







相信我 耐心看完 肯定能懂的!
参考了几个大佬的文章
然后做了个简单的整理和结合
一文弄懂神经网络中的反向传播法——BackPropagation
反向传播算法(Back propagation)
python 反向传播算法的入门教程的简单代码实现

文章目录
1.反向传播算法的简单理解
反向传播算法是多层神经网络训练中举足轻重的算法
简单的理解:BP算法就是复合函数的链式法则,即对一个链式求导法则反复进行使用,但是BP算法在实际运算中的意义远大于链式法则。
想要理解BP算法 需要先直观理解多层神经网络的训练
2.直观理解多层神经网络的训练
首先,机器学习可以看做是数理统计的一个应用 数理统计中一个常见的任务就是拟合
拟合:给定一些样本点,用合适的曲线揭示这些样本点随自变量的变化关系。
深度学习同样是为了这个目的,不同的是 深度学习中样本点不再限定为(x,y)
而是可以由向量、矩阵等等组成的广义点对(X,Y)
广义点对之间的关系变得十分复杂,不太可能用一个简单函数表示。
然而,人们发现可以用多层神经网络来表示这样的关系
多层神经网络的本质就是一个多层复合的函数
来看一个经典图
这是一个典型的三层神经网络的基本构成。
对应表达式如下:
wij就是相邻两层神经元之间的权值 即为深度学习需要学习的参数——也就相当于直线拟合y=kx+b中的待求参数k 和 b

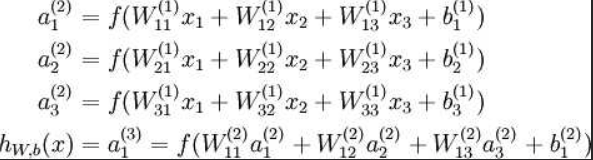
现在我们手里有一些数据
输入:{x1,x2,x3,…,xn} 输出:{y1,y2,y3,…,yn}
我们深度神经网络是干啥的?
把输入数据在隐含层做某种变换 让输出数据与期望相同。
和直线拟合一样,深度学习的训练也有一个目标函数,这个目标函数定义了什么样的参数才算一组“好参数”,不过在机器学习中,一般是采用成本函数(cost
function),然后,训练目标就是通过调整每一个权值Wij来使得cost达到最小。 而这个成本函数cost
function也可以看成是由所有待求权值Wij为自变量的复合函数,而且基本上是非凸的(含有许多局部最小值)。
采用常用的梯度下降法可以有效地求解最小化cost函数的问题,从而训练出“好参数”。
接下来举一个例子 代入数值演示反向传播法的过程~
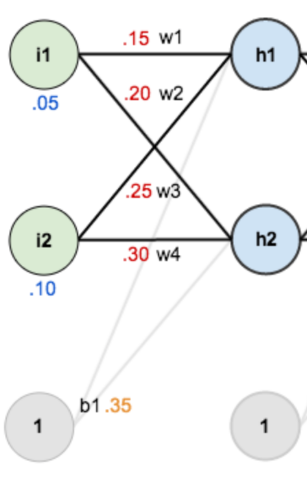
简单的三层神经网络

第一层是输入层 包含两个神经元i1 i2 截距项b1
第二层是隐含层
第三层是输出o1 o2
每条线上标的wi是层与层之间连接的权重
激活函数是我们默认的sigmoid函数
代入数值加深理解深层神经网络
现在来给这些权重、输入数据、输出数据赋一个值

