







Intel于 2019 年 4 月发布了傲腾持久性内存(Optane DC persistent memory),这是目前市场上唯一商用的持久性内存(Pmem)存储设备。同时也在操作系统层面开发了一系列用于管理Pmem的工具,提供了丰富完备的文档。Pmem官方网站
但是Intel于2022年11月结束傲腾业务,但是承诺在已经卖出去的傲腾内存生命周期内,仍然维护PMDK。公告:PMDK 更新和我们的长期支持策略;另外,知乎上讨论Pmem的这个问题挺有意思:如何评价英特尔终止 Optane 持久内存业务?学术圈的研究是否还可持续?
就是虽然傲腾Pmem基本上已经算是寄了,但是对于新型的CXL扩展内存设备而言,在操作系统层面的支持与管理还是有参考价值。下面简单介绍一下傲腾Pmem及其可配置的两种访问模式:Memory mode(内存模式) 和 App Direct mode(应用直接访问模式)
文章目录
一、Pmem概述
持久性内存(persistent memory,Pmem)能够像磁盘一样持久地存储数据,具有接近 DRAM 的性能,同时还能提供远高于 DRAM 的存储密度。Pmem通过内存总线 与 CPU 互连,CPU 可以按字节粒度访问 Pmem。也就是说Pmem将传统外存的大容量持久存储与传统内存的低延迟字节寻址能力相结合。
经典的计算机存储器层次结构是由易失性内存(包括处理器缓存、DRAM 等)和持久性外存(包括机械磁盘、固态硬盘等)构成。
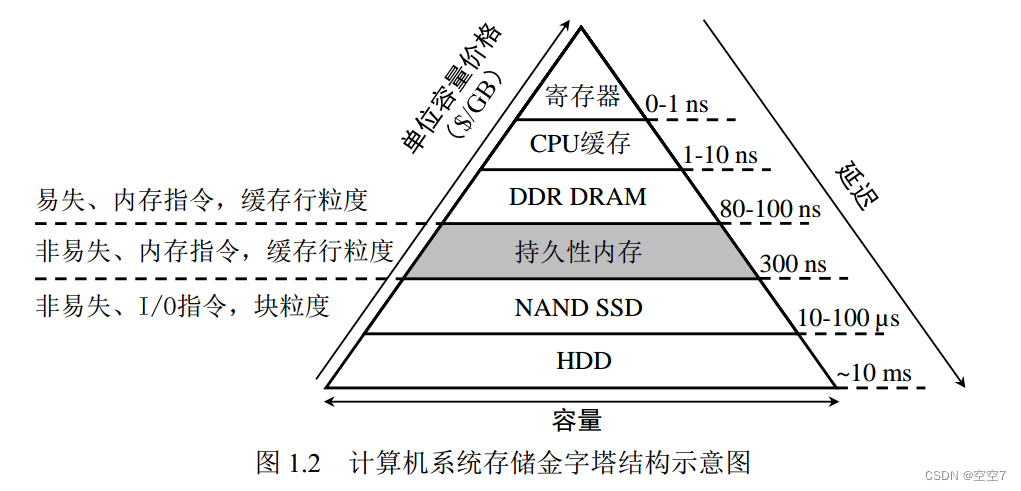
图引自:陈游旻. 持久性内存存储系统关键技术研究[D].清华大学,2021.DOI:10.27266/d.cnki.gqhau.2021.000070.
在如图1.2所示的存储金字塔中,存储层级越高,其距离处理器越近,容量越小、访问速度越高, 单位容量价格也就越贵。相变存储器(phase change memory,PCM)、3D XPoint等新型持久性内存的出现则打破了上述存储层级。持久性内存像 DRAM 一样通过内存总线与处理器直接相连,处理器可以通过内存指令按字节粒度访问持久性内存,且访问延迟与 DRAM 十分接近。另外,持久性内存还能像外存设备一样持久地存储数据,即使在系统掉电时数据也不会丢失。因此,持久性内存属于全新的一个存储层级。
-
在硬件层面:傲腾持久内存是NVDIMM-P的可商用实现,有关NVDIMM可见:【CXL】cxl-cli、ndctl、daxctl管理linux内核中NVDIMM设备子系统。其内部的持久化存储技术是3D XPoint技术,具体细节好像没有公开,不过可以在《持久内存架构与工程实践 (李志明等 著)》第二章找到一些有关如何持久化存储的相关内容。
-
在操作系统层面,其实这块有点乱,理了挺久,勉强有点眉目。商用的傲腾持久内存可配置两种访问模式:内存模式和App Direct模式。在App Dirdect模式下给Pmem部署文件系统后应该又可以将Pmem用作块存储(类似传统外存)和直接访问内存(类似传统内存)。现在学术界的大部分研究基本都是聚焦在App Direct模式,而工业界偏好内存模式。
