文件夹下的requirements.txt里面的指令。
pip install -r requirements.txt
可以加镜像
pip install -r requirements.txt -i http://mirrors.ustc.edu.cn/
但是加镜像源有时候会缺少各种包,没事多跑几遍不加镜像的就行了。总之缺少安啥,全部装完就行了。
预测图片
python detect.py --source ./data/images/bus.jpg
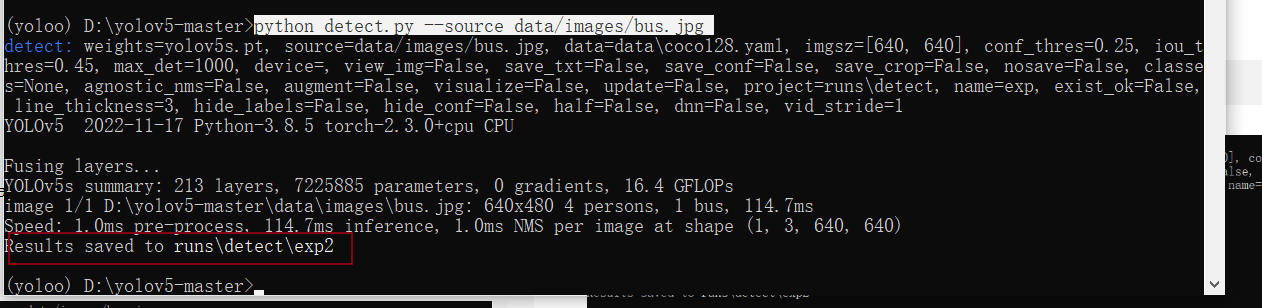

正常!
改变赛道,安装GPU版本
------2024/5/28更新,当然不行啦
因为我的GPU环境都没有激活。
# 首先进入环境
验证 PyTorch是否安装成功
打开Anaconda prompt命令窗口,激活环境,输入python,进入python开发环境中
>> import torch
>> torch.cuda.is_available()
# 如果安装成功
>> True
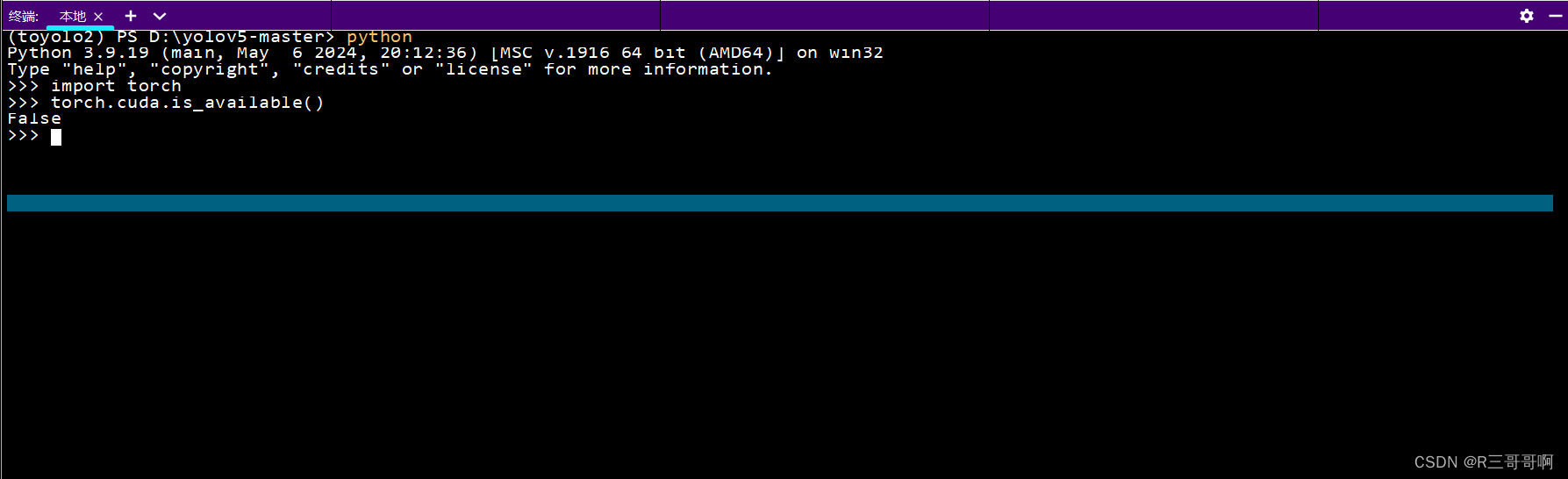
我这里查看是没有安装各种环境的【就是CUDA+CUdnn之类的】
完整指令
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.cuda.device_count())
太不容易了,终于把GPU版本的环境配置好了。花了一天时间专门配置环境。

主要参考还是B站安装的环境的阿胎教版本老师QAQ
但是这个老师有一个做法很迷惑,也不能这么说,就是太麻烦了。他的CUDA安装到后面建立了好几个文件夹,这种就需要自己修改环境变量了。(没错,鄙人卡死过一段时间)
后面我的解决办法就是,不修改地址了,就安装在默认地址,他就会自动识别出来环境变量。最多要做的就是按照,在不成功的情况下,再按照别的博主推荐的办法添加环境变量。
如果被环境变量卡,就看这个博文==》YOLOV8从环境部署(GPU版本)到模型训练——专为小白设计一看就懂
这篇博文我觉得非常可以==》yolov5,如何使用CPU/GPU运行——安装环境及依赖(详细,简单易懂)
-------------------------------------
我总结一下安装GPU版本的步骤:
1、首先检查自己的电脑是否支持
2、安装CUDA(对照自己的版本)
3、安装CUdnn(这个一定要登入才能下载,不然就是撞墙!!!我之前博文的时候,好多博主都有说,但我直接无视了。卡壳好久!!!!!!!)
