







生成模型–自编码器(Autoencoder,AE)
自编码器(Autoencoder,AE)
基本意思就是一个隐藏层的神经网络,输入输出都是x,并且输入维度一定要比输出维度大,属于无监督学习。一种利用反向传播算法使得输出值等于输入值的神经网络,它先将输入压缩成潜在空间表征,然后通过这种表征来重构输出。
参考资料:
https://blog.csdn.net/hjimce/article/details/49106869
https://blog.csdn.net/marsjhao/article/details/73480859
自编码器的理解
自编码器能从数据样本中进行无监督学习,这意味着可将这个算法应用到某个数据集中,来取得良好的性能,且不需要任何新的特征工程,只需要适当地训练数据。
但是,自编码器在图像压缩方面表现得不好。由于在某个给定数据集上训练自编码器,因此它在处理与训练集相类似的数据时可达到合理的压缩结果,但是在压缩差异较大的其他图像时效果不佳。这里,像JPEG这样的压缩技术在通用图像压缩方面会表现得更好。
训练自编码器,可以使输入通过编码器和解码器后,保留尽可能多的信息,但也可以训练自编码器来使新表征具有多种不同的属性。不同类型的自编码器旨在实现不同类型的属性。
通过施加不同约束,包括缩小隐含层的维度和加入惩罚项,使每种自编码器都具有不同属性。自编码器吸引了一大批研究和关注的主要原因之一是很长时间一段以来它被认为是解决无监督学习的可能方案,即大家觉得自编码器可以在没有标签的时候学习到数据的有用表达。
再说一次,自编码器并不是一个真正的无监督学习的算法,而是一个自监督的算法。自监督学习是监督学习的一个实例,其标签产生自输入数据。要获得一个自监督的模型,你需要想出一个靠谱的目标跟一个损失函数,问题来了,仅仅把目标设定为重构输入可能不是正确的选项。
基本上,要求模型在像素级上精确重构输入不是机器学习的兴趣所在,学习到高级的抽象特征才是。
事实上,当你的主要任务是分类、定位之类的任务时,那些对这类任务而言的最好的特征基本上都是重构输入时的最差的那种特征。
自编码器的架构
自编码器由两部分组成:
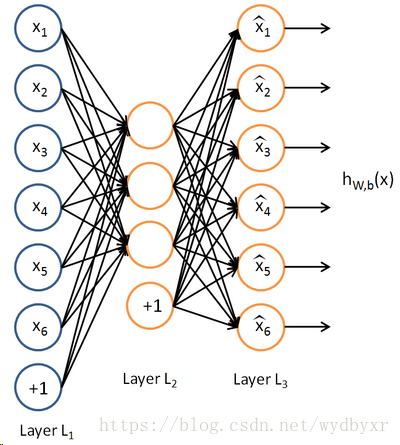
1)编码器:这部分能将输入压缩成潜在空间表征,可以用编码函数h=f(x)表示。
2)解码器:这部分能重构来自潜在空间表征的输入,可以用解码函数r=g(h)表示。
此类架构的基本结构单元为自动编码器,它通过对输入特征X按照一定规则及训练算法进行编码,将其原始特征利用低维向量重新表示。
自编码器若仅要求X≈Y,且对隐藏神经元进行稀疏约束,从而使大部分节点值为0或接近0的无效值,便得到稀疏自动编码算法。一般情况下,隐含层的神经元数应少于输入X的个数,因为此时才能保证这个网络结构的价值。
编码维数小于输入维数的欠完备自编码器可以学习数据分布最显著的特征。我们已经知道,如果赋予这类自编码器过大的容量,它就不能学到任何有用的信息。
如果隐藏编码的维数允许与输入相等,或隐藏编码维数大于输入的 过完备(overcomplete)情况下,会发生类似的问题。在这些情况下,即使是线性编码器和线性解码器也可以学会将输入复制到输出,而学不到任何有关数据分布的有用信息。
自编码器的应用
第一是数据去噪。
第二是为进行可视化而降维。
第三是进行图像压缩。
第四传统自编码器被用于降维或特征学习。
自动编码器与PCA的比较
1)它是一种类似于 PCA 的无监督机器学习算法。大体上,AutoEncoder可以看作是PCA的非线性补丁加强版,PCA的取得的效果是建立在降维基础上的。
2)它要最小化和 PCA 一样的目标函数。自动编码器的目标是学习函数 h(x)≈x。换句话说,它要学习一个近似的恒等函数,使得输出 x^ 近似等于输入 x。
3)它是一种神经网络,这种神经网络的目标输出就是其输入。自动编码器属于神经网络家族,但它们也和 PCA(主成分分析)紧密相关。
总之,尽管自动编码器与 PCA 很相似,但自动编码器比 PCA 灵活得多。在编码过程中,自动编码器既能表征线性变换,也能表征非线性变换;而 PCA 只能执行线性变换。因为自动编码器的网络表征形式,所以可将其作为层用于构建深度学习网络。设置合适的维度和稀疏约束,自编码器可以学习到比PCA等技术更有意思的数据投影。
正如主成分分析(principal component analysis,PCA)算法,通过降低空间维数去除冗余,利用更少的特征来尽可能完整的描述数据信息。
实际应用中将学习得到的多种隐层特征(隐层数通常多个)与原始特征共同使用,可以明显提高算法的识别精度。
自编码器与DL
仿照stacked RBM构成的DBN,提出Stacked AutoEncoder,为非监督学习在深度网络的应用又添了猛将。
自编码器在实际应用中用的很少,2012年人们发现在卷积神经网络中使用自编码器做逐层预训练可以训练深度网络,但很快人们发现良好的初始化策略在训练深度网络上要比费劲的逐层预训练有效得多,2014年出现的Batch Normalization技术使得更深的网络也可以被有效训练,到了2015年底,通过使用残差学习(ResNet)我们基本上可以训练任意深度的神经网络。
各种自编码器的变种
如果在自编码器的基础上继续加上一些约束条件的话,就可以得到新的深度学习方法。
1)去噪自动编码器
2)稀疏自动编码器
3)变分自动编码器(VAE)
4)收缩自动编码器(CAE/contractive autoencoder)

训练方法
训练方法有很多,几乎可以采用任何连续化训练方法来训练参数,例如梯度下降、最小二乘、循环算法等等。但由于其模型结构不偏向生成型(一般是判别型),无法通过联合概率等定量形式确定模型合理性。

















 9589
9589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