-
而按照易失性用途和非易失性用途分类,内存模式属于易失性用途,同时还有一种变体,即将Pmem识别为一个无CPU的NUMA节点,也是易失性用途;App Direct模式下用户可以感知并控制Pmem的具体使用,所以可以当做大容量的易失性内存,也可以当做非易失性内存。
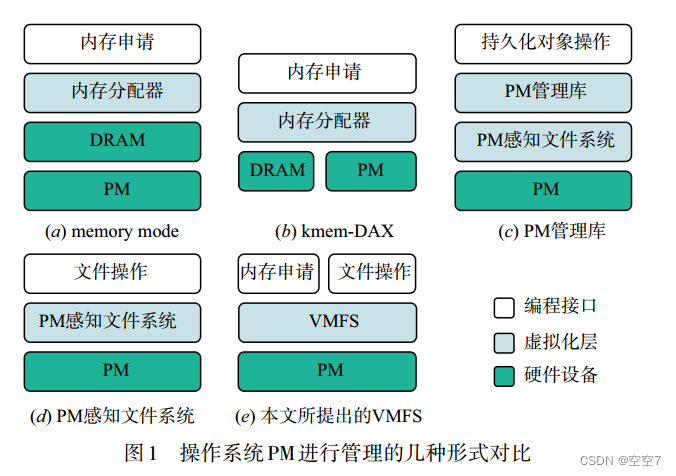
这是操作系统管理Pmem的模型图,后续进行说明。
图引自:张佳辰,胡泽瑞,赵盛,施文杰,王刚,刘晓光.VMFS:一种持久性内存统一管理系统[J].电子学报,2021,49(12):2299-2306.
二、内存模式
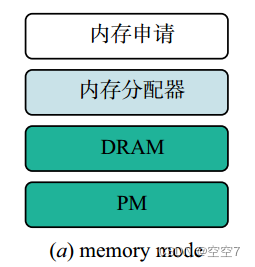
内存模式:DRAM是L4级cache,Pmem作为主存。系统有效内存容量是Pmem的大小。
该模式下DRAM无法直接访问,而是作为Pmem在直接映射缓存策略下的可写回缓存,Pmem作为大容量易失内存使用。在系统启动时Pmem会自动清空数据,确保其易失性语义。
-
DRAM作为缓存命中时,性能可以与DRAM相当;
-
但是不命中时,开销为DRAM的访问开销加上持久内存的访问开销。
其最大的优势是用户程序不需要经过任何修改可直接运行,应用没有移植成本。
但实际上也丢掉了Pmem的持久性。
三、将Pmem视为无CPU的NUMA node
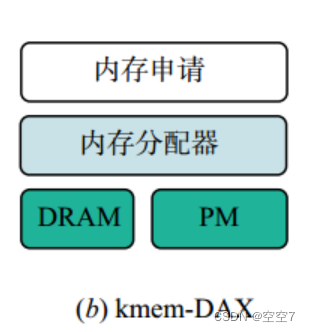
该模式被称为KMEM-DAX,是Linux内核5.1做的支持,系统会将Pmem识别为无CPU的NUMA node,用户可以同时看到DRAM和Pmem两个NUMA node,访问本地DRAM节点延迟较低,远端Pmem节点则延迟较高。用户可以通过numactl与libnuma将进程使用的内存分配/绑定到单独的node,或者选择交错使用等其他的NUMA策略。KMEM-DAX同样将Pmem作为易失性内存,可以看做是内存模式的补充。具体见:Allow persistent memory to be used like normal RAM
列举几个该模式的优点:
- 内存模式下系统可用内存容量=Pmem容量,DRAM的容量“丢失”了,而KMEM-DAX模式下系统可用内存容量=DRAM+Pmem容量
- 内存模式下低延迟的DRAM作为cache,而相对高延迟的Pmem作为主存,这不太灵活,对某些延迟敏感的应用而言可能会导致不期待的延迟表现。而KMEM-DAX模式下,应用可以指定内存分配策略,从而保证自己对延迟的特殊需要。即如果延迟敏感,那就绑定DRAM分配;反之可以绑定Pmem分配;而需要大容量时,可以指定优先DRAM分配,需要高带宽时,可以指定交错DRAM和Pmem分配。
