







目录
前言
一、常用Map
1.1 Map
Map是一个键值对的接口:
public interface Map<K, V> {
以键值对的方式存储元素,所有Map集合的Key是不可重复的,key和value都是引用数据类型,存的都是内存的地址。
Map集合的实现类主要为HashMap、TreeMap、LinkedHashMap等。
1.1.1 特点
Map集合的特点:
1.Map集合是一个双列集合,一个元素包含两个值(一个key,一个value)
2.Map集合中的元素,key和value的数据类型可以相同也可以不同
3.Map集合中的元素,key是不允许重复的,value是可以重复的
4.Map集合中的元素,key和value是一 一对应的
1.2 HashMap
HashMap<K,V>集合implements Map<K,V>接口, 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,不支持线程同步。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
1.2.1 特点
HashMap 的特点:
1.集合底层是哈希表,查询速度特别快
2. 数据结构:
jdk1.8之前:数组+单向链表
jdk1.8之后,数组+单向链表/红黑树(长度超过8位)提高查询的速度
3.无序不可重复
适用场景:
基于哈希表实现,具有快速的查找和插入操作,适用于需要快速查找键值对的场景。
1.2.2 使用
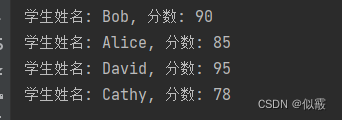
public static void test1() {
// 创建一个HashMap实例,键为学生姓名(String),值为分数(Integer)
Map<String, Integer> studentScores = new HashMap<>();
// 添加学生姓名和分数到HashMap
studentScores.put("Alice", 85);
studentScores.put("Bob", 90);
studentScores.put("Cathy", 78);
studentScores.put("David", 95);
// 遍历HashMap并打印每个学生的姓名和分数
for (Map.Entry<String, Integer> entry : studentScores.entrySet()) {
String studentName = entry.getKey();
int score = entry.getValue();
System.out.println("学生姓名: " + studentName + ", 分数: " + score);
}
}
输出:
常用API
| api | 作用描述 |
|---|---|
| clear() | 删除 hashMap 中的所有键/值对 |
| clone() | 复制一份 hashMap |
| isEmpty() | 判断 hashMap 是否为空 |
| size() | 计算 hashMap 中键/值对的数量 |
| put() | 将键/值对添加到 hashMap 中 |
| putAll() | 将所有键/值对添加到 hashMap 中 |
| putIfAbsent() | 如果 hashMap 中不存在指定的键,则将指定的键/值对插入到 hashMap 中。 |
| remove() | 删除 hashMap 中指定键 key 的映射关系 |
| containsKey() | 检查 hashMap 中是否存在指定的 key 对应的映射关系。 |
| containsValue() | 检查 hashMap 中是否存在指定的 value 对应的映射关系。 |
| replace() | 替换 hashMap 中是指定的 key 对应的 value。 |
| replaceAll() | 将 hashMap 中的所有映射关系替换成给定的函数所执行的结果。 |
| get() | 获取指定 key 对应对 value |
| getOrDefault() | 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值 |
| forEach() | 对 hashMap 中的每个映射执行指定的操作。 |
| entrySet() | 返回 hashMap 中所有映射项的集合集合视图。 |
| keySet() | 返回 hashMap 中所有 key 组成的集合视图。 |
| values() | 返回 hashMap 中存在的所有 value 值。 |
| merge() | 添加键值对到 hashMap 中 |
| compute() | 对 hashMap 中指定 key 的值进行重新计算 |
| computeIfAbsent() | 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hasMap 中 |
| computeIfPresent() | 对 hashMap 中指定 key 的值进行重新计算,前提是该 key 存在于 hashMap 中。 |
1.3 TreeMap
TreeMap是Map接口的另一个常见实现类,它基于红黑树实现,可以对键进行排序,并提供了一系列与排序相关的方法。
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
1.3.1 特点
TreeMap的特点:
1.TreeMap集合默认会对键进行排序,所以键必须实现自然排序和定制排序中的一种
2.底层使用的数据结构是二叉树
适用场景:
基于红黑树实现,可以对键进行排序,并提供了一系列与排序相关的方法,适用于需要对键进行排序的场景。
1.3.2 使用
TreeMap<String, Integer> scores = new TreeMap<>();
scores.put("Alice", 90);
scores.put("Bob", 80);
scores.put("Charlie", 95);
System.out.println("Scores: " + scores);
scores.remove("Bob");
System.out.println("Scores after removal: " + scores);
int aliceScore = scores.get("Alice");
System.out.println("Alice's score: " + aliceScore);
String firstKey = scores.firstKey();
String lastKey = scores.lastKey();
System.out.println("First key: " + firstKey);
System.out.println("Last key: " + lastKey);
输出:
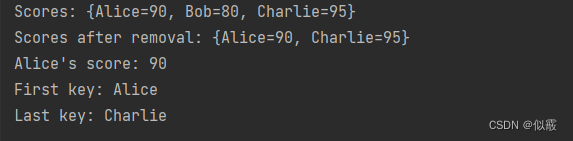
这段代码展示了TreeMap的特点,它会按照键的自然顺序(或自定义的比较器)对键进行排序存储。通过TreeMap,可以快速找到最小键和最大键,以及执行按键排序的操作。
常用API
| api | 作用描述 |
|---|---|
| put(K key, V value) | 将指定的键值对添加到TreeMap中。 |
| remove(Object key) | 从TreeMap中移除指定键的键值对。 |
| get(Object key) | 返回指定键对应的值。 |
| containsKey(Object key) | 检查TreeMap中是否包含指定的键。 |
| size() | 返回TreeMap中键值对的数量。 |
| firstKey() | 返回TreeMap中的第一个键。 |
| lastKey() | 返回TreeMap中的最后一个键。 |
1.4 LinkedHashMap
LinkedHashMap<K,V> extends HashMap<K,V> ,大多数情况下,只要不涉及线程安全问题,Map基本都可以使用HashMap,不过HashMap有一个问题,就是迭代HashMap的顺序并不是HashMap放置的顺序,也就是无序。HashMap的这一缺点往往会带来困扰,因为有些场景,我们期待一个有序的Map。这个时候,LinkedHashMap就闪亮登场了,它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者是访问顺序。
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
1.4.1 特点
LinkedHashMap的特点:
1.底层是哈希表+链表(保证迭代的顺序一致)
2.是一个有序的集合,存储元素和取出元素的顺序是一致的
3.Key是不可重复的,每个Key在LinkedHashMap中只能出现一次。
适用场景:
基于哈希表和链表实现,保持键值对的插入顺序,适用于需要保持插入顺序的场景。
1.4.2 使用
public static void main(String[] args) {
LinkedHashMap<String, Integer> studentScores = new LinkedHashMap<>();
// 向LinkedHashMap中添加学生姓名和分数
studentScores.put("Alice", 85);
studentScores.put("Bob", 90);
studentScores.put("Cathy", 78);
studentScores.put("David", 95);
// 遍历LinkedHashMap并打印每个学生的姓名和分数,保持插入顺序
for (Map.Entry<String, Integer> entry : studentScores.entrySet()) {
String studentName = entry.getKey();
int score = entry.getValue();
System.out.println("学生姓名: " + studentName + ", 分数: " + score);
}
System.out.println("---------------------");
studentScores.remove("Cathy");
studentScores.put("Cathy_new", 80);
// 遍历LinkedHashMap并打印每个学生的姓名和分数,保持插入顺序
for (Map.Entry<String, Integer> entry : studentScores.entrySet()) {
String studentName = entry.getKey();
int score = entry.getValue();
System.out.println("学生姓名: " + studentName + ", 分数: " + score);
}
}

