






在后端开发中以及面试中,MySQL 一直非常重要的一个技术栈,熟练掌握 MySQL 非常有必要。
MySQL 中有一个重要的概念是索引,用几个问题引出接下来要文章
- 什么是索引?
索引时一种数据结构,协助快速查询和更新数据库表中的数据,有了索引,可以使我们的查询更加高效。 - 索引运用的什么数据结构?
索引的底层原理是 b+ 树。
一、索引底层数据结构为什么选用B+树,而不是hash,二叉树,红黑树或者平衡二叉树?
索引在选用底层数据结构时,考虑多方面的因素,接下来我们就讨论一下为什么使用 B+ 树,而不是其他的数据结构
1. Hash表 结构特点
哈希算法:也叫散列算法,就是把任意值(key)通过哈希函数变换为固定长度的 key 地址(或称为物理地址),通过这个地址作为 key,进行 key-value 键值对的存储
比如一条 SQL 语句
select * from table where id = 10
我们可以看到 id = 10,如果索引底层用的是 Hash ,那么哈希算法快速检索数据的计算过程,首先计算 id = 10 的数据物理地址 addr = hash(10) = 22222,而 22222 对应的物理地址假如是 0x222,那么这个0x222 是存储数据的物理地址,沟通这个地址,可以快速查找对应的数据。
在利用哈希算法的时候,有可能出现 hash碰撞 的问题,也就是说不同的 key 通过哈希函数处理之后可能得到了同一个物理地址,这样就会出现冲突,需要进一步解决。
对于单值查询的,利用 hash 来说,时间复杂度为 O(1),查询速度非常的快。但是我们在平时的开发中,对于查询不能说只进行单表查询,我们大多数会进行范围查询,如果进行范围查询,则hash 表就不好用了。
1.1 hash 不适合范围查询的原因
hash 表中存储的数据是不连续的,如果进行范围查询,需要把所有的数据,全部加载到内存,然后在内存里筛选出来目标范围内的数据。性能会大大下降
小结: 单值查询非常快,但是不适合范围查询,范围查询会严重影响效率。
2. 二叉查找树结构特点
为了解决 hash 表范围查询效率低的问题,我们考虑使用二叉查找树。

二叉查找树支持快速查询,时间复杂度为 O(logn)。比如我们要查询 id = 4 则只需要进行3次查询就可以了。
二叉查找树(从左到右升序),如果想找到 id > 5 的数据,只需要找到 节点6以及其右子树的数据即可,对于范围查找来说很容易实现。
普通二叉树的一大缺点:在极端的情况下二叉树有可能会退化成链表,时间复杂度为 O(n),性能急剧下降

我们在数据库中主键 id 一般都会设置成 自动增长 这种情况非常容易出现,一旦出现成链表的形式,对其访问的时间复杂度就会从 O(logn) 变成了 O(n)。如果一张表的数据是非庞大,那么就会导致性能急剧下降。
小结:二叉查找树查询效率高,而且解决 hash 表范围查找效率低的问题,但是有可能会退化成一条链,导致查询效率低的问题,所以不适合作为 MySQL 索引
3. 红黑树结构特点
二叉查找树有可能退化成链表的的不平衡特点,可以通过红黑树来解决,红黑树本身可以通过自动旋转和调整,从而保证二叉树的查找性能。最常见的是平衡二叉树和红黑树
红黑树可以自动调整树的结构,当二叉树不平衡时,通过调整结构,保持基本平衡,时间复杂度为 O(logn),查询效率不会降低

但是红黑树也有缺点,即“右倾”现象,虽然没有退化二叉那么的矿长,但是面对上万跳的数据,查询效率还是会很低

小结:红黑树查询效率与二叉查找树相似,极端退化情况比平衡二叉树好,但是还没有达到预期,所以不适合做 MySQL 的索引
4. 平衡二叉树结构特点
平衡二叉树特点:对任意一个节点来说,其左右子节点的深度差为0或1,这样就不会出现极端的情况。
4.1 平衡二叉树优点
- 查询效率高 O(logn),不存在极端的情况
- 可以进行范围查找和排序
平衡二叉树基本解决上上述各种数据结构的缺点与不足,但是为什么不选用平衡二叉树作为 MySQL 索引的数据结构?
主要是磁盘 IO 因素的影响。 如果使用平衡二叉树,没有给树节点,只存储一个数据,查询 id = 4 节点就需要进行三次比对节点,即进行三次磁盘的 IO,面对上万数据量的情况,磁盘的 IO 此时很高,消耗大量的时间。
因此,设计数据库索引的时候,还需要考虑怎尽可能减少磁盘的 IO 次数
5. B+ 结构特点
MySQL 中是使用 B+ 树作为索引的数据结构,那么我们这次就来详细说明一下为什么要使用 B+树。
- B+ 树:有序数组链表 + 平衡多叉树;
B+ 树的关键字(数据信息)全部存放在叶子节点中,非叶子节点用来做索引,而叶子节点之间形成的是通过指针连接,做出这双向链表的目的是为了 提高区间访问的性能。正式因为这个特点所以 B+ 树更适合用来索引的底层数据结构
B+ 树还有一个最大的好处,方面扫库,直接从叶子节点扫描一遍就完成
二、 接下来我们将引出页的概念