- KMEM-DAX模式下DRAM和Pmem耦合度低,系统可用内存按照延迟自动分层,可以构建分层应用程序或云基础设施,对云厂商而言更灵活了。
其实我觉得KMEM-DAX完爆内存模式,不过可能因为Intel还是推傲腾Pmem那套管理软件的模式,以及学术界更关注Pmem持久性的利用,对KMEM-DAX的关注度不高。
四、应用直接访问模式(APP Direct)
App Direct 模式:持久内存作为可持久化的存储设备使用,该模式下持久内存和相邻的DRAM都会被识别为操作系统可见的内存设备,持久内存是与DRAM分离的持久化设备,DRAM则用作主存储器。
持久内存上部署文件系统后,其访问时间比常规存储设备(如SSD)的访问时间短得多。
其缺点是,用户需要使用相应的编程模型规范对持久内存进行应用程序的编程,会有代码修改的人力成本。
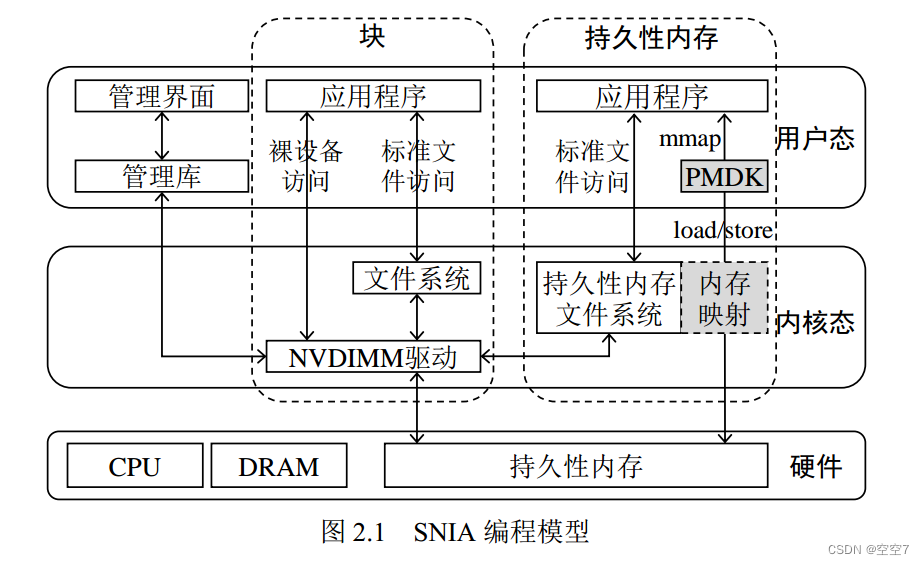
图引自:陈游旻. 持久性内存存储系统关键技术研究[D].清华大学,2021.DOI:10.27266/d.cnki.gqhau.2021.000070.
1. 持久内存用作块存储
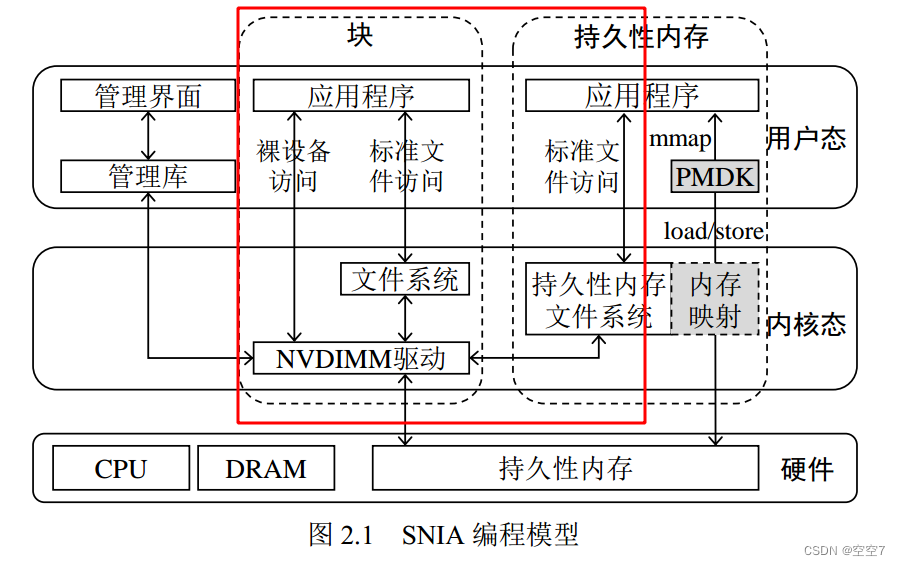
该访问方式包括红框所圈的三个途径:
Linux 4.3 及更高的版本已经默认支持 NVDIMM 驱动,该驱动可以将持久性内存以设备的形式呈现给用户(例如/dev/pmem0)。
- 最左边的访问线:应用程序可以直接打开上述设备,然后在裸设备上通过读写接口访问持久性内存空间;
- 左二的线:程序员亦可在该设备上部署传统文件系统,然后通过标准文件接口访问持久性内存空间。
值得注意的是,裸设备访问没有任何一致性保障,其存储的数据存在掉电丢失、不一致的风
险,而通过传统文件系统访问则要忍受额外的软件开销,性能损耗比较严重。 - 左三的线:在设备上部署支持持久内存感知的文件系统,包括Linux ext4和XFS,以及Windows NTFS等。可以以左二的线相同的方式,即标准文件API访问,如open、read、write等。
2. 持久内存直接访问(DAX机制)
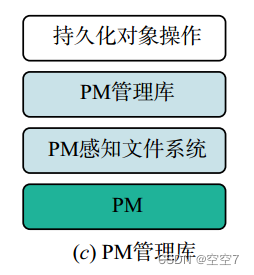
包括红框所圈的一个途径:
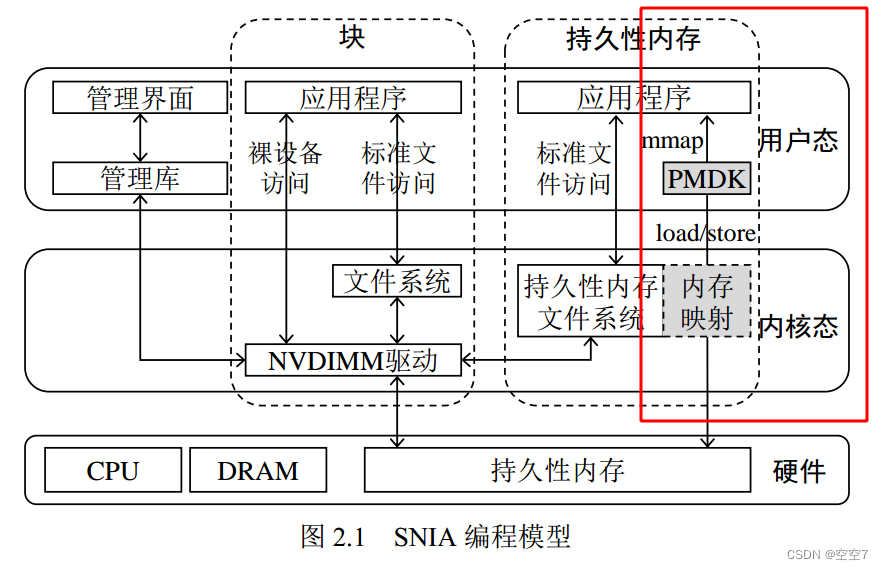
- 仍然需要在设备上部署支持持久内存感知的文件系统,然后以内存映射的方式将持久性内存空间导入到用户地址空间,并使用持久性内存编程库(例如英特尔提出的PMDK)对其进行管理。
该模式下,使用mmap进行内存映射,既能持久存储数据又能用作内存,同时重要的一点是,持久内存可以原生的映射成用户地址空间内存,无需在主存DRAM中缓存文件,这是持久内存DAX机制的功劳。(正常使用mmap映射外存文件实质上是在主存DRAM中占用了一定的物理地址空间来缓存外存的文件)
内存映射文件mmap机制
