






糗事百科成人版的段子爬虫
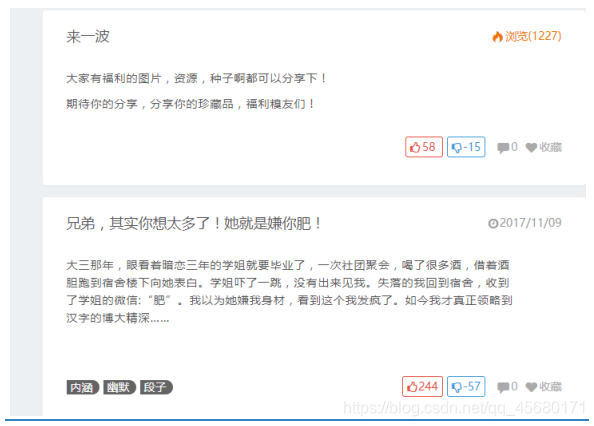

查看网站源代码,发现段子的规律为:
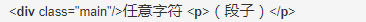
因此正则表达式可以写成

然后观察网址规律,发现格式是…page/n,n是页数
因此可以自己构造url访问多页

最后是针对某些反爬机制 可以自己添加用户代理池和ip代理池然后随机调用代理池(这个糗事百科没什么反爬机制可以不写)
常用用户代理池
https://blog.csdn.net/wangqing84411433/article/details/89600335
效果图

完整代码
#糗事百科段子爬虫
import urllib.request
import re
import random
uapools=[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
def ua(uapools):
thisua=random.choice(uapools)
print(thisua)
headers=("User-Agent",thisua)
opener=urllib.request.build_opener()
opener.addheaders=[headers]
#安装为全局
urllib.request.install_opener(opener)
for i in range(0,9):
ua(uapools)
thisurl="http://www.qiumeimei.com/text/page/"+str(i+1)
data=urllib.request.urlopen(thisurl).read().decode("utf-8","ignore")
pat='<div class="main">.*?<p>(.*?)</p>'
rst=re.compile(pat,re.S).findall(data)
print("---------------------------"+str(i+1)+"-----------------------")
for j in range(0,len(rst)):
print(rst[j])
print("-------")















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









