







刚写完京东爬虫,趁着记忆还深刻,写点总结吧。
一、前提
默认已用scrapy爬取过网站,有爬虫基础,有爬虫环境
二、以爬取电子烟为例
1、任务一:爬取商品信息
在搜索框里面直接搜索电子烟,搜出来的界面,你会发现它是动态加载的。即一开始源代码里面只能看到30条商品的信息,随着你的下拉,另外30条才会加载出来。因此爬取起来比较麻烦。后来发现,从京东左边的商品分类中找到电子烟这一分类
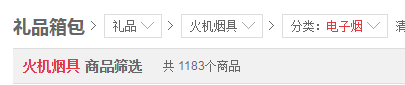
此时的搜索到的电子烟分类的展示网页是一开始就已加载了全部60条商品信息的。商品信息准备从这一页入手。
有爬虫基础的很快就能知道下一步要怎么做了,首先我们需要获得每个商品的信息和链接,称搜索出来的展示页面为搜索页面,进入到商品的详情页面为详情页面。
(1)我们先从搜索页的处理开始

通过抽取<li class="gl-item"> 标签,很快能得到商品的信息。
从搜索页面能抓取到商品的ID,详情页链接,商品名字,店铺名字这些信息。而价钱是动态加载的,注意千万不要被检查(就是chrome通过右键点击检查看到的代码)误解。爬虫爬到的是源代码,检查看到的代码和源代码的代码是不一样的。以源代码为主。
这是检查看到的代码
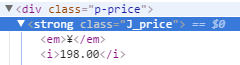
这是源代码看到的代码
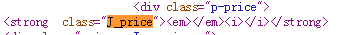
不信可以用爬虫爬取网页试试。所以确定价钱通过网页爬取不到ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8160
8160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