传统外存存储及网络设备均由操作系统统一接管,应用程序通过标准化系统调用接口陷入到内核访问硬件设备,操作系统则通过中断机制与外部设备进行交互。
用户空间和内核空间。为了保证内核的安全,现在的操作系统一般都强制用户进程不能直接操作内核(万一一不小心删除了操作系统的内存数据)。具体的实现方式基本都是由操作系统将虚拟地址空间划分为两部分,一部分为内核空间,另一部分为用户空间。
以32位linux操作系统为例,寻址空间位2^32=4GB,将最高的1G字节称为内核空间,将较低的3G字节供各个进程使用,称为用户空间。用户空间和内核空间的区别。
所有的系统资源管理都是在内核空间中完成的。比如读写外设磁盘文件,分配回收内存,从网络接口读写数据等等。应用程序是无法直接进行这样的操作的,应用程序只有通过系统调用(诸如read、write等)、软中断、硬中断进入内核态。
而mmap这个系统调用,可以将外设的内存映射到用户空间中,使得应用程序可以直接用指针读写映射的内存段,提高了效率。
讲解mmap系统调用比较透彻的几个博客文章:
深入剖析mmap原理 - 从三个关键问题说起
内存映射原理和内核是如何实现的,完全分析mmap原理
以及《深入理解计算机系统》一书中的9.8节
认真分析mmap:是什么 为什么 怎么用
mmap - 用户空间与内核空间
彻底理解mmap()
3. 傲腾持久性内存的命名空间
这部分就是与上面有点模糊的部分,命名空间这个概念是傲腾里自定义的,App Direct模式在四种命名空间中工作,相当于在操作系统中以四种方式工作,简述如下:
- fsdax:fsdax 命名空间中的傲腾持内存(FSDAX)是支持挂载有持久内存感知文件系统(也叫直接访问(Direct Access,DAX)功能的文件系统)的块设备。这种文件系统允许通过mmap建立到持久内存介质的直接映射,数据访问路径会绕过内核的page cache。基于文件I/O的应用程序可以通过该命名空间直接与傲腾持久内存进行数据交互。(这是傲腾Pmem的默认配置模式)
- devdax:devdax命名空间的傲腾持久内存(DEVDAX)是一个支持mmap直接映射的字符设备,用户进程可以像访问DRAM一样直接访问DEVDAX上的数据。但是文件系统不能挂载到DEVDAX上,DEVDAX中的内存地址是通过mmap分配给用户进程的。devdax 提供对 PMem 的更多原始访问,因此应用程序更容易保证大页面的对齐。这是应用程序使用 devdax 的最常见原因。(关于和fsdax的区别可以查看PMDK专业术语)
- sector:sector命名空间可以挂载传统的文件系统,也可以作为小型引导卷使用。
- raw:raw命名空间只是一个不支持直接访问的内存盘,这种命名空间不会对傲腾持久内存做任何处理,它不支持扇区数据原子性。由于诸多限制,非特殊情况不建议使用。
参考:张昊. 基于RDMA与持久性内存的用户态文件系统的研究与实现[D].华东师范大学,2022.DOI:10.27149/d.cnki.ghdsu.2022.003963.