创建了一个LinkedHashMap实例studentScores,并向其中添加了学生的姓名和分数。当我们遍历这个LinkedHashMap时,可以看到输出的顺序与元素插入的顺序一致,这展示了LinkedHashMap保持元素插入顺序的特点。
常用API
| api | 作用描述 |
|---|---|
| put() | 将指定的键/值映射插入到映射中 |
| putAll() | 将指定映射中的所有条目插入此map |
| putIfAbsent() | 如果map中不存在指定的键,则将指定的键/值映射插入到map中 |
| entrySet() | 返回映射的所有键/值映射的集合 |
| keySet() | 返回map所有键的集合 |
| values() | 返回map所有值的集合 |
| get() | 返回与指定键关联的值。如果未找到键,则返回null。 |
| getOrDefault() | 返回与指定键关联的值。如果找不到该键,它将返回指定的默认值。 |
| remove(key) | 返回并从映射中删除与指定键相关联的项。 |
| remove(key, value) | 仅当将指定键key映射为指定值value并返回布尔值时,才从映射中删除条目。 |
| clear() | 从map中删除所有条目 |
| containsKey() | 检查map是否包含指定的键并返回布尔值 |
| containsValue() | 检查map是否包含指定的值并返回布尔值 |
| size() | 返回map的大小 |
| isEmpty() | 检查map是否为空,并返回布尔值 |
LinkedHashMap 与 HashMap 的区别
LinkedHashMap和HashMap都实现Map接口。但是,它们之间存在一些差异:
LinkedHashMap在内部维护一个双向链表。因此,它保持其元素的插入顺序。
LinkedHashMap类需要比HashMap更多的存储空间。这是因为LinkedHashMap在内部维护链表。
LinkedHashMap的性能比HashMap慢。
1.5 ConcurrentHashMap
大名鼎鼎的HashMap不支持线程同步,于是引出了ConcurrentHashMap。
要避免 HashMap 的线程安全问题,有多个解决方法,比如改用 HashTable 或者 Collections.synchronizedMap() 方法。
但是这两者都有一个问题,就是性能,无论读还是写,他们两个都会给整个集合加锁,导致同一时间的其他操作阻塞。
ConcurrentHashMap 的优势在于兼顾性能和线程安全,一个线程进行写操作时,它会锁住一小部分,其他部分的读写不受影响,其他线程访问没上锁的地方不会被阻塞。
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
1.5.1 特点
ConcurrentHashMap的特点:
- 线程安全:ConcurrentHashMap是线程安全的,可以在多线程环境下进行并发访问而不需要额外的同步措施。它使用了一种称为分段锁(segmented locking)的机制来实现并发访问,这使得多个线程可以同时读取Map,而写操作会被限制在特定的段上,从而提高了并发性能。
- 支持高并发操作:ConcurrentHashMap适用于高并发的场景,可以在保证线程安全的同时提供较高的并发性能,因此在需要频繁读写的多线程环境下是一个很好的选择。
- 不支持null键和null值:ConcurrentHashMap不支持存储null键和null值,如果尝试存储null键或null值,将会抛出NullPointerException。
适用场景:
ConcurrentHashMap适用于多线程并发访问的场景,它提供了线程安全的操作。
1.5.2 使用
HashMap边遍历边删除数据会报错:
public static void test1() {
Map<Long, String> mReqPacket = new HashMap<Long, String>();
for (long i = 0; i < 15; i++) {
mReqPacket.put(i, i + "");
}
for (Map.Entry<Long, String> entry : mReqPacket.entrySet()) {
long key = entry.getKey();
String value = entry.getValue();
if (key < 10) {
mReqPacket.remove(key);
}
}
for (Map.Entry<Long, String> entry : mReqPacket.entrySet()) {
System.out.println(entry.getKey() + " - " + entry.getValue());
}
}

