









gem5模拟器的内存系统中,有三种不同的访存模式实现,分别有不同的功能与用途,本文对这三种模式做一个对比总结。三种模式的代码位置在
gem5\src\mem\protocol\下。
Atomic VS Timing
鉴于它们的用法呢,atomic和timing两种模式可以对比说明,functional在后面单独说明。
理解atomic模式与timing模式的要点有两个:
atomic模式下在内存系统中不会调度新的事件;timing模式会不断调度新的事件加入事件队列。atomic模式不会出现排队延迟或者资源争夺;而timing模式则会进行排队延迟和资源争夺的一个详细建模。
从gem5模拟器中的时间线上来看呢:
- atomic模式是当请求发起,立即就会得到一个return,return的是本次请求的一个估计时间
- 下面的timing模式,当请求发起后,会在内存系统中进行排队,延迟一段时间后得到响应。
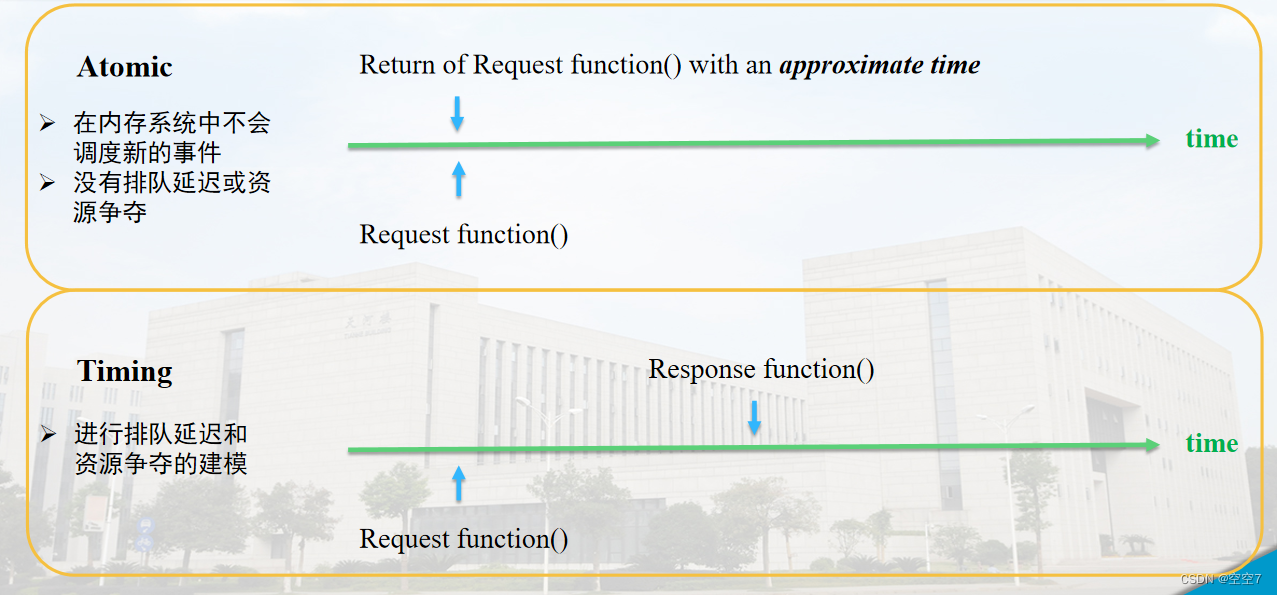
问题:atomic模式仅仅估计一个访存时间而不发生事件调度,为什么也能得到程序的正确结果?换句话说就是该模式下访存这个动作到底有没有发生,如果发生了为什么可以瞬间完成,如果没有发生为什么可以得到正确的结果?