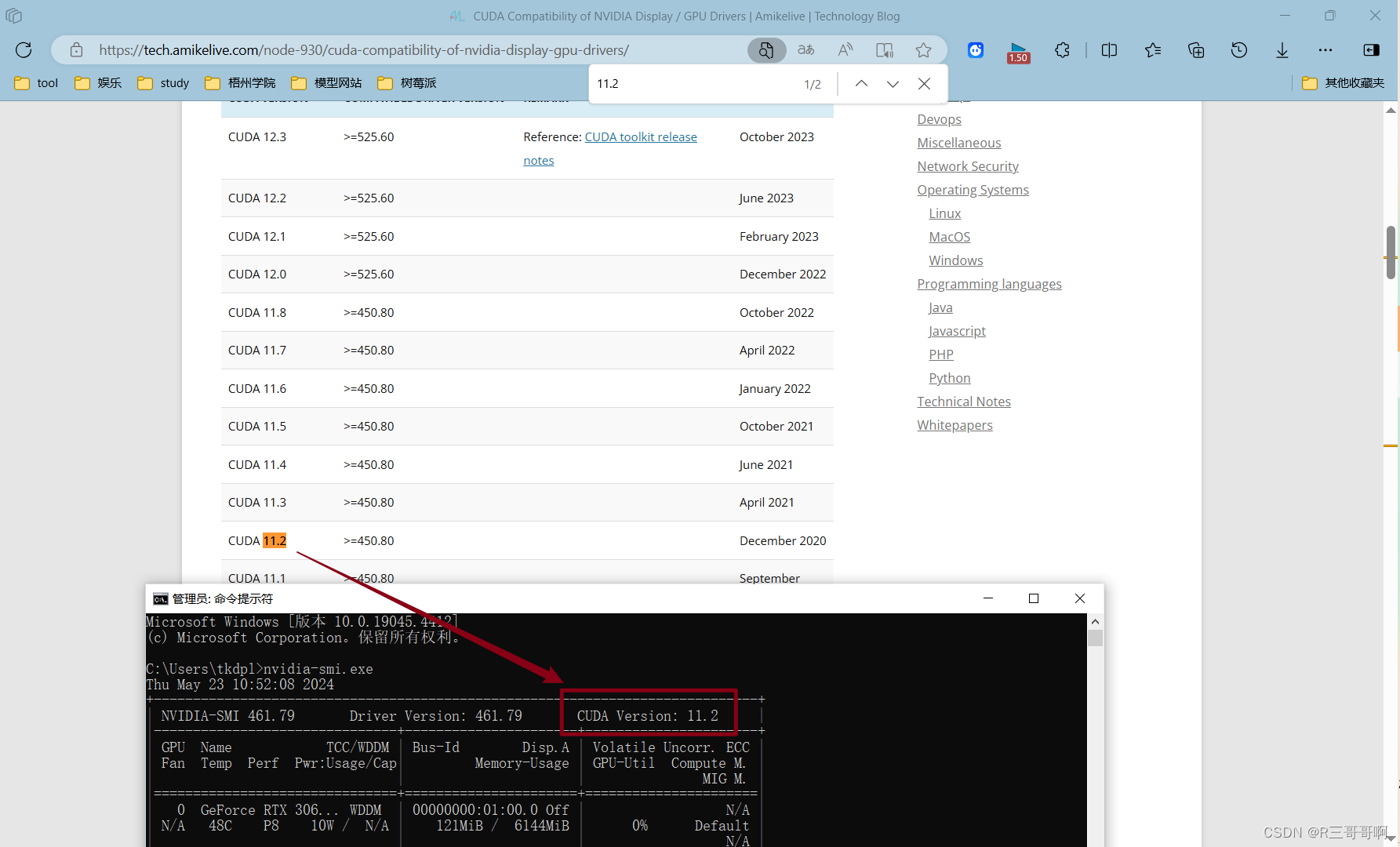
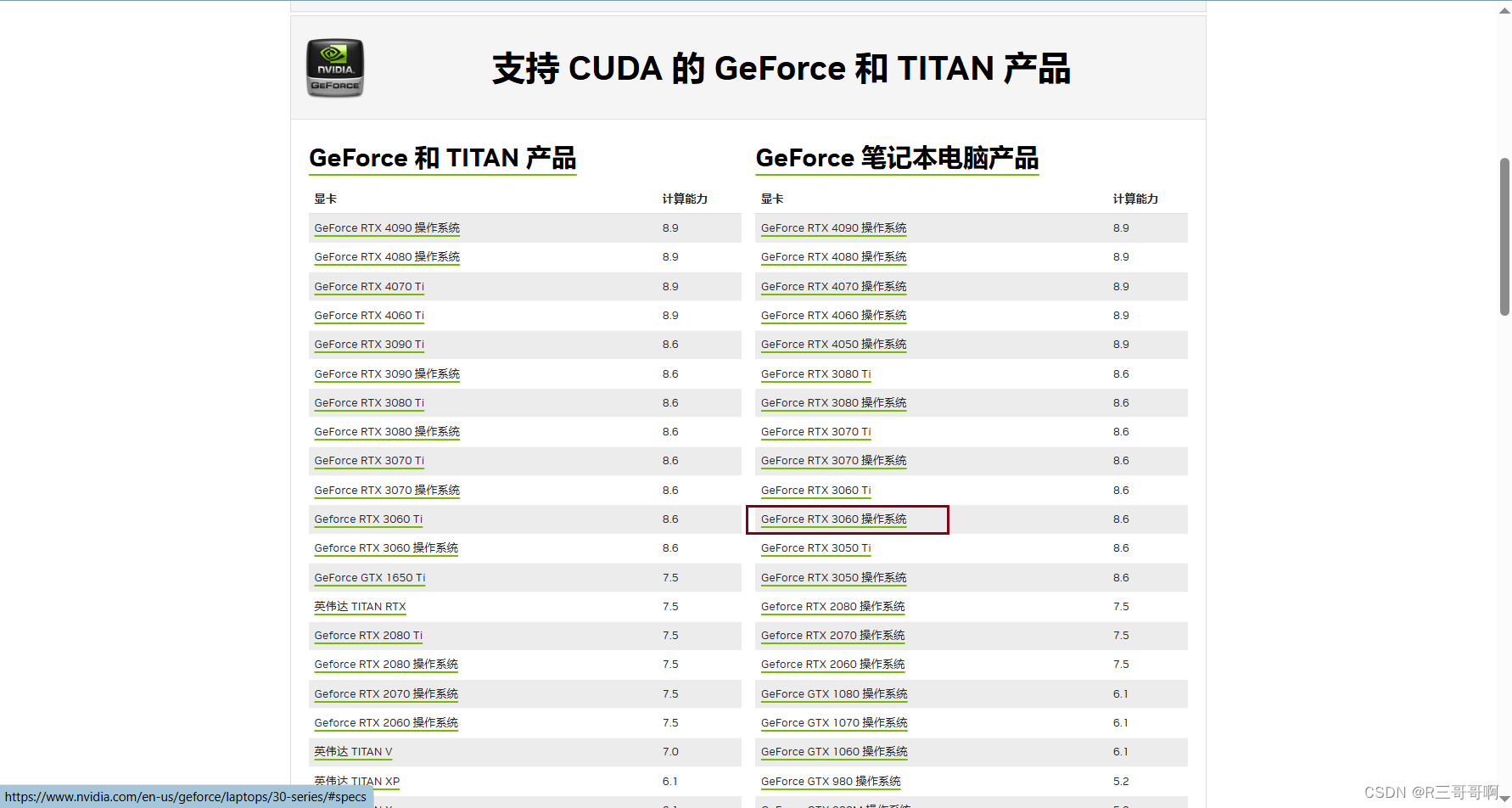
4、安装pytorch,这个我也说不准,因为我的CUDA是很罕见的11.2,所以意味着我最高标准是11.1(因为没有11.2),但是我11.1安装不上,于是试了好几个再11.0吧安装成功了。
--------------------------------------
