







 本文档介绍了一个基于Java实现的API文档搜索引擎项目。项目目标是高效检索上亿网页,核心思想采用倒排索引。首先,通过预处理解析本地HTML文件,然后构建正排和倒排索引。搜索模块根据查询词进行分词,查找倒排索引中的匹配文档,合并并排序结果。项目提供了前端页面供用户输入查询。测试显示,搜索引擎能有效处理搜索请求。
本文档介绍了一个基于Java实现的API文档搜索引擎项目。项目目标是高效检索上亿网页,核心思想采用倒排索引。首先,通过预处理解析本地HTML文件,然后构建正排和倒排索引。搜索模块根据查询词进行分词,查找倒排索引中的匹配文档,合并并排序结果。项目提供了前端页面供用户输入查询。测试显示,搜索引擎能有效处理搜索请求。
Java API 文档搜索引擎:
1、项目介绍:
(1)认识搜索引擎:
比如火狐浏览器的搜索引擎就包括:百度、谷歌
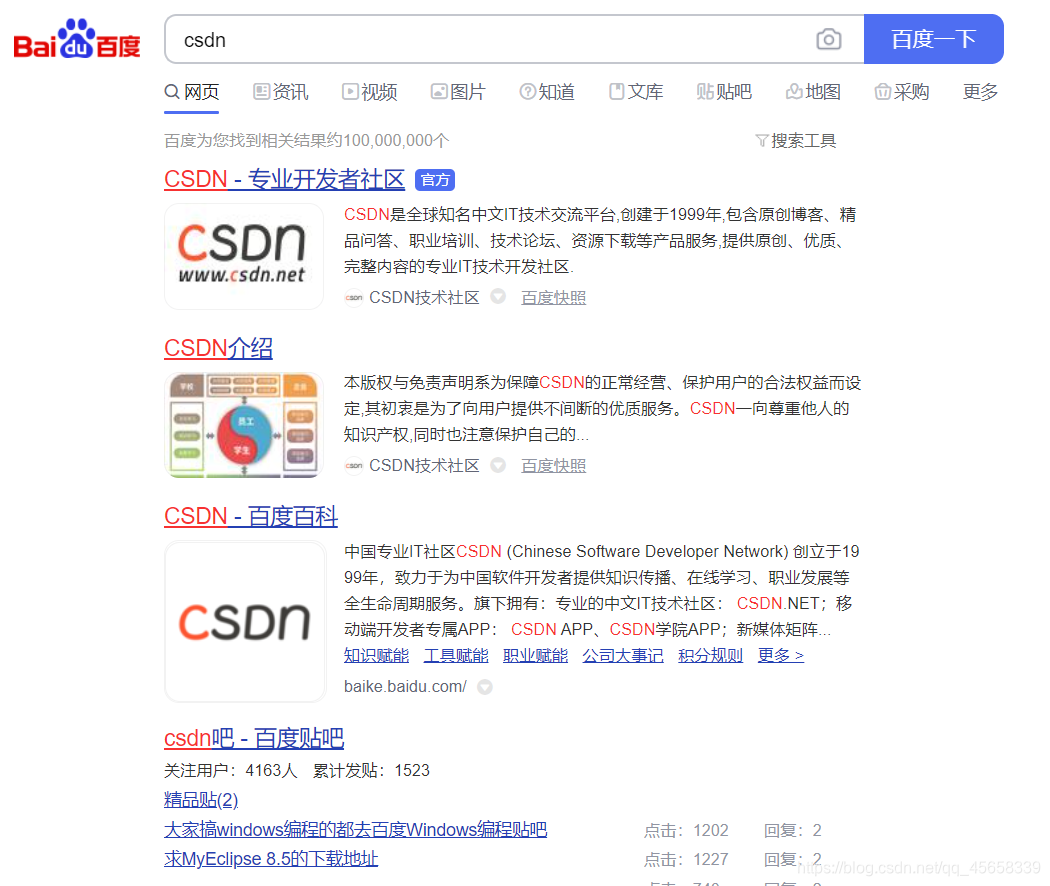
先观察,百度搜索引擎的搜索结果页中,包含了若干条结果,每一个结果中,又包含了图标,标题,描述,展示url,时间,子链,图片等。
搜索引擎的本质:
- 输入一个查询词,得到若干搜索结果,每个搜索结果包含了标题、描述、展示url和点击url
(2)搜索的核心思想:
当前我们有很多网页(假设上亿个),每个 网页 我们称为是一个 文档
如何高效进行检索?查找出有哪些网页是和查询词具有一定的相关性呢?