要回答这个问题,那么需要理解gem5是一个事件驱动的模拟器,下面通过timing模式的事件调度进行解释:
一个事件包括动作和tick两部分,一个事件的调度意思就是在多少tick后发生什么动作。
timing模式的访存过程
观察这里的timing模式,上边的一条是访存链,packet就沿着访存链一步步传递;
下边的是事件队列,每调度一个事件就会插入事件队列,队列里面的事件是按照他们各自的tick严格排序的,gem5中的时间就随着一个个事件在他们约定好的tick发生,而一步步向前推进。
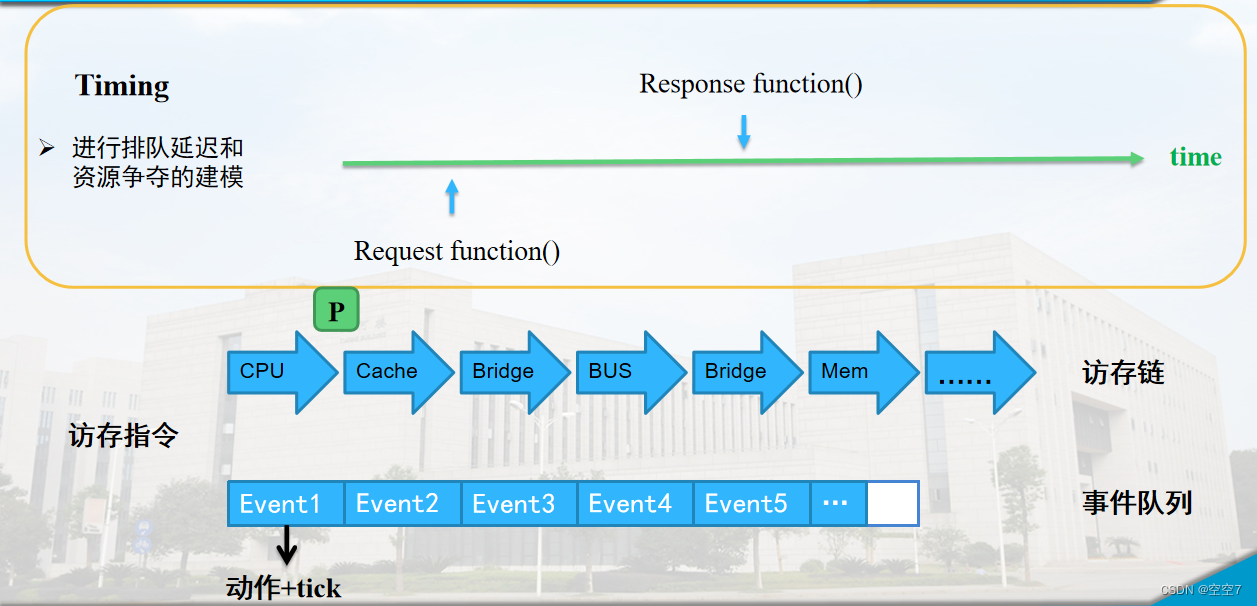
那么对于一条访存指令,CPU就会将一个请求包沿着访存链往下传递,传递过程中产生一个一个事件,完成访存过程中该完成的动作。
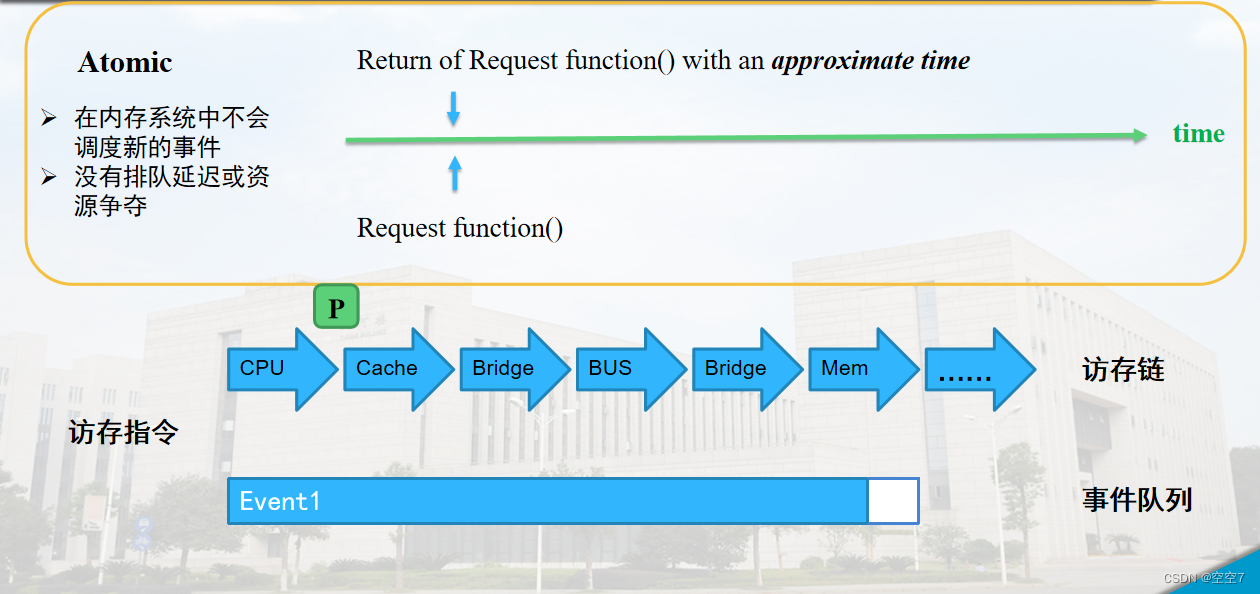
atomic模式的访存过程
观察atomic模式,对于一条访存指令,则可以看做事件队列里面只插入了一个事件,该事件的tick就是现在,当packet沿着访存链传递时,各种需要完成的操作还是会完成,但是不再调度新的事件加入队列。
那么当整个访存指令完成,后面却没有新的事件发生,也就是说gem5中的时间没有推进,看上去就好像瞬间完成了访存操作。所以将该模式成为原子访存。
atomic模式的作用与适用场景
- 写了一个程序,想要知道运行是否正确,可以使用该模式快速得到结果。后面再使用能得到更详细的结果的CPU模型或者说访存模式;