于是就按照网上的博文继续安装咯
YOLOv5 gpu 训练自定义模型 训练
CUDA安装
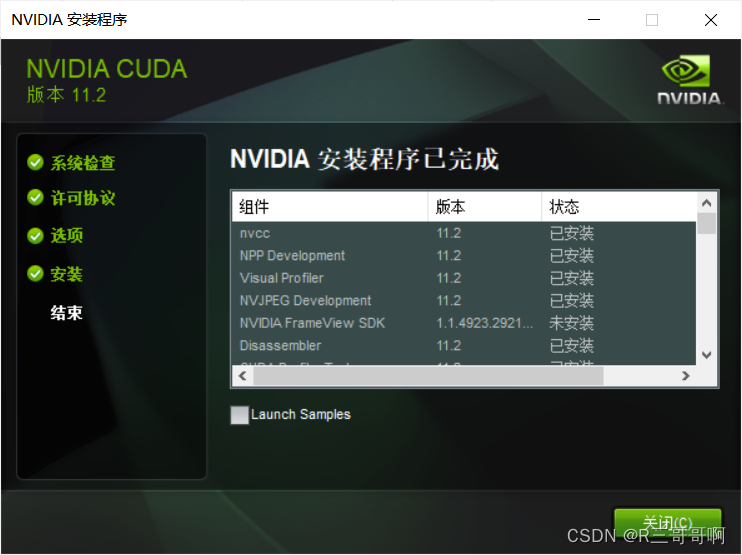
安装结束的画面。
二、数据集制作
标注数据,labelimg标注
创建目标文件夹
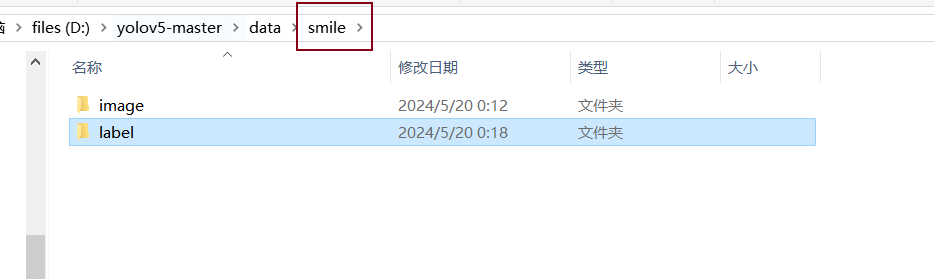
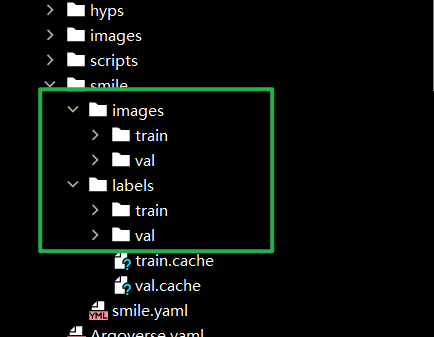
