









HashMap在JDK1.7和JDK1.8中有哪些不同?HashMap的底层实现
-
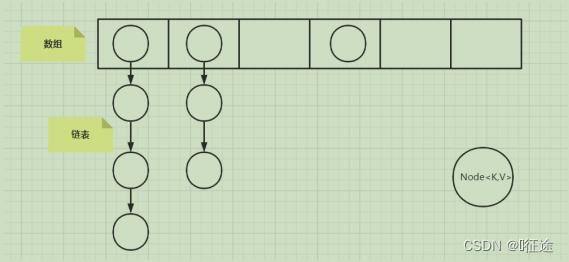
JDK1.7的底层数据结构(数组+链表)
-
JDK1.8的底层数据结构(数组+链表)

-
JDK1.7的Hash函数
static final int hash(int h){ h ^= (h >>> 20) ^ (h >>>12); return h^(h >>> 7) ^ (h >>> 4); } -
JDK1.8的Hash函数
static final int hash(Onject key){ int h; return (key == null) ? 0 : (h = key.hashCode())^(h >>> 16); }JDK1.8的函数经过了一次异或一次位运算一共两次扰动,而JDK1.7经过了四次位运算五次异或一共九次扰动。这里简单解释下JDK1.8的hash函数,面试经常问这个,两次扰动分别是key.hashCode() 与 key.hashCode() 右移16位进行异或。这样做的目的是,高16位不变,低16位与高16位进行异或操作,进而减少碰撞的发生,高低Bit都参与到Hash的计算。如何不进行扰动处理,因为hash值有32位,直接对数组的长度求余,起作用只是hash值的几个低位。
HashMap在JDK1.7和JDK1.8中有哪些不同点:
| JDK1.7 | JDK1.8 | JDK1.8的优势 | |
|---|---|---|---|
| 底层结构 | 数组+链表 | 数组+链表/红 黑树(链表大于 8) | 避免单条链表过长而影响查询效 率,提高查询效率 |
| hash值计 算方式 | 9次扰动 = 4次位运算 + 5 次异或运算 | 2次扰动 = 1次 位运算 + 1次异 或运算 | 可以均匀地把之前的冲突的节点 分散到新的桶(具体细节见下面 扩容部分) |
| 插入数据 方式 | 头插法(先讲原位置的数 据移到后1位,再插入数据 到该位置) | 尾插法(直接 插入到链表尾 部/红黑树) | 解决多线程造成死循环地问题 |
| 扩容后存 储位置的 计算方式 | 重新进行hash计算 | 原位置或原位 置+旧容量 | 省去了重新计算hash值的时间 |
HashMap 的长度为什么是2的幂次方
因为 HashMap 是通过 key 的hash值来确定存储的位置,但Hash值的范围是-2147483648到2147483647,不可能建立一个这么大的数组来覆盖所有hash值。所以在计算完hash值后会对数组的长度进行取余操作,如果数组的长度是2的幂次方, (length - 1)&hash 等同于 hash%length ,可以用(length - 1)&hash 这种位运算来代替%取余的操作进而提高性能。















 648
648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









