






一.AlexNet网络结构
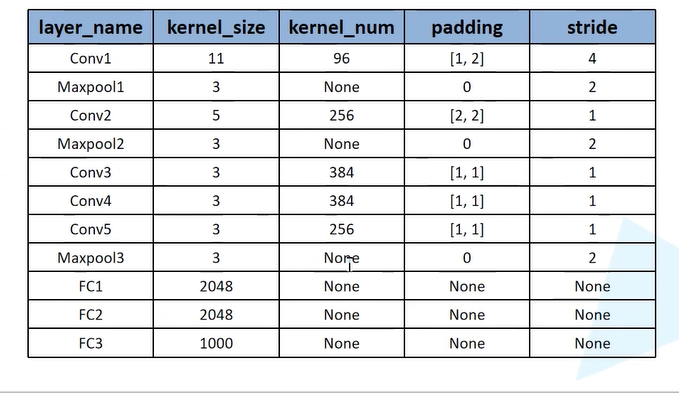

该网络之所以上下两层是因为采用了两个GPU进行训练,上下层分别代表两个GPU的训练过程,使用两个GPU同时进行训练可以大大提高训练速度。为了容易理解,下面我们只看其中一层网络。
Cov1
输入为224×224×3的图像,卷积核的数量为96,论文中两片GPU分别计算48个卷积核; 卷积核的大小为 11 × 11 × 3 ;stride = 4, stride表示的是步长, padding = [1,2], 表示;
卷积后的图形大小是怎样的呢?
wide = (224 + 2 * padding - kernel_size) / stride + 1 = 55
height = (224 + 2 * padding - kernel_size) / stride + 1 = 55
channel=48
Maxpool1
输入55×55×48的图像;kenel_size=3×3×48;stride=2
池化后的图形大小
wide = (55 + 2 * padding - kernel_size) / stride + 1 = (55+2×0-3)/2+1=27
height = (55 + 2 * padding - kernel_size) / stride + 1 = (55+2×0-3)/2+1=27
channel=128
如图所示,以此类推出,最后一个全连接层输出的结果为1000个种类

二.AlexNet亮点
(1).该网络首先使用GPU进行网络加速训练。
(2).使用Relu激活函数,而不是传统的sigmoid激活函数以及Tanh激活函数。
(3).使用LRN局部响应归一化。
(4).在全连接层的前两层中使用Dropout随机失活神经元操作,以减少过拟合。
三.激活函数
1.Relu激活函数
Relu函数公式:f(x)=max(0,x)
函数图像

函数特点:自变量小于0时,函数值为0,自变量大于等于0时,函数值为自变量的值。
2.sigmoid激活函数
函数公式
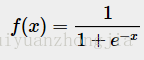
函数图像
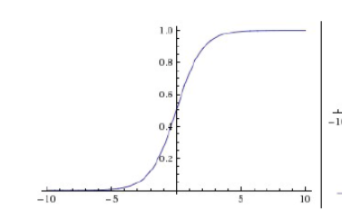
函数特点
x趋向于负无穷时,函数值趋向于0;x趋向于正无穷时,函数值趋向于1。
函数缺点
sigmoid 有一个非常致命的缺点,当输入非常大或者非常小的时候(saturation),这些神经元的梯度是接近于0的,从图中可以看出梯度的趋势。所以,你需要尤其注意参数的初始值来尽量避免saturation的情况。如果你的初始值很大的话,大部分神经元可能都会处在saturation的状态而把gradient kill掉,这会导致网络变的很难学习。
3.Tanh激活函数
函数公式
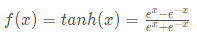
函数图像
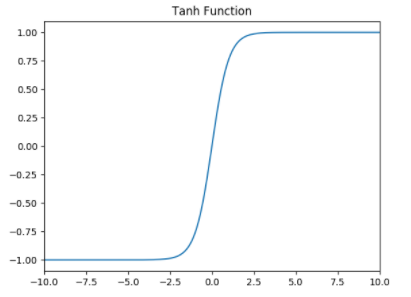
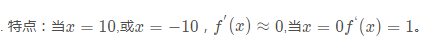
tanh函数是非常优秀的,几乎适合所有场合。
4.Relu与sigmoid和Tanh相比优缺点
优点:
1)克服梯度消失的问题
2)加快训练速度
注:正因为克服了梯度消失问题,训练才会快
缺点:
1)输入负数,则完全不激活,ReLU函数死掉。
2)ReLU函数输出要么是0,要么是正数,也就是ReLU函数不是以0为中心的函数
深度学习中最大的问题是梯度消失问题,使用tanh、sigmod等饱和激活函数情况下特别严重(神经网络在进行方向误差传播时,各个层都要乘以激活函数的一阶导数,梯度每传递一层就会衰减一层,网络层数较多时,梯度G就会不停衰减直到消失),使得训练网络收敛越来越慢,而ReLU函数凭借其线性、非饱和的形式,训练速度则快很多。
5.激活函数的选择
选择一个适合的激活函数并不容易,需要考虑很多因素,通常的做法是,如果不确定哪一个激活函数效果更好,可以把它们都试试,然后在验证集或者测试集上进行评价。然后看哪一种表现的更好,就去使用它。以下是常见的选择情况:
(1)如果输出是 0、1 值(二分类问题),则输出层选择 sigmoid 函数,然后其它的所有单元都选择 Relu 函数。
(2)如果在隐藏层上不确定使用哪个激活函数,那么通常会使用 Relu 激活函数。有时,也会使用 tanh 激活函数,但 Relu 的一个优点是:当是负值的时候,导数等于 0。
(3)sigmoid 激活函数:除了输出层是一个二分类问题基本不会用它。
(4)tanh 激活函数:tanh 是非常优秀的,几乎适合所有场合。
(5)ReLu 激活函数:最常用的默认函数,如果不确定用哪个激活函数,就使用 ReLu 或者 Leaky ReLu,再去尝试其他的激活函数。
四.局部响应归一化(LRN:Local Response Normalization)
局部响应归一化(LRN:Local Response Normalization)
在神经网络中,我们用激活函数将神经元的输出做一个非线性映射,但是tanh和sigmoid这些传统的激活函数的值域都是有范围的,但是ReLU激活函数得到的值域没有一个区间,所以要对ReLU得到的结果进行归一化。
五.dropout减少过拟合
1.什么是过拟合
过拟合是训练得到的模型可以完美的预测训练集,但对于测试集的预测结果较差。
过度拟合训练数据,没有考虑模型的泛化能力。
2.导致过拟合的原因
导致过拟合的根本原因是,特征维度过多,模型假设过于复杂,参数过多,训练数据较少,噪声过多。
3.如何解决过拟合
全连接层的前两层使用dropout以减少过拟合现象
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