另外有很多概念可以查看PMDK专业术语
五、易失性与非易失性使用
本节实际上介绍的是Pmem可以被用户看到作为独立于DRAM的内存设备的使用方式。
- 在内存模式下,Pmem和DRAM作为组合内存节点,用户并不能明确控制数据放置在哪里;
- KMEM-DAX模式下,Pmem和DRAM是两个单独的NUMA node,用户可以使用不同的NUMA策略放置数据,但是由于其针对DRAM设计,无法保持针对Pmem的持久编程模型(保证内存的一致性与持久性),只能将Pmem用于易失性内存使用;
- APP Direct模式下,用户同样可以感知到Pmem的存在,**Pmem作为挂载文件系统的fsdax设备或者不挂载文件系统的devdax字符设备暴露给应用。**同时硬件层面提供了CLWB等指令,软件层面有PMDK等较为方便的持久内存库帮助程序员进行持久内存编程。当用户拿到Pmem进行mmap之后的指针,可以决定是易失性的用途还是非易失性的用途。
下文也是只讨论KMEM-DAX和APP Direct两种Pmem可见情况下的使用。
1. Pmem的易失性使用
主要参考Intel的文档:持久内存的易失性使用
这种使用方式下,Intel建议用memkind库进行管理,该库是为异构内存管理开发的,所以可以管理Pmem或者未来其他不同内存种类,可以参考MEMKIND SUPPORT FOR HETEROGENEOUS MEMORY ATTRIBUTES以及INTRODUCTION TO LIBMEMKIND。主要有以下几种用法:
- memkind扩展了普通的malloc/free接口,添加了一个mem_kind参数,可以控制本次内存分配使用DRAM还是Pmem;
- memkind可以自定义不同的内存分配策略,可以设置不同内存种类的分配比例、优先级等,以实现异构内存管理或者分层内存管理;
- 对于KMEM-DAX模式,memkind也做了支持,按照上一点的用法,其定义了几种内存分配策略,用于实现类似NUMA策略的NUMA node内存分配方式。比如
MEMKIND_DAX_KMEM策略相当于将内存分配绑定到距离CPU最近的Pmem,其他具体见:MEMKIND SUPPORT FOR KMEM DAX OPTION
2. Pmem的非易失性使用
这种使用方式主要考虑Pmem的数据持久性问题,也就是应用拿到Pmem进行mmap之后的指针,就可以读写Pmem了,但是读写之后要手动调用持久化指令进行持久化,并且最后要进行持久指针的释放。
在传统存储系统中,易失性-持久性边界位于主存-外存之间;在持久性内存存储系统中,易失性-持久性边界位于处理器缓存-主存之间。存储系统的一致性要求数据原子性写入持久性存储介质中,即处理器缓存中的数据须原子性写回持久性内存。持久性内存的一致性开销主要分为顺序性和持久性两个方面。顺序性是指处理器数据需要按照数据依赖关系顺序写回持久性内存;持久性是指处理器数据从 L1、L2 等多级易失性缓存中替换到持久性内存。
其实引入持久内存之后系统有这样的变化:传统存储系统中,数据结构包括内存格式和磁盘格式两种格式。在数据的持久化过程中,数据结构从内存格式转换成磁盘格式后再写回外存。在持久性内存中,数据结构可以持久化于内存中,而无需进行格式转换。这就和传统的模式不同了,那么就要考虑如何安全的将数据持久化到Pmem里,虽然硬件上提供了CLWB等刷新缓存的高效指令,数据进入到持久域中即可持久化,但是缓存中的数据始终是易失的,所以需要数据的原子性写入,要么本次正常全部写入,要么就全部撤销。我目前了解有两种比较严重的情况:
- 如果不能保证原子性写入,那么数据写一半的时候断电了,那缓存中的数据丢失,导致Pmem中的数据不完整(错误);
- 如果出现内存泄漏,在DRAM中好说,直接重启系统即可释放全部易失性内存,而Pmem则不然,由于数据是持久化存在的,重启系统后数据仍然存在,无法对泄漏的内存进行回收,这个情况比较严重。
内存泄漏指的是使用指针之后没有free,导致这块内存一直是被占着的,其他程序无法使用。
所以持久内存编程其实不但依赖于软硬件对数据的原子更新,还依赖于程序员良好的习惯。所以Intel开发了PMDK来帮助程序员更方便安全的进行持久内存编程。
主要参考:
- AN INTRODUCTION TO PMEMOBJ (PART 1) - ACCESSING THE PERSISTENT MEMORY
- The Intel® Optane™ DC Persistent Memory Programming Model
- 舒继武,陆游游,张佳程,等.基于非易失性存储器的存储系统技术研究进展[J].科技导报, 2016.DOI:CNKI:SUN:KJDB.0.2016-14-019.
