







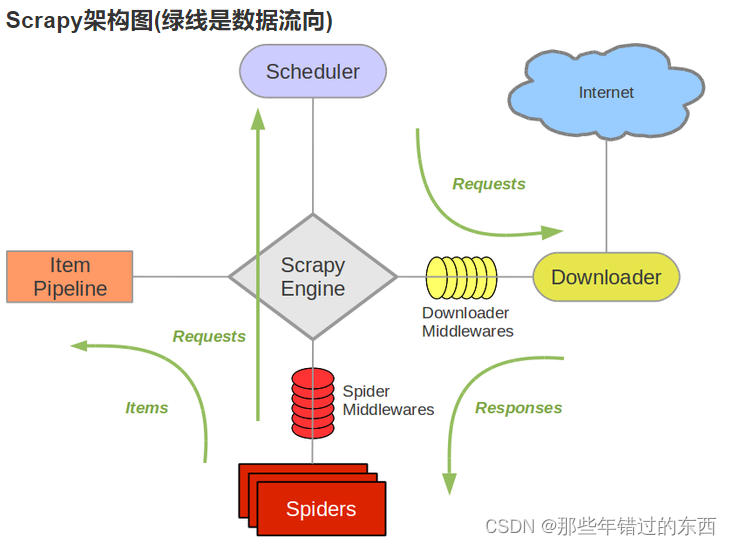
Spiders(url)–scrapyEnging(中转)–scheduler(url调度)–scrapyEnging(中转)–downloader(请求数据)–scrapyEnging(中转)–Spiders(返回url执行开始的顺便,data继续执行)–itempipeline(数据存储)
创建scrapy项目:scrapy startproject+爬虫项目名称
scrapy startproject biquge
创建爬虫:scrapy genspider+自己设置爬虫名字+爬虫的域名
scrapy genspider biquge_spider "www.qbiqu.com"
C:\Users\luoha>d:
D:\>cd D:\python\AAA_scrapy #切换要保存项目的地址
D:\python\AAA_scrapy>scrapy startproject biquge #创建项目
New Scrapy project 'biquge', using template directory 'e:\pycharm5.0.3\python-3.7.0\lib\site-packages\scrapy\templates\project', created in:
D:\python\AAA_scrapy\biquge
You can start your first spider with:
cd biquge
scrapy genspider example example.com
D:\python\AAA_scrapy>cd D:\python\AAA_scrapy\biquge #切换到创建的项目下
D:\python\AAA_scrapy\biquge>scrapy genspider biquge_spider "www.qbiqu.com"
Created spider 'biquge_spider' using template 'basic' in module:
{spiders_module.__name__}.{module}
D:\python\AAA_scrapy\biquge>
编写scrapy爬虫,引入items中的BiqugeItem类进行数据过度
import scrapy
from biquge.items import BiqugeItem
class BiqugeSpiderSpider(scrapy.Spider):
name = 'biquge_spider'
allowed_domains = ['www.qbiqu.com']
start_urls = ['http://www.qbiqu.com/']
def parse(self, response):
lis=response.xpath("//div[@id='hotcontent']/div[@class='r']/ul/li")
for li in lis:
type=li.xpath("./span[@class='s1']/text()").extract()[0] #extract_first()
title=li.xpath("./span[@class='s2']/a/text()").extract()[0] #extract_first()
name=li.xpath("./span[@class='s5']/text()").extract()[0] #extract_first()
# print(item)
item=BiqugeItem(type=type,title=title,name=name)
# print(type(item))
yield item
在items文件定义爬取的字段
import scrapy
class BiqugeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
type=scrapy.Field()
title=scrapy.Field()
name=scrapy.Field()
# pass
pipelines文件进行数据输出存储
class BiqugePipeline:
def process_item(self, item, spider):
print(item) #这里就没写存储了,直接输出
要用到pipelines别忘记在setting打开一些配置














 786
786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