而ConcurrentHashMap会正常执行

一个线程对ConcurrentHashMap增加数据,另外一个线程在遍历时就能获得。
public static void test2() {
Map<Long, String> conMap = new ConcurrentHashMap<Long, String>();
for (long i = 0; i < 5; i++) {
conMap.put(i, i + "");
}
Thread thread = new Thread(new Runnable() {
public void run() {
conMap.put(100l, "100");
System.out.println("ADD:" + 100);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread thread2 = new Thread(new Runnable() {
public void run() {
for (Iterator<Map.Entry<Long, String>> iterator = conMap.entrySet().iterator(); iterator.hasNext(); ) {
Map.Entry<Long, String> entry = iterator.next();
System.out.println(entry.getKey() + " - " + entry.getValue());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
thread.start();
thread2.start();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("--------");
for (Map.Entry<Long, String> entry : conMap.entrySet()) {
System.out.println(entry.getKey() + " " + entry.getValue());
}
}
常用api
| api | 作用描述 |
|---|---|
| put(K key, V value) | 将指定的键值对存储到ConcurrentHashMap中。如果已经存在相同的键,则会替换对应的值。 |
| get(Object key) | 根据键获取对应的值。如果键不存在,则返回null。 |
| remove(Object key) | 根据键移除对应的键值对。如果键存在,则返回对应的值,否则返回null。 |
| containsKey(Object key) | 检查ConcurrentHashMap中是否包含指定的键。 |
| containsValue(Object value) | 检查ConcurrentHashMap中是否包含指定的值。 |
| keySet() | 返回ConcurrentHashMap中所有键的集合。这个集合是视图,对其的修改会反映到ConcurrentHashMap中。 |
| values() | 返回ConcurrentHashMap中所有值的集合。同样是一个视图,对其的修改会反映到ConcurrentHashMap中。 |
| entrySet() | 返回ConcurrentHashMap中所有键值对的集合。同样是一个视图,对其的修改会反映到ConcurrentHashMap中。 |
| putIfAbsent(K key, V value) | 如果指定的键还没有对应的值,则将指定的值与该键关联。如果已经存在该键,则返回当前的值。 |
| replace(K key, V value) | 替换指定键的值,仅当该键已经存在时才执行替换操作。 |
| clear() | 清空ConcurrentHashMap中的所有键值对。 |
| size() | 返回ConcurrentHashMap中键值对的数量。 |
二、对比总结
| Map | 特点 | 适用场景 |
|---|---|---|
| HashMap | 基于哈希表实现,允许键值对为null,不保证顺序。 | 适用于单线程环境下对数据进行快速查找和插入,不需要考虑线程安全性。 |
| TreeMap | 基于红黑树实现,键值对按照键的自然顺序或自定义顺序排序。 | 适用于需要按照顺序访问键值对的场景,提供了有序的遍历能力。 |
| LinkedHashMap | 基于哈希表和双向链表实现,保持插入顺序或访问顺序。 | 适用于需要保持插入顺序或访问顺序的场景,提供了可以预测的迭代顺序。 |
| ConcurrentHashMap | 线程安全的哈希表实现,支持高并发访问,不会出现数据不一致的情况。 | 适用于多线程并发访问的场景,能够提供线程安全的操作,避免并发访问带来的问题。 |
参考链接:
深入浅出ConcurrentHashMap详解
Map集合(超详细+源码讲解)
【Java 基础篇】Java Map 详解
ConcurrentHashMap的简要总结:















 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