- Haris Volos, Andres Jaan Tack, and Michael M. Swift. 2011. Mnemosyne: lightweight persistent memory. SIGARCH Comput. Archit. News 39, 1 (March 2011), 91–104. https://doi.org/10.1145/1961295.1950379
- Memory persistency. https://doi.org/10.1145/2678373.2665712
五、针对Pmem的一些Benchmark
- membench
- 论文:Evaluating Performance Characteristics of the PMDK Persistent Memory Software Stack
- 代码链接:https://github.com/nicktehrany/membench
- 描述:提供了一个baseline,使用匿名mmap映射一段内存空间,测试带宽和读延迟。
- STREAM
- 论文:An Early Evaluation of Intel’s Optane DC Persistent Memory
- 代码链接:https://www.dropbox.com/sh/nzbmgthxpu5vgml/AAA5ga9KxXLC1QzeqbJ8rzlZa?dl=0
- 描述:Stream测试是内存测试中业界公认的内存带宽性能测试基准工具。论文中对STREAM进行了修改,得以运行在Pmem上。
- pmembench
- 论文:Building blocks for persistent memory
- 代码链接:https://github.com/alexandervanrenen/pmembench
- 描述:首先单独对pmem进行了带宽和延迟的测试,后面对dram和pmem混合使用进行了测试,另外还做了其他大量测试。
- PerMA-Bench
- 论文:PerMA-bench benchmarking persistent memory access
- 代码链接:https://github.com/hpides/perma-bench
- 描述:貌似包括numa的测试,较难修改,没有细看
- PMIdioBench
- 论文:Understanding the Idiosyncrasies of Real Persistent Memory
- 代码链接:https://github.com/padsys/PMIdioBench
- 描述:这个测试体量有点大,感觉gem5不能完成,并且需要DAX FS和两个numa节点以上
- pmem-olap
- 论文:Maximizing Persistent Memory Bandwidth Utilization for OLAP Workloads
- 代码链接:https://github.com/hpides/pmem-olap
- 描述:本文主要针对Pmem在OLAP(在线分析处理)中的作用,主要是将pmem在服务器上使用,体量也很大
