






关于hadoop报错 MLlib reauires Numpy 1.4+
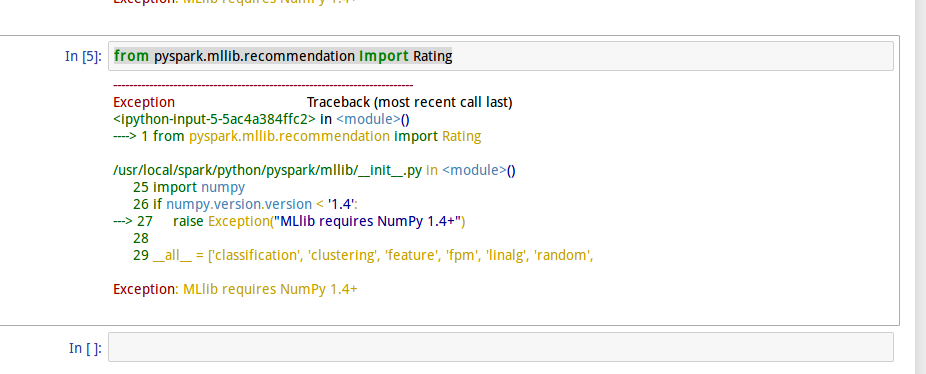
版本库更新了,所以我们需要手动更新一下初始化函数
这是官方的库 https://github.com/apache/spark/blob/master/python/pyspark/mllib/init.py
请将该代码替换你改路径下的__init__.py l里面的代码
替换为
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
"""
RDD-based machine learning APIs for Python (in maintenance mode).
The `pyspark.mllib` package is in maintenance mode as of the Spark 2.0.0 release to encourage
migration to the DataFrame-based APIs under the `pyspark.ml` package.
"""
# MLlib currently needs NumPy 1.4+, so complain if lower
import numpy
ver = [int(x) for x in numpy.version.version.split(".")[:2]]
if ver < [1, 4]:
raise RuntimeError("MLlib requires NumPy 1.4+")
__all__ = [
"classification",
"clustering",
"feature",
"fpm",
"linalg",
"random",
"recommendation",
"regression",
"stat",
"tree",
"util",
]














 1386
1386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