分类好,如果需要标签和图片分开,你的yaml文件就需要重新加点东西!!!!!!!

进行标注(又回到赛博民工的日子了)
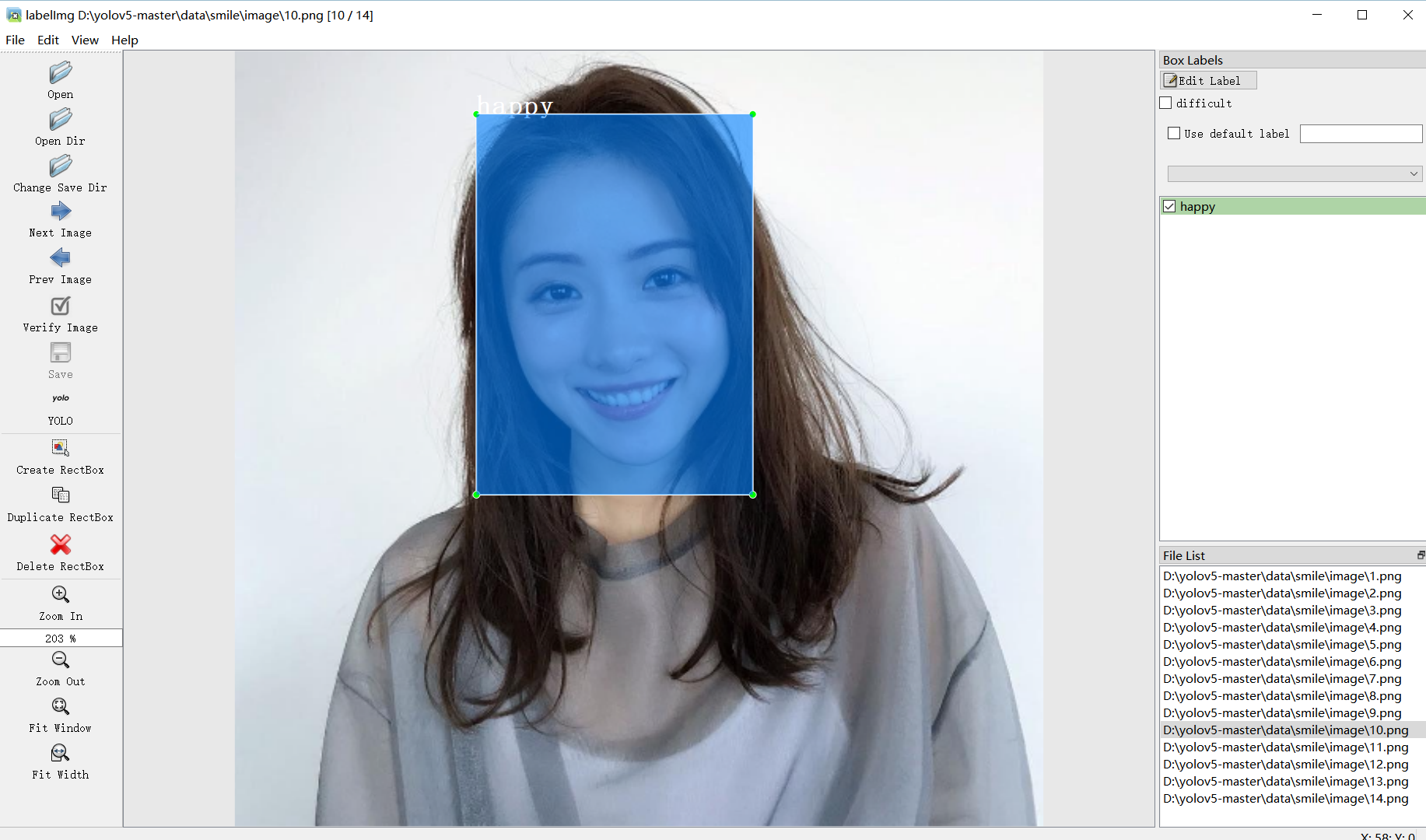
注意是这个格式
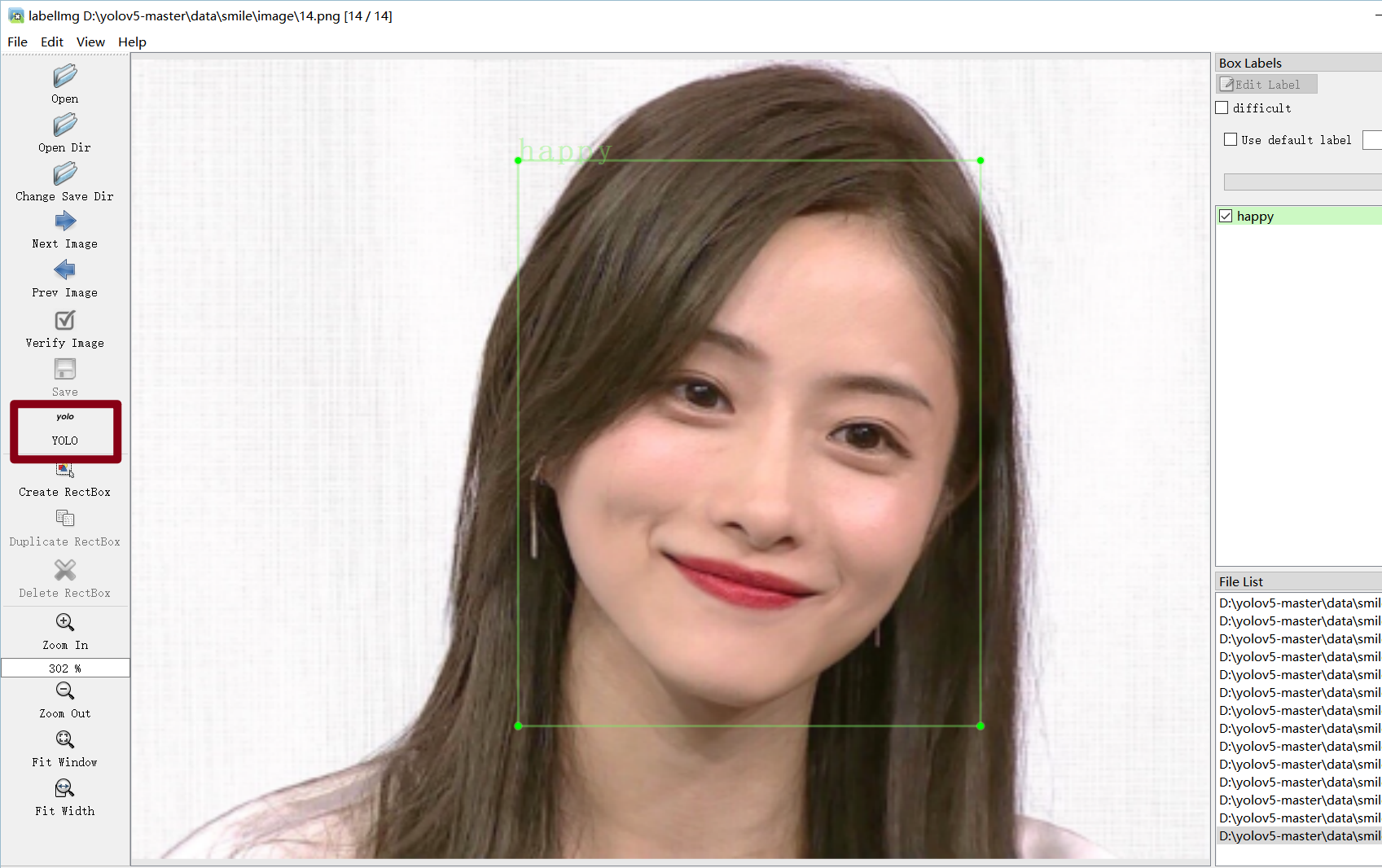
最终在label文件夹下会生成这些信息
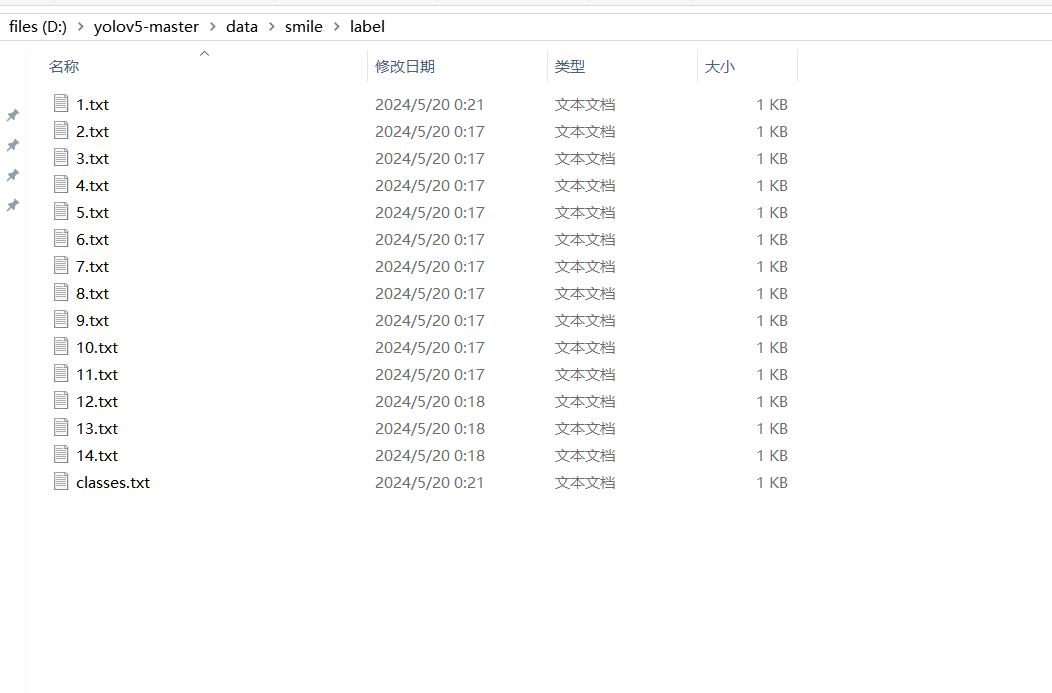