六、傲腾Pmem对CXL的启发
- EXPLORING THE SOFTWARE ECOSYSTEM FOR CXL MEMORY
- MEMORY TIERING (PART 1)
- MEMORY TIERING (PART 2): WRITING TRANSPARENT TIERING SOLUTION
- DISAGGREGATED MEMORY - IN PURSUIT OF SCALE AND EFFICIENCY
- Peter Desnoyers, Ian Adams, Tyler Estro, Anshul Gandhi, Geoff Kuenning, Mike Mesnier, Carl Waldspurger, Avani Wildani, and Erez Zadok. 2023. Persistent Memory Research in the Post-Optane Era. In Proceedings of the 1st Workshop on Disruptive Memory Systems (DIMES '23). Association for Computing Machinery, New York, NY, USA, 23–30. https://doi.org/10.1145/3609308.3625268
七、CXL-SSD相关
CXL-SSD是指将CXL后端介质替换为SSD块存储设备,以求更大更廉价的内存容量扩展。这里想讨论的是其易失性内存和持久内存的使用方式。
这块三星和铠侠的研究走在前列,这里主要关注三星,其对CXL-SSD的使用方式做了四种举例,如下图所示。由于NAND介质微秒级的延迟无法忍受,所以一般的做法都是在NAND外面接一块DRAM作为NAND数据的缓冲或者说Cache。
其实主要关注前两种:
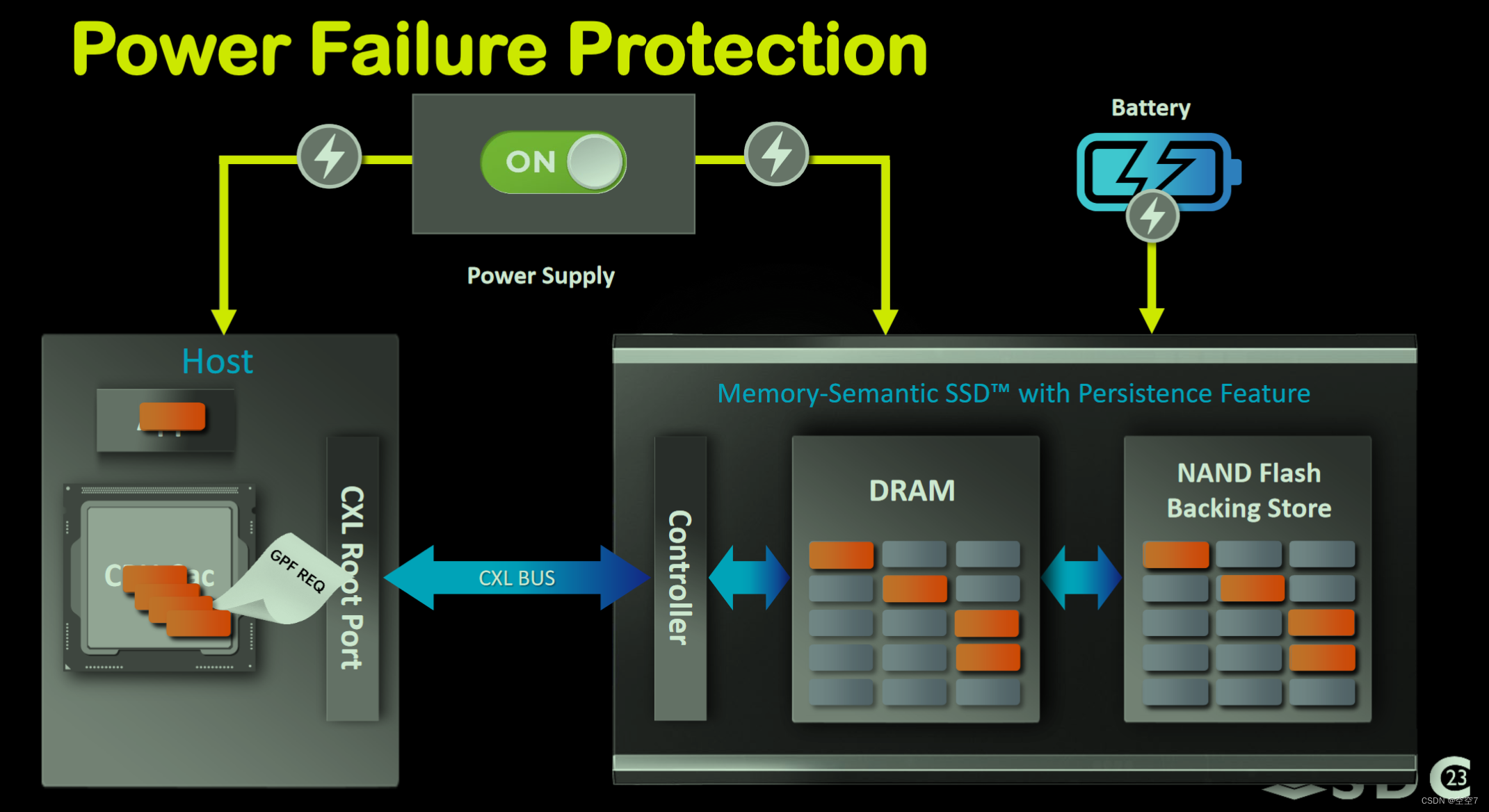
- Persistent Memory:将基于CXL的SSD作为持久性内存使用,将SSD的Cache(DRAM)通过cxl.mem协议作为设备内存空间进行暴露给应用,后端的NAND在系统关闭、重启或断电时用作数据备份存储。
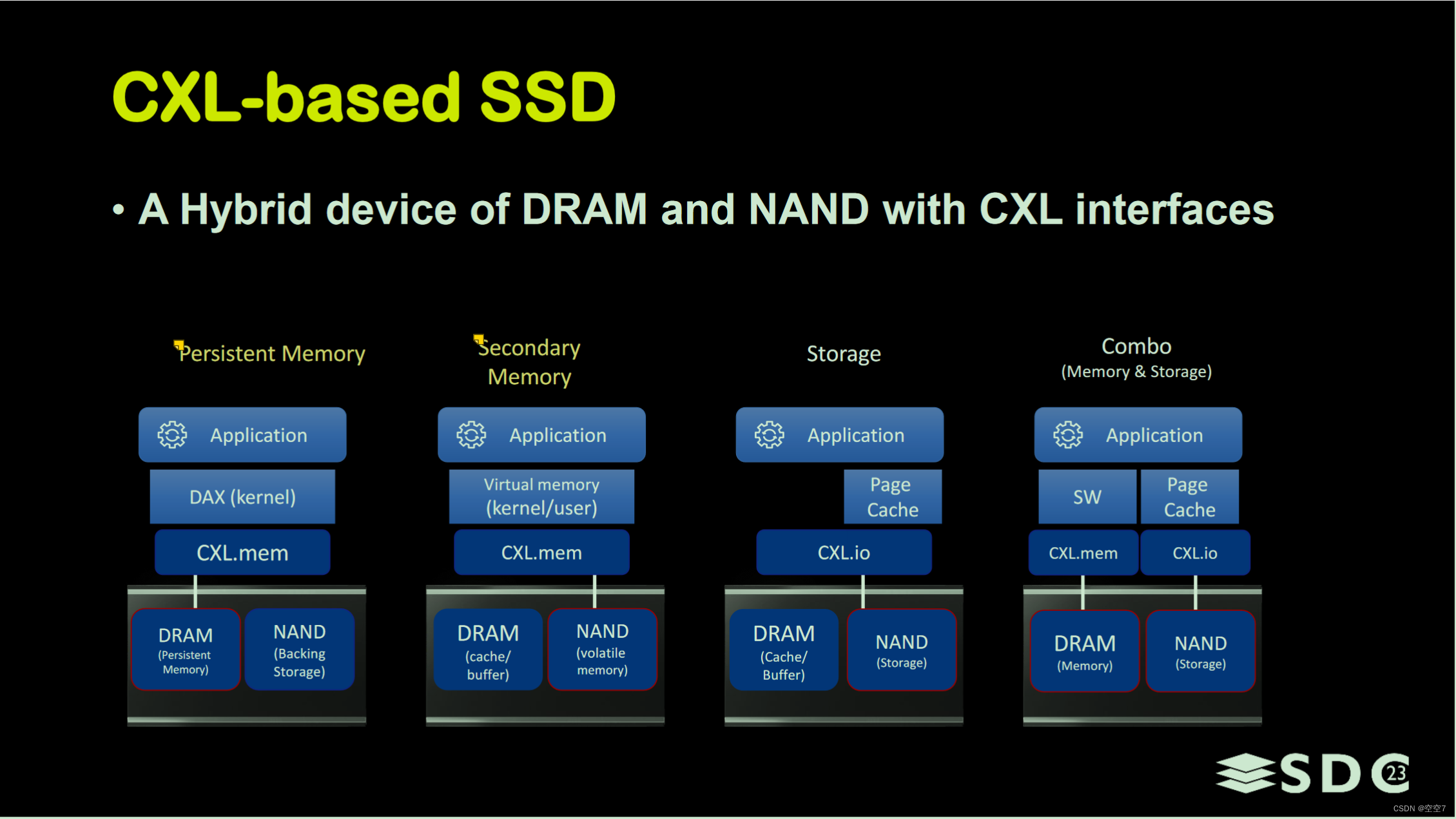
示意图如下,数据持久化借助CXL2.0提供的GPF(全局持久性刷新,Global Persistent Flush)功能。
- Secondary Memory:将基于CXL的SSD用作二级内存(易失性内存),将NAND空间通过cxl.m em展示为主设备内存,然后 DRAM空间用作NAND空间的高速缓存。这种方式就不考虑数据的持久化了,单纯的为了更大更廉价的内存扩展。
但是不管是将CXL-SSD视为易失性内存使用还是持久内存,都要面临下面三个问题:
- 内存语义到块语义的转换:这个说白了就是访问粒度不同,CXL.mem接口提供64B的内存语义(load/store指令)访问粒度,而SSD则一般是4KB或16KB的块语义访问粒度,将SSD接到CXL.mem后面存在一个粒度转换的问题。