- 我们可以认为,网页中包含了查询词(或者查询词的一部分),就认为具有相关性
解决方案:
① 方案一 : 暴力搜索
每次处理搜索请求时,拿着查询词去所有的网页中搜索一遍,检查每个网页是否包含查询词字符串。。。
显然,这个方案的开销非常大,并且随着文档数量的增多,这样的开销会线性增长,是一种不适合的搜索方案。
② 方案二 : 倒排索引
(这是一种专门针对搜索引擎场景而设计的数据结构)
- 文档(doc):被检索的 html 页面(经过预处理)
- 正排索引:“一个文档包含了哪些词”。描述一个文档的基本信息,包括文档标题,文档正文,文档标题和正文分词(断句结果)
- 倒排索引:“一个词被哪些文档引用了”。描述了一个词的基本信息,包括了词都被哪些文档引用,这个词在该文档的重要程度,以及这个词的出现位置等。
(3)项目的目标:
实现一个 Java API 文档的简单的搜索引擎
2、项目准备:
项目全部源码(项目配置) GitHub 链接:
https://github.com/JACK-QBS/Project
代码框架如下:

简单介绍一下:
① java包 下的代码是我们的 后端 代码,用来响应来自前端的请求和与数据库的交互;
② webapp包 下的代码是我们的 前端 代码,即用户界面的设计。
(1)需要的资源:
Maven、IDEA、Chrome浏览器、Fiddler4抓包工具(可使用浏览器自带的开发者工具)
(2)创建web项目:
具体创建步骤和环境配置:
https://blog.csdn.net/qq_45658339/article/details/112249187
这个项目中 pop.xml 的配置源码放到 GitHub 中:
https://github.com/JACK-QBS/Project
3、开发步骤:
(1)创建三个 JavaBean 公共模块
1、每一个本地 html 文件对应一个文档对象(文档对应的结构)
public class DocInfo {
private Integer id;//类似数据库主键(识别不同文档)
private String title;//标题:html文件名作为标题
private String url; //oracle官网api文档下html的url
private String content;//网页正文:<标签>内容</标签>,内容为正文
}
2、倒排索引 Map<String,List>中,关键词对应的信息
public class Weight {
private DocInfo doc;
private int weight;//权重值:通过标题和正文中,关键词的数量计算
private String keyword;//关键词
}
3、返回结果集对象
public class Result {
//合并文档,排序用
private Integer id;//docInfo的id,文档合并时,文档身份的标识
private int weight;//权重:同一个文档合并后,权限相加,再排序
//返回给前端用
private String title;//文档(docInfo)的标题
private String url;//文档(docInfo)的url
private String desc;//docInfo的content(超长时,截取指定长度)
}
(2)预处理:解析本地 html 文件
遍历 api 目录下所有的文件, 并读取每个文件的内容, 把所有文件整理成一个行文本文件( 每行对应一个 html)
每一个 文件 转化为 DocInfo 对象:
- ① url : 官网url的前缀 + 本地 api 目录下 html 文件的相对路径
- ② title : 简单处理为文件名
- ③ 内容:输入流读取html内容(不读取标签本身,读取标签内容)
输出流保存到 本地 raw_data.txt 文件中
public class Parser {
//api目录
public static final String API_PATH = "D:\\Code\\Project\\docs\\api";
//构建的本地文件正排索引
public static final String RAW_DATA = "D:\\Code\\Project/raw_data.txt";
//官方api文档的根路径(拼接本地api路径)
public static final String API_BASE_PATH = "https://docs.oracle.com/javase/8/docs/api";
public static void main(String[] args) throws IOException {
//找到api本地路径下所有的html文件
List<File> htmls = listHtml(new File(API_PATH));
FileWriter fw = new FileWriter(RAW_DATA);
PrintWriter pw = new PrintWriter(fw,true); //打印输出流,自动刷新缓冲区
for (File html : htmls) {
//一个html解析DocInfo有的属性(输入)
DocInfo doc = parseHtml(html);
//保存本地正排索引文件(输出)(行号代表id)
//格式:一行为一个doc,title+\3 + url + content
String uri = html.getAbsolutePath().substring(API_PATH.length());
System.out.println("Parse: "+uri);
if(doc.getTitle().contains("�")){
System.out.println("title====================="+doc.getTitle());
}
if(doc.getContent().contains("�")){
System.out.println("content====================="+doc.getContent());
}
pw.println(doc.getTitle()+"\3"+doc.getUrl()+"\3"+doc.getContent());
}
}
private static DocInfo parseHtml(File html) {
DocInfo doc = new DocInfo( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1653
1653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