classes会展示你的标注信息
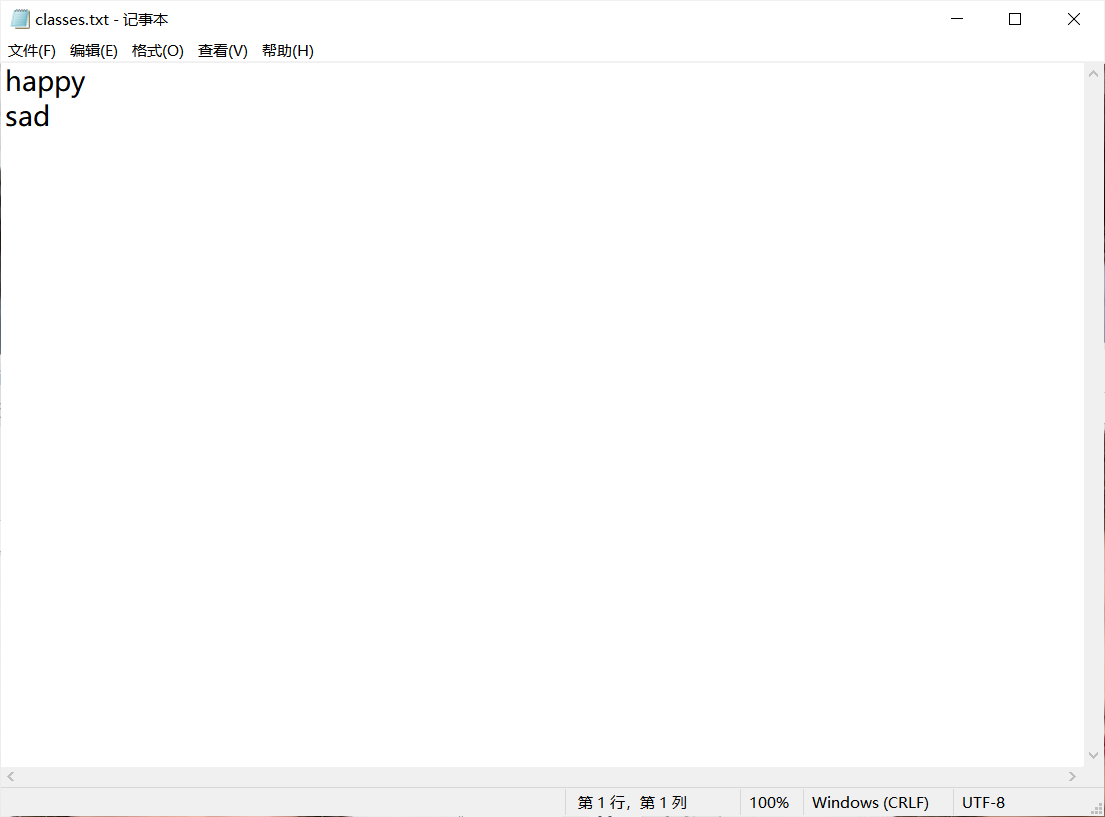
在代码中指定数据集路径

修改后
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/yolov5-master/data/smile # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: # test images (optional)
