







在建表的时候,有时候一些字段会有一些限制条件,这时候就需要一些约束条件了。
约束类型
not null- 指示某列不能存储 NULL 值。
创建表时,可以指定某列不为空:
– 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INTNOT NULL,
sn INT,
name VARCHAR(20),
qq_mail VARCHAR(20)
);
unique- 保证某列的每行必须有唯一的值。
指定sn列为唯一的、不重复的:
– 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INTUNIQUE,
name VARCHAR(20),
qq_mail VARCHAR(20)
);
default- 规定没有给列赋值时的默认值。
指定插入数据时,name列为空,默认值unkown:
– 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT UNIQUE,
name VARCHAR(20)DEFAULT‘unkown’,
qq_mail VARCHAR(20)
);
primary key(not null和unique的结合)确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
指定id列为主键:
– 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULLPRIMARY KEY,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT ‘unkown’,
qq_mail VARCHAR(20)
);
对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,使用最大值+1。
– 主键是 NOT NULL 和 UNIQUE 的结合,可以不用 NOT NULL
id INTPRIMARY KEY auto_increment,
foreign key- 保证一个表中的数据匹配另一个表中的值的参照完整性。
外键用于关联其他表的主键或唯一键,
语法:
foreign key(字段名)references主表(列)
案例:
创建班级表classes,id为主键:
– 创建班级表,有使用MySQL关键字作为字段时,需要使用``来标识
DROP TABLE IF EXISTS classes;
CREATE TABLE classes (
id INTPRIMARY KEYauto_increment,
name VARCHAR(20),
descVARCHAR(100)
);
创建学生表student,一个学生对应一个班级,一个班级对应多个学生。使用id为主键,
classes_id为外键,关联班级表id
– 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT PRIMARY KEY auto_increment,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT ‘unkown’,
qq_mail VARCHAR(20),
classes_id int,
FOREIGN KEY(classes_id)REFERENCESclasses(id)
);
check- 保证列中的值符合指定的条件。
MySQL使用时不报错,但忽略该约束:
drop table if exists test_user;
create table test_user (
id int,
name varchar(20),
sex varchar(1),
check(sex =‘男’ or sex=‘女’)
);
表的设计
一对一
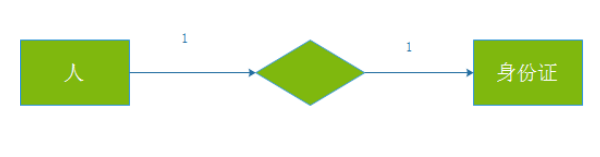
一对多
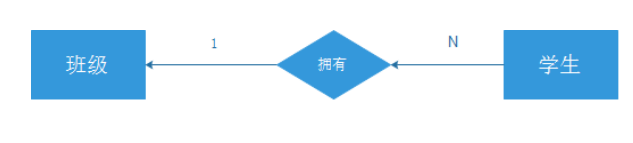
多对多

创建学生课程中间表,考试成绩表
– 创建课程学生中间表:考试成绩表
DROP TABLE IF EXISTS score;
CREATE TABLE score (
id INT PRIMARY KEY auto_increment,
score DECIMAL(3, 1),
student_id int,
course_id int,
FOREIGN KEY (student_id) REFERENCES student(id),
FOREIGN KEY (course_id) REFERENCES course(id)
);
查询
聚合查询
常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有:
-
聚合函数

-
group by子句
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
- having
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句(where和聚合函数不能一起使用),而需要用HAVING
联合查询
实际开发中数据往往来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积:
注意:关联查询可以对关联表使用别名。

- 内连接

select 字段 from 表1 别名1
[inner] join表2 别名2on连接条件and其他条件;
select 字段 from 表1 别名1,表2 别名2where连接条件and其他条件;
- 外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完 全显示我们就说是右外连接。


– 左外连接,表1完全显示
select 字段名 from 表名1left join表名2on连接条件;
– 右外连接,表2完全显示
select 字段 from 表名1right join表名2on连接条件;
- 自连接
自连接是指在同一张表连接自身进行查询。涉及join时至少需要一张表。
select … from 表1,表1
where条件
select … from 表1join表1on条件
- 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
1.[NOT] IN关键字:
– 使用IN
select * from score where course_idin(select id from course where name=‘语文’ or name=‘英文’);
– 使用 NOT IN
select * from score where course_idnot in(select id from course where name!=‘语文’ and name!=‘英文’);
2.[NOT] EXISTS关键字:(比较复杂,我们一般采用in)
– 使用 EXISTS
select * from score sco whereexists(select sco.id from course cou where (name=‘语文’ or name=‘英文’) and cou.id = sco.course_id);
– 使用 NOT EXISTS
select * from score sco wherenot exists(select sco.id from course cou where (name!=‘语文’ and name!=‘英文’) and cou.id = sco.course_id);
- 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
1. union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
2.union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
SQL中关键字的执行顺序
SQL查询中各个关键字的执行先后顺序: from > on> join > where > group by > with > having > select > distinct > order by > limit
三个范式
即: 属性唯一, 记录唯一, 表唯一
- 第一范式(1NF):
数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。
- 第二范式(2NF):
数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖(部分函数依赖指的是存在组合关键字中的某些字段决定非关键字段的情况),也即所有非关键字段都完全依赖于任意一组候选关键字。
- 第三范式(3NF):
在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。所谓传递函数依赖,指的是如果存在"A → B → C"的决定关系,则C传递函数依赖于A。因此,满足第三范式的数据库表应该不存在如下依赖关系: 关键字段 → 非关键字段x → 非关键字段y
总结
约束和连接很重要,多练吧。奥利给!















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









