






一、缺失值处理
1 如何处理nan
获取缺失值的标记方式(NaN或者其他标记方式)
如果缺失值的标记方式是NaN
判断数据中是否包含NaN:
pd.isnull(df),
pd.notnull(df)
存在缺失值nan:
1、删除存在缺失值的:dropna(axis='rows')
注:不会修改原数据,需要接受返回值
2、替换缺失值:fillna(value, inplace=True)
value:替换成的值
inplace:True:会修改原数据,False:不替换修改原数据,生成新的对象
如果缺失值没有使用NaN标记,比如使用"?"
先替换‘?’为np.nan,然后继续处理
2.1 判断缺失值是否存在
- pd.notnull()
- np.all(pd.notnull())
- pd.isnull()
2.2 缺失值是nan标记处理方式
- 1、删除:pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
- dropna()
- 2、替换缺失值
2.3 缺失值不是
nan标记的处理方式
处理思路分析:
1、先替换‘?’为np.nan
- df.replace(to_replace=, value=)
- to_replace:替换前的值
- value:替换后的值
# 把一些其它值标记的缺失值,替换成np.nan
wis = wis.replace(to_replace='?', value=np.nan)2、在进行缺失值的处理
# 删除
wis = wis.dropna()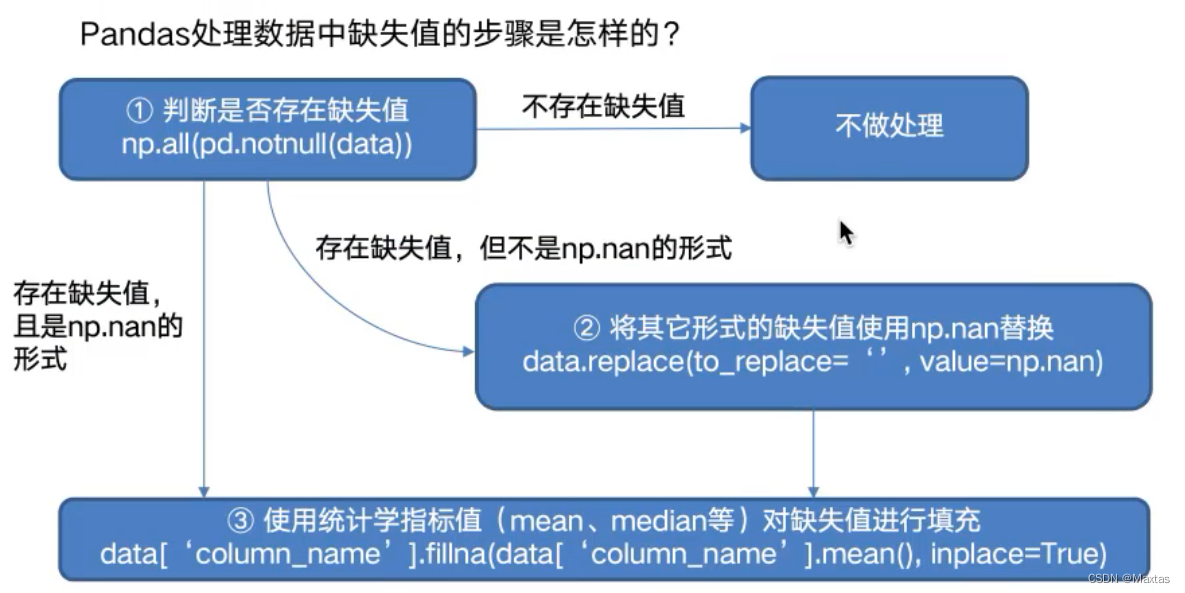 二、数据离散化
二、数据离散化
1 为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
2 Def
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值。
3 STEP
3.1 读取数据
3.2 数据分组
使用的工具:
- pd.qcut(data, q):
- 对数据进行分组将数据分组,一般会与value_counts搭配使用,统计每组的个数
- series.value_counts():统计分组次数
自定义区间分组:
- pd.cut(data, bins)
3.3 分组数据变成one-hot编码
- 什么是one-hot编码
把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1.其又被称为独热编码。
把下图中左边的表格转化为使用右边形式进行表示:
-
pandas.get_dummies(data, prefix=None)
-
data:array-like, Series, or DataFrame
-
prefix:分组名字
-
三、合并
1 pd.concat实现数据合并
- pd.concat([data1, data2], axis=1)
- 按照行或列进行合并,axis=0为列索引,axis=1为行索引
2 pd.merge
2.1 api介绍
- pd.merge(left, right, how='inner', on=None)
- 可以指定按照两组数据的共同键值对合并或者左右各自
left: DataFrameright: 另一个DataFrameon: 指定的共同键- how:按照什么方式连接
| Merge method | SQL Join Name | Description |
|---|---|---|
left | LEFT OUTER JOIN | Use keys from left frame only |
right | RIGHT OUTER JOIN | Use keys from right frame only |
outer | FULL OUTER JOIN | Use union of keys from both frames |
inner | INNER JOIN | Use intersection of keys from both frames |
2.2 pd.merge合并案例
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
# 默认内连接
result = pd.merge(left, right, on=['key1', 'key2'])- 内连接
- 左连接
result = pd.merge(left, right, how='left', on=['key1', 'key2'])
- 右连接
result = pd.merge(left, right, how='right', on=['key1', 'key2'])
- 外链接 :求并集
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
四、交叉表与透视表
- 交叉表:交叉表用于计算一列数据对于另外一列数据的分组个数(用于统计分组频率的特殊透视表)
- pd.crosstab(value1, value2)
- 透视表:一列数据对另外一列数据的占比
- data.pivot_table()
-
- DataFrame.pivot_table([], index=[])
1 分组API
- DataFrame.groupby(key, as_index=False)
- key:分组的列数据,可以多个















 280
280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