# Add this line to specify the directory of your label files
labels: labels # label files directory (relative to 'path')
# Classes
nc: 2 # number of classes
names: ['happy', 'sad'] # class names
三、训练模型
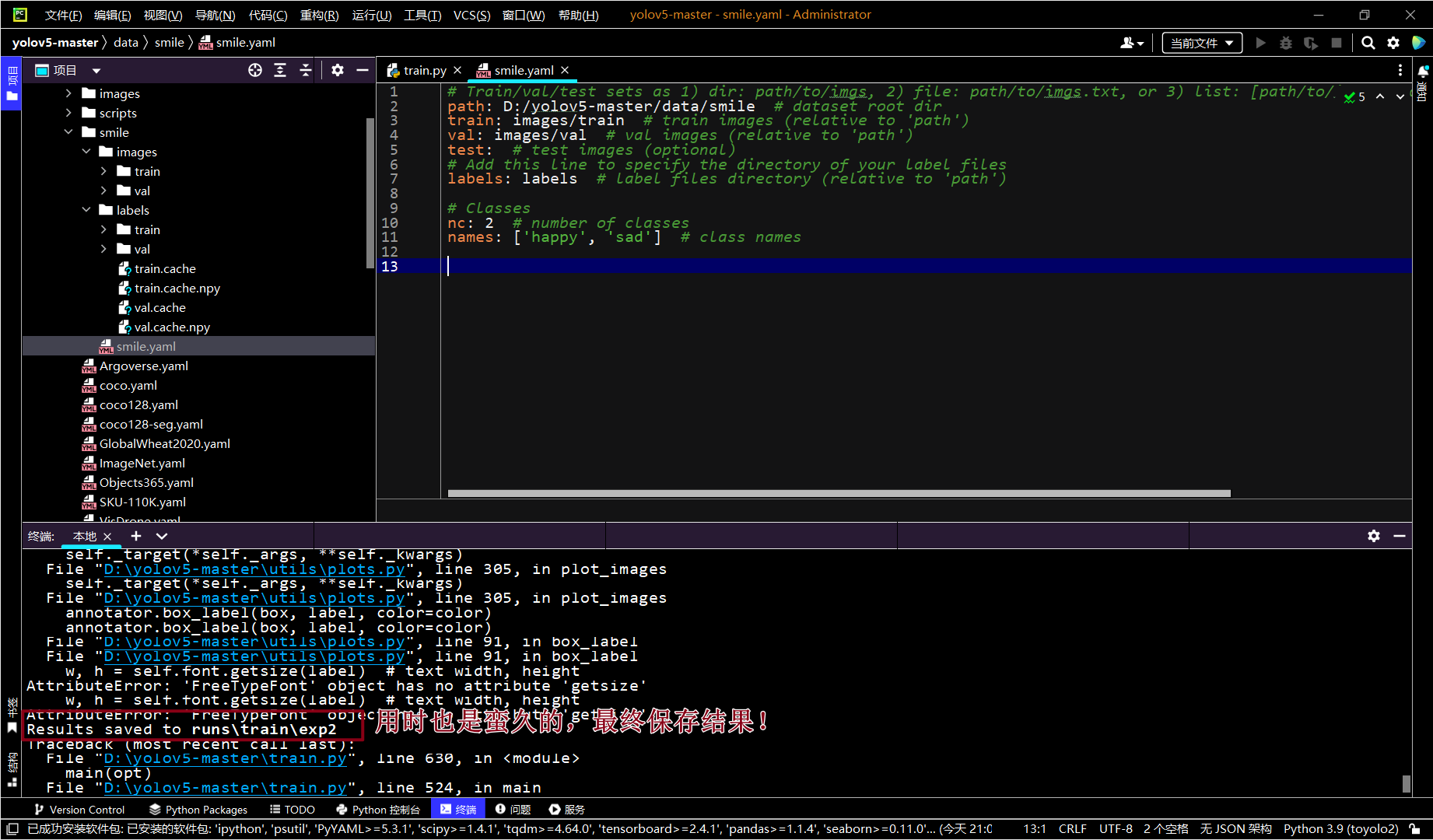
暂时不使用修改源代码的方法,用指令传参数。
python train.py --weights yolov5s.pt --data data/smile/smile.yaml --workers 4 --batch-size 20 --epochs 100
多bb一句,我之前因为smile打错成simle错了好久!!!!!!!!!!