- 当本次模拟不关心访存时间,那么可以使用该模式快速得到结果;
- 用于cache的预热。
两种模式与CPU模型的关系
- 两种访存模式各自对应一种CPU模型,两种CPU都是单周期CPU,一个周期完成一条指令;
- 两种模式不能够共存。

Functional
functional模式,有以下特点:
- 官方介绍说他更适合被称做调式模式,这种模式没有对应的CPU模型;
- 因此是可以与atomic或timing共存于内存系统中的。
- 与Atomic相同,访存是瞬间发生的
- 用于加载二进制文件、检查/更改模拟系统中的变量以及允许远程调试器连接到模拟器等
也就是截图中的这个例子,这是python脚本构建完系统后,将一个编译好的二进制文件加载到系统中运行的操作。我理解就是用于gem5模拟系统和主机交互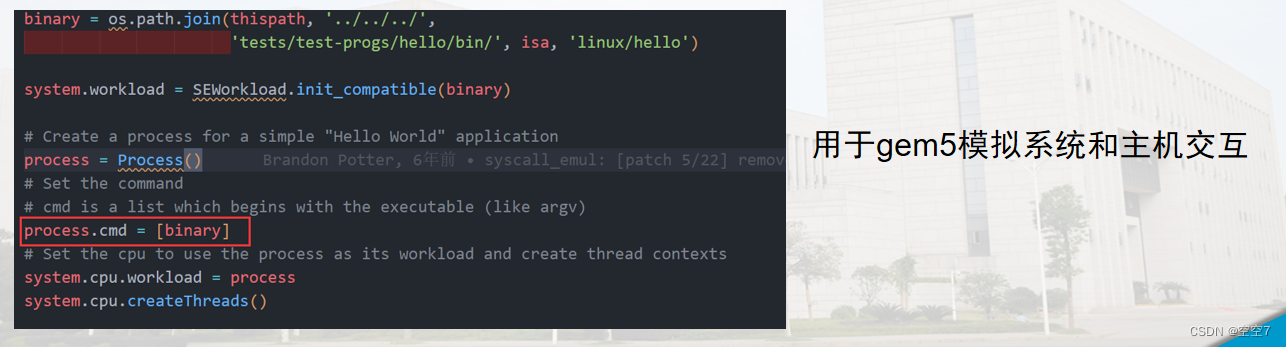
- 当设备接收到功能访问时,如果它包含一个数据包队列,则必须搜索所有数据包以查找功能访问正在影响的请求或响应,并且必须适当地更新它们。
也就是下图中在bridge对象中的recvFunctional(pkt)先后检查响应队列与请求队列中的每个数据包是否需要更新

functional模式目前用的貌似不多,暂时没有更深入的理解。














 2411
2411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