输入数据 i1=0.05 i2=0.10
输出数据o1=0.01 o2=0.99
初始权重 w1=0.15 w2=0.20 w3=0.25 w4=0.30
w5=0.40 w6=0.45 w7=0.50 w8=0.55
目标:给出输入数据i1 i2 使输出尽可能与原始输出o1 o2 接近
为了实现这个目标 我们要经历怎么样一个过程呢?
Step1 前向传播
1.输入层—>隐含层
计算隐藏层神经元h1的输入加权和:
neta代表结点a的输入值
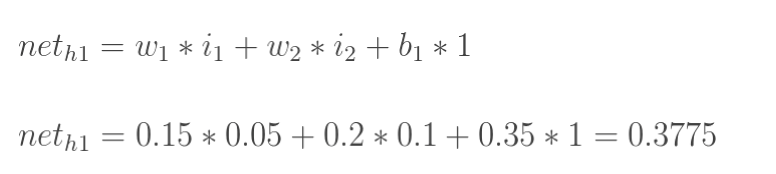
神经元h1的输出o1:(此处用到激活函数为sigmoid函数)
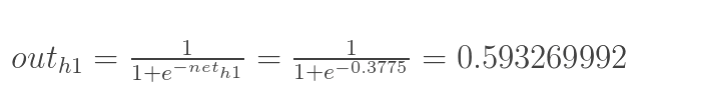
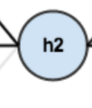
同理 可以计算出同层的神经元h2的输出o2:
2.隐含层—>输出层
计算输出层神经元o1和o2的值:


同理 o2值为
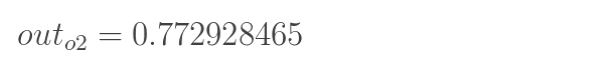
前向传播过程结束!
得到了输出值o1 o2 : [0.75136079 , 0.772928465]
实际值是:[0.01,0.99]…所以还差挺远呐
但是没关系啊
我们对误差进行反向传播,更新权值,重新计算输出
Step2 反向传播
0.先理解啥是反向传播!
【1】明确我们的最终目标——通过训练获得 Wij 参数
【2】怎么训练?——通过调整每一个权值Wij来使得cost函数(成本函数)达到最小
这里cost函数也可以看成是由所有待求权值Wij为自变量的复合函数
cost函数基本上是非凸的 即含有许多局部最小值
【3】如何调整Wij 来求解最小化cost函数的问题?——使用梯度下降法
梯度下降法
给定一个初始点 并 求出初始点的梯度向量
然后以负梯度方向为搜索方向 以一定的步长进行搜索
从而确定下一个迭代点 再计算这个新的梯度方向
重复以上步骤直到cost函数收敛
计算梯度
重点来啦!
之前我一直不知道为啥子要有——
整体误差对w5的偏导值来代表权重w5对整体误差产生了多少影响
这一步
现在来看一下!
之前说

所以假设cost函数为 H(W11,W12,…,Wij,…,Wmn) 那么它的梯度向量[2]就等于——
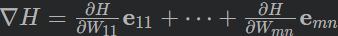
其中eij表示正交单位向量
为此 我们需要求出cost函数H对每一个权值Wij的偏导数
这!就引出了我们的BP算法~
我们要用BP算法来求解这种多层复合函数(指cost函数)的所有变量(W11 W12 …)的偏导数
求多层复合函数所有变量的偏导数!
举个栗子来说明~~
求e=(a+b)*(b+1)的偏导
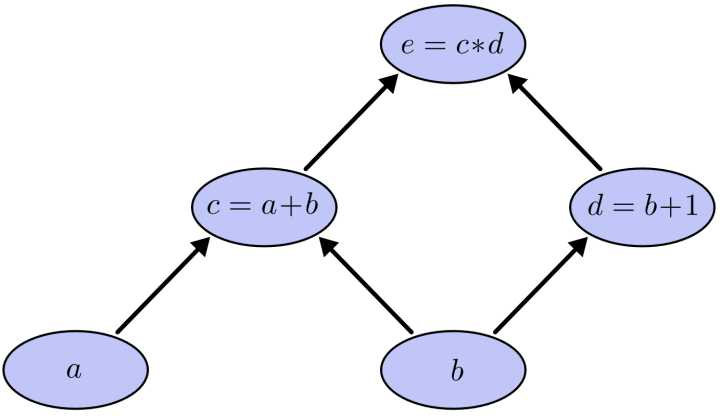
可以看到图中引入了中间变量 c d
代入数值进行计算<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2352
2352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