GPU
python train.py --weights yolov5s.pt --data data/smile/smile.yaml --workers 4 --batch-size 20 --epochs 100 --device 0
好像差不多,cpu爆哭
四、测试最终训练结果
这里选用开摄像头的方法
python detect.py --weights runs/train/exp/weights/best.pt --source 0
如果需要打开视频
python detect.py --weights runs/train/exp/weights/best.pt --source D:/yolov5-master/data/Polarity/test/test.mp4
这条指令会在后台执行,默默的识别完保存。
我觉得我的训练结果一般QAQ,可能30张图片还是太少了。
这么说,确实太少了
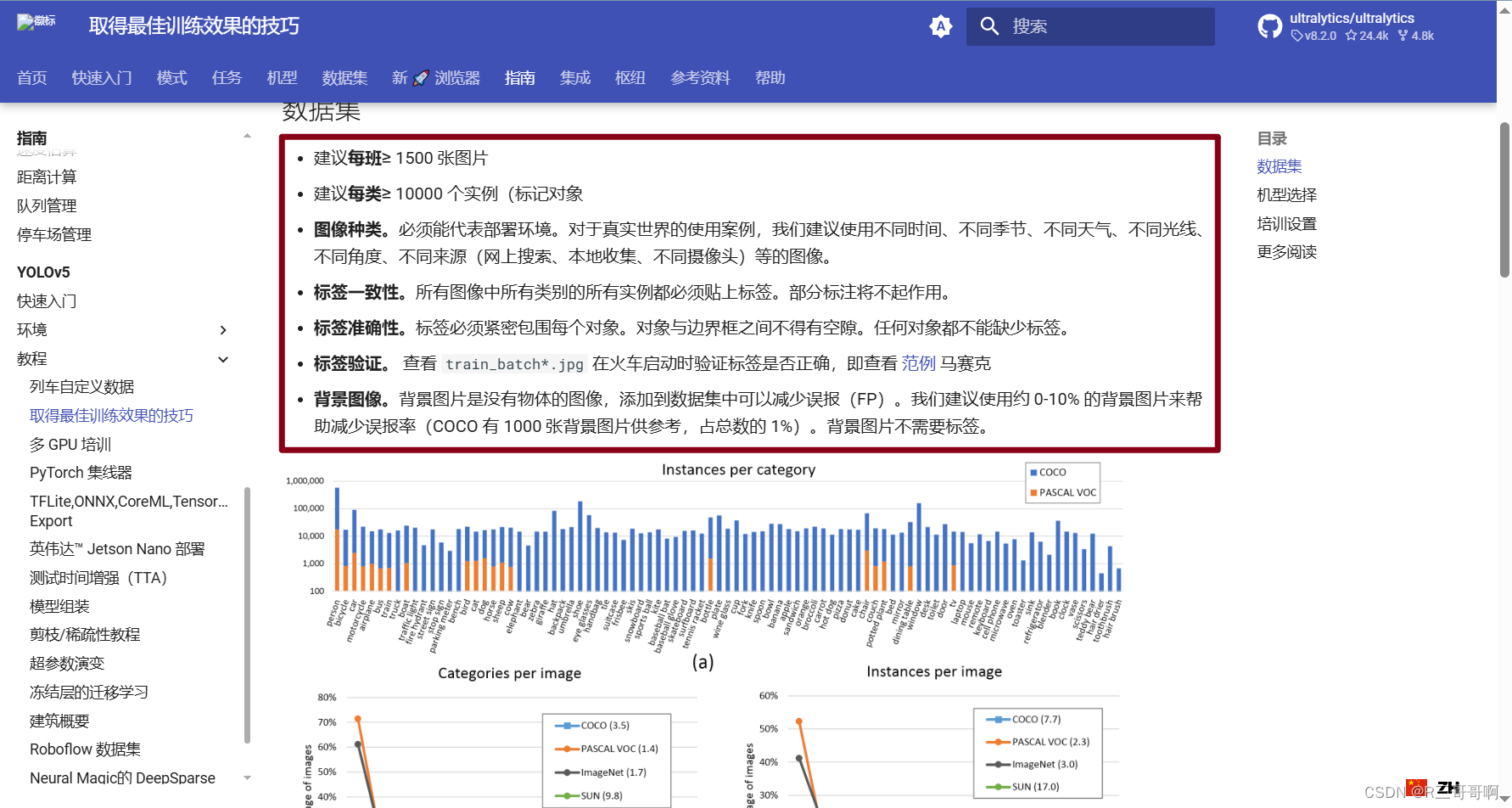
取得最佳训练效果的技巧
总结
这篇文章依旧没有总结















 2007
2007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