- 延迟过高:DRAM是纳秒级的访问延迟,CPU很难忍受NAND介质微秒级的访问延迟。一般做法就是在CXL设备内部接个DRAM作为NAND的缓存。通过详细设计预取、替换等策略来想办法掩盖高延迟。
- NAND介质的寿命有限:这一块就需要考虑多种因素平衡的设计,来尽量让NAND磨损均衡。
现有的论文和工业界的产出如下:
- 三星的CMM-H模块:三星的Memory Module-DRAM被称为CMM-D,后端接DRAM;而Memory Module-Hybrid则是CMM-H,顾名思义就是混合的介质,支持易失性和持久性两种使用方式。
- SDC’23: Is SSD with CXL interfaces brilliantly stupid or stupidly brilliant?:三星有关CXL-SSD设计思路的演示
- 铠侠展示新款 CXL 协议存储产品,基于 XL-Flash 和传统闪存:资料较少。
- Myoungsoo Jung. 2022. Hello bytes, bye blocks: PCIe storage meets compute express link for memory expansion (CXL-SSD). In Proceedings of the 14th ACM Workshop on Hot Topics in Storage and File Systems (HotStorage '22). Association for Computing Machinery, New York, NY, USA, 45–51. https://doi.org/10.1145/3538643.3539745:韩国CAMEL实验室对CXL-SSD最早的研究,偏理论,考虑了持久性用途。
- Miryeong Kwon, Sangwon Lee, and Myoungsoo Jung. 2023. Cache in Hand: Expander-Driven CXL Prefetcher for Next Generation CXL-SSD. In Proceedings of the 15th ACM Workshop on Hot Topics in Storage and File Systems (HotStorage '23). Association for Computing Machinery, New York, NY, USA, 24–30. https://doi.org/10.1145/3599691.3603406:韩国CAMEL实验室对CXL-SSD第二篇研究,针对SSD Cache模块的预取策略设计,未考虑持久性,应该是只针对易失性使用。
- ATC’23: Overcoming the Memory Wall with CXL-Enabled SSDs:只考虑了易失性使用,通过SSD模拟器模拟了CXL-flash的设计实现。

















 4158
4158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