图片右边可以看到有一个 页10,这表示页号,最上边有 000 的字符,这表示普通记录,用来区别页类别,蓝色部分存的数据。
先说一下页中的几个部分
- record_type:记录头信息的一项属性,表示记录的类型。其中,0表示普通记录,2表示Infimum记录,3表示 Supremum 记录,1等会再说。
- next_record:记录头信息的一项属性,表示从当前记录的真实数据到下一条记录的真实数据的距离
在数据库一张表中如果数据量多的话将会分成多个页,并且这些页有一个特点:下一个数据页中记录的主键值必须大于上一页中用户记录的主键值
多张页所形成的样子如下图所示
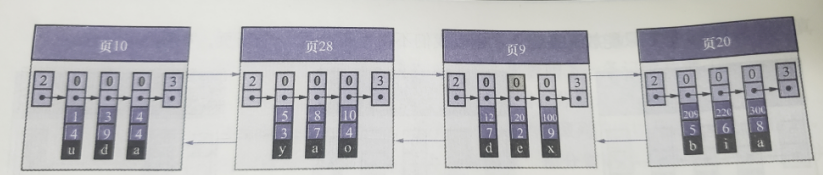
由于这些大小为 16K 的页在磁盘上可能并不是挨着的,如果想从这么多的野种根据主键值快速找到某些记录所在的位置,就需要给他们编制一个目录页,用来进行快速查找,每个目录项包括下面两个部分:
- 页的用户记录中最小的主键值,用 key 表示
- 页号,用 page_no 表示
所以我们为上面几个编制的目录如下如所示

以 页28 为例,它对应目录项 2,这个目录项中包含着页号 28以及该页中用户记录的最小主键值5。如果我们想查找主键值为 20 的记录,具体查找过程分为 2 步。
- 先从目录中根据二分法快速确定出主键在目录项 3 中(因为 12 < 20 < 209),它对应的页是页 9.
- 再根据前文讲的在页中查找记录的方式去 页9 中定位具体的记录。
至此,针对数据页编制的简易目录就搞定了。这个目录有一个别名,称为索引
我们可以发现目录项其实与用户记录长得很像,只不过目录相中的两个列是主键和页号而已。那么我们就再来说一下一开始说的 record_type 属性,它的各个取值代表的意思如下:
- 0:普通的用户记录
- 1:目录项记录
- 2:Infimum 记录
- Supremum 记录
原来这个值为 1 的 record_type 是这个意思。我们把前面使用道德目录项放到数据页中。

从上图中,可以看出,我们新分配了一个编号为30的页专门用来存储目录项记录。这里再次强调一下目录项和普通用户记录的不同点。
- 目录项记录 record_type 的值 1,普通用户记录的 record_type 的值是 0。
- 目录项记录只有主键和页的编号两个列,而普通用户记录的列是用户自己定义的,可能包含很多列。
现在我们再次查找主键为 20 的记录,大致拆分查找步骤
- 先到存储目录记录的页(也就是页 30)中通过二分法快速定位到对应的目录项记录,因为 12<20<209 ,所以定位到对应的用户记录所在的页就是页 9.
- 再到存储用户记录的页 9 根据二分快速定位到主键值为 20 的用户记录。
虽然说目录记录只存储主键值和对应的页号,比用户记录需要存储的空间小的多,但是毕竟一个页只有16KB的大小,能存放的记录还是有限的,如果数据量很多很多,一个目录页存不下怎么办?当然是再多整一个目录页。比如下图的样式

那么问题又来了,同样会产生很多的目录,我们怎么快速定位到一个存储目录记录的页呢?那我们就再为这些存储目录的目录页再生成一个更高级的目录,就像是一个多级目录一样,大目录嵌套小目录,小目路才是真实的数据,看下图

最终我们会形成这样的一棵树,称为 B+ 树,页面中内部的数据利用指针单向连接,页与页之间用双向链表的形式连接
从图中可以看出,B+树可以分成好多层,规定最下面的那层(也就是存放用户记录的那层)为第 0 层
最后我们来计算一下数据量,假设每个叶子节点最多可以存放100条用户记录,每个数据页可以存放1000条目录项
- 如果 B+ 树只有 1 层,也就是只有 1 个用于存放用户记录的的节点,最多能存放 100 条用户记录
- 如果 B+ 树有 2 层,最多能存放 1000 x 100 = 100,000 条用户记录
- 如果 B+ 树有 3 层,最多能存放 1000 x 1000 x 100 = 100,000,000 条用户记录
- 如果 B+ 树有 4 层,最多能存放 1000 x 1000 x 1000 x 100 = 100,000,000,000 条用户记录
可以看出 B+ 树的叶子节点其实是用页来代替,页与页之间使用双向链表进行连接的,页内数据用指针单项连接
有关MySQL索引内部存储基本上就是这样的,欢迎大家交流讨论















 202
202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









