







第2次实验:主成分分析PCA
1. 算法描述
功能:
利用PCA算法可以对给定的数据集进行降维操作,使得处理后的数据不仅维数较低、能保存绝大部分信息,而且各维之间的相关性也为0(没有冗余信息,正交)。
2. PCA的数学原理
(1) PCA的目的
一般而言,一个未经处理的数据集可能存在两个问题,一个是维数太高,另一个是各维度特征之间存在着相关性,从而导致各维存储的信息之间存在冗余。由于这两个问题的存在,给人们压缩、存储、处理相关数据带来了一定的困难。因此,我们需要找到一种能够对数据进行降维处理的同时还能保留大部分信息的算法去对原始数据进行处理,使得处理后的数据不仅维数较低、能保存绝大部分信息,而且各维之间的相关性也为0(没有冗余信息,正交)。
(2) 方差、协方差的意义
方差越大,说明数据越分散。我们通常认为,在某个特征维度上数据越分散,该特征越重要。
协方差用来刻画两个随机变量之间的相关性,反映的是变量之间的二阶统计特性。相关系数和协方差在描述相关性(线性相关)方面是等价的,而独立与相关的关系是:独立一定不相关,不相关不一定独立(因为可能存在非线性关系)。在实际应用中,协方差可以用来刻画两个特征维度之间的相关性。
(3) PCA的核心思想
设原数据集矩阵
X
n
×
m
X_{n×m}
Xn×m对应的协方差矩阵为
C
n
×
n
C_{n×n}
Cn×n,而
P
k
×
n
P_{k×n}
Pk×n是一组基沿行方向排列构成的矩阵(线性变换矩阵),设变换后的数据为
Y
k
×
m
=
P
X
Y_{k×m}=PX
Yk×m=PX。设
Y
Y
Y的协方差矩阵为
D
k
×
k
D_{k×k}
Dk×k,则
D
D
D与
C
C
C的关系推导如下:
D
=
1
m
Y
Y
T
=
1
m
(
P
X
)
(
P
X
)
T
=
1
m
(
P
X
X
T
P
T
)
=
P
(
1
m
X
X
T
)
P
T
=
P
C
P
T
D=\frac{1}{m}YY^T=\frac{1}{m}(PX)(PX)^T=\frac{1}{m}(PXX^TP^T)=P(\frac{1}{m}XX^T)P^T=PCP^T
D=m1YYT=m1(PX)(PX)T=m1(PXXTPT)=P(m1XXT)PT=PCPT
那么现在问题等价为求一个线性变换矩阵
P
P
P,使得
P
C
P
T
PCP^T
PCPT为对角阵,且对角元素从上到下依次递减。
考虑到协方差矩阵 c c c是一个实对称矩阵,因此它具有一些良好的数学性质:
(a) 实对称矩阵不同特征值对应的特征向量必然正交;
(b) 设 e 1 , . . . , e n e_1, ..., e_n e1,...,en为 C C C的 n n n个特征向量,设 E E E为这 n n n个特征向量按行排列构成的矩阵,则必有 E C E T = Λ ECE^T=\Lambda ECET=Λ。
因此,为了将 X X X降至 k k k维且让 D D D的对角元素值从第一行向下递减,我们只需要将 C C C的前 k k k个最大的特征值对应的特征向量构成正交变换矩阵 P P P即可实现目标。
3. 算法流程
(1) 将原始数据矩阵 X X X中心化( X : = X − μ X:=X-\mu X:=X−μ);
(2) 计算 X X X的协方差矩阵 C C C;
(3) 计算 C C C的特征值和特征向量,取前 k k k个最大的特征值对应的特征向量构成变换矩阵 P P P ;
(4) 利用 Y = P X Y=PX Y=PX得到降维后的数据;
(5) 计算 Y Y Y的协方差矩阵 D D D。
4. 核心代码
def pca(X, k):
# 样本中心化,axis=0表示计算每一列的均值
X = X - np.mean(X, axis=0)
# 将X变为nxm形式
X = X.T
# 计算协方差矩阵
C_before = 1 / (X.shape[1]) * np.dot(X, X.T)
# 计算特征值和对应的特征向量矩阵
eigenvalues, eigenvectors = np.linalg.eig(C_before)
# 求出最大的k个特征值的索引,np.argsort返回数组从小到大排序后的数在原数组中的索引
indexes = np.argsort(eigenvalues)[::-1][:k] # [::-1]将数组倒序,[:k]取前k个值
# 选择特征向量矩阵中列索引在indexes中的所有列构成最终的投影矩阵
P = eigenvectors[:, indexes]
# 将特征向量转为沿行方向排列
P = P.T
# 计算降维结果Y=PX
Y = np.dot(P, X)
# 求降维之后的矩阵协方差
C_after = np.cov(Y, rowvar=1)
return C_before, Y, C_after
5. 实验结果
我在程序中设置numpy的结果显示小数位为4位,原始数据的协方差矩阵、PCA后的数据、降维后的数据协方差矩阵如下: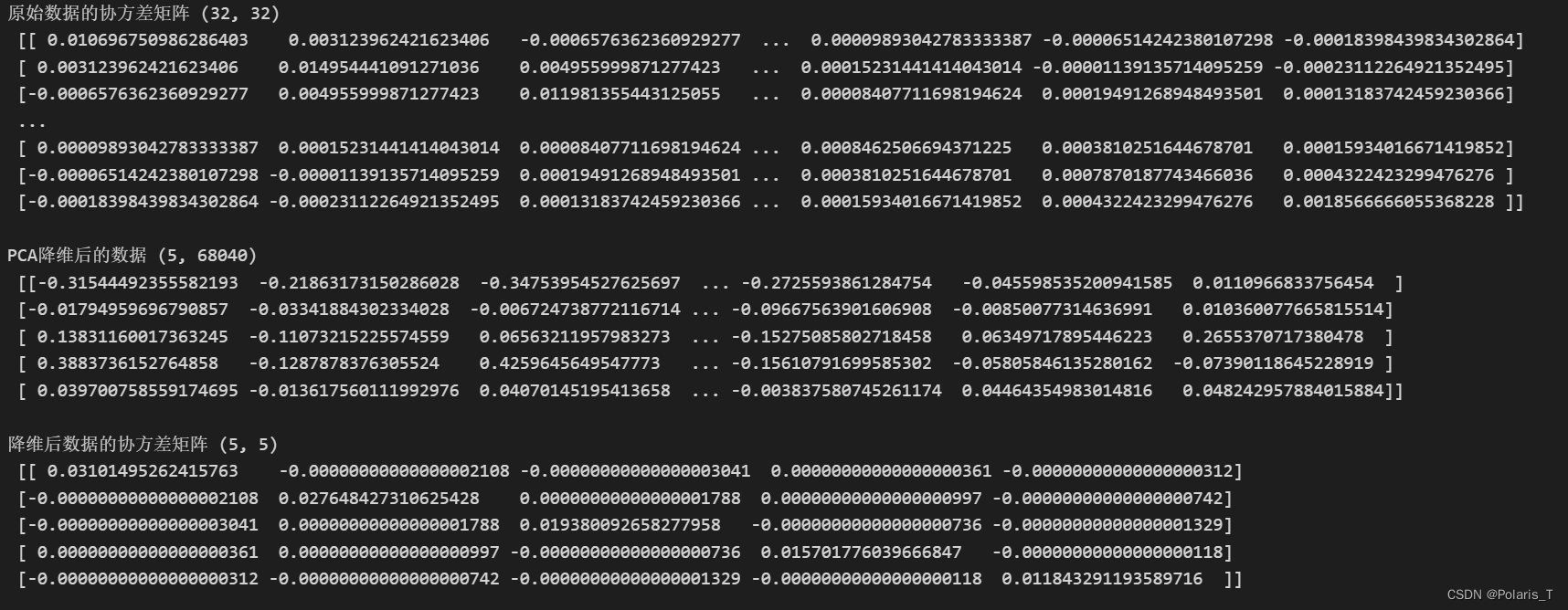
6.分析与总结
1. 观察结果并对比PCA前后的协方差矩阵,可以得出以下结论:原始数据各维度特征携带的信息各不相同,有的特征携带的信息较多,有的特征携带的信息较少(观察主对角线元素),并且不同的特征之间的协方差值并不为0,这说明原始数据各维之间存在一定的相关性,即存在信息冗余的问题。而采用PCA对原始数据进行降至5维的处理后,可以看到协方差矩阵 D D D的主对角线元素值从第一行开始逐行递减,这表示第1主成分携带的信息量最大,其余主成分依次减小。此外, D D D的非主对角线元素全为0,这说明各维之间已经完全两两正交,即相关性已经被完全消除了,这使得信息的存储冗余度得到了减小。
2. 在完成本次实验后,我尝试不使用np.linalg.eig()去求矩阵的特征值和特征向量,也就是先用 ∣ A − λ E ∣ = 0 |A-\lambda E|=0 ∣A−λE∣=0求出特征值,再用 ( A − λ E ) x = 0 (A-\lambda E)x=0 (A−λE)x=0求出特征值对应的特征向量。在这个过程中,我使用了Python的SymPy库去解特征方程和特征向量对应的线性方程组。一开始解特征向量速度还是很快的,但是一旦去解线性方程组,运算速度就变得非常慢,在加上这其中涉及到np.array和sympy的Matrix数据类型的相互转化和结果的规范化,我最终放弃了自编函数实现特征值和特征向量的求解,这也让我感受到了numpy的线性代数库的代码优化做的确实很好,numpy中很多运算的实现都比我们自己手写实现的要快得多。
















 120
120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











